6.5 Corrélation
6.5.1 Association de deux variables
Nous pouvons décrire une variable numérique à l’aide de plusieurs descripteurs comme la moyenne par exemple (nous venons de rencontrer la moyenne comme paramètre de la distribution normale, mais il s’agit également d’une grandeur que nous pouvons calculer sur nos données : on parle alors d’une statistique).
\[\bar{x}=\sum_{i=1}^n{\frac{x_i}{n}}\]
où \(x\) est une variable quantitative (donc numeric dans R) et \(n\) est la taille de l’échantillon, c’est à dire, le nombre d’individus mesurés. On notera \(\bar{x}\) la moyenne de \(x\), que l’on prononcera “x barre”. Nous avons abordé la différence entre un échantillon et une population dans la section 5.2. Soyez certain de maîtriser la différence avant de continuer de lire cette section.
Nous pouvons décrire l’étendue d’une variable numérique à l’aide de la variance qui, pour rappel, est la somme des écarts à la moyenne divisée par le nombre de degrés de liberté (n dans le cas d’une population et n - 1 dans le cas d’un échantillon).
\[var_x = S^2_x = \frac{\sum_{i = 1}^n (x_i - \bar{x})^2}{n-1}\]
L’écart type, noté \(\sigma\) dans le cas d’une population et \(S\) dans le cas d’un échantillon, est la racine carrée de la variance. C’est une autre mesure de la dispersion d’une variable numérique. Donc :
\[S_x = \sqrt{S^2_x}\]
Plus la variance est élevée, plus les observations sont dispersées autour de la moyenne. Lorsque nous avons affaire à deux variables numériques, une représentation de l’une par rapport à l’autre se fait naturellement à l’aide d’un graphique en nuage de points. Voici trois situations fictives différentes (y1, y2 et y3 en fonction de x) :
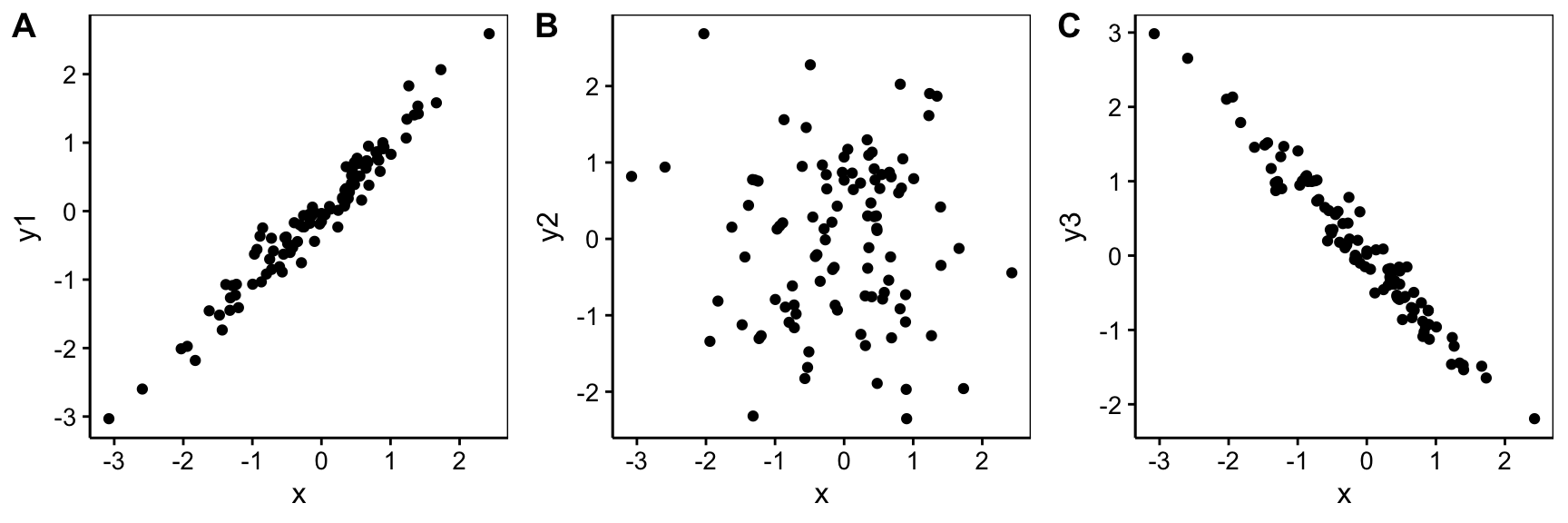
Nous pouvons observer que la forme du nuage de points diffère entre ces trois situations. Le graphique A est allongé le long d’une oblique. Cela signifie que, lorsque des valeurs de x sont faibles, les valeurs de y1 sont faibles aussi. Lorsque les valeurs de x sont élevées, celles de y1 tendent à l’être également. Nous avons plutôt une proportionnalité entre les valeurs observées pour x et pour y1. Dans le graphique C de droite, c’est l’inverse. Nous avons une proportionnalité inverse entre x et y3. Dans le graphique B du centre, le nuage de point ne s’étire pas dans une direction oblique particulière. Nous dirons ici qu’il n’y a pas d’association entre x et y2. Ce type d’association entre deux variables numérique est un élément important dans notre analyse, car un nuage de points qui s’allonge le long d’une direction oblique sur le graphique est signe d’un mécanisme sous-jacent responsable de cette association (mais attention à ne pas conclure directement à un mécanisme de cause à effet direct, voir plus loin). Il serait donc souhaitable de pouvoir quantifier le degré d’une telle association.
Nous pouvons définir la covariance comme étant une mesure de la variance dans le même sens pour toutes les paires de valeurs observées entre nos deux variables numériques. Elle se définit de manière très similaire à la variance, mais fait naturellement intervenir simultanément les observations de x et y, ainsi que leurs moyennes respectives :
\[cov_{x,y} = \frac{\sum_{i = 1}^n (x_i - \bar{x}) \cdot (y_i - \bar{y})}{n-1}\]
Voyons ce que cela donne dans notre exemple fictif contenu dans un data frame nommé df :
# [1] 0.9336631# [1] 0.004064163# [1] -0.9230542La covariance (fonction cov() dans R) quantifie effectivement l’association entre les deux variables x et y. Nous avons une valeur positive entre x et y1, faible et se rapprochant de zéro entre x et y2, et négative pour x et y3 d’une proportionnalité inverse. Cette mesure n’est cependant pas normée, c’est-à-dire qu’elle peut varier vers des valeurs très grandes ou très petites en fonction des données. Donc, pour une même forme de nuage de points, la valeur dépendra, par exemple, des unités de mesure choisies. Si je transforme les données de mon jeu fictif df en les multipliant par dix pour simuler un changement d’unité dans df2, j’obtiens :
# [1] 93.36631# [1] 0.4064163# [1] -92.30542C’est embêtant, puisque la forme du nuage de points n’a, lui, pas changé du tout.
À vous de jouer !
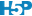
Le coefficient de corrélation de Pearson, noté r, est une autre mesure qui est normée de telle façon qu’il prenne la valeur +1 pour une proportionnalité directe parfaite (les points sont strictement alignés le long d’une droite) et -1 lorsque la proportionnalité est inverse parfaite (et toujours 0 en cas de non-association).
\[cor_{x,y} = r_{x,y} = \frac{cov_{x,y}}{\sqrt{S^2_x \cdot S^2_y}} = \frac{cov_{x,y}}{\sqrt{S^2_x} \cdot \sqrt{S^2_y}} = \frac{cov_{x,y}}{S_x \cdot S_y}\]
C’est grâce à la division par le produit des écarts types de x et y que nous arrivons à normer correctement le coefficient. Celui-ci peut se calculer à l’aide de la fonction cor() dans R. Cela donne :
# [1] 0.9781819# [1] 0.9781819# [1] 0.003939552# [1] 0.003939552# [1] -0.979511# [1] -0.979511Cette fois-ci, nous obtenons la même valeur pour r que le calcul se fasse à partir de df ou de df2. De plus les valeurs absolues très proches de 1 (0,978 dans le cas A et 0,980 dans le cas C) suggèrent que la proportionnalité est très forte. C’est effectivement ce que nous observons sur les graphiques.
À vous de jouer !
Faites attention à deux points importants.
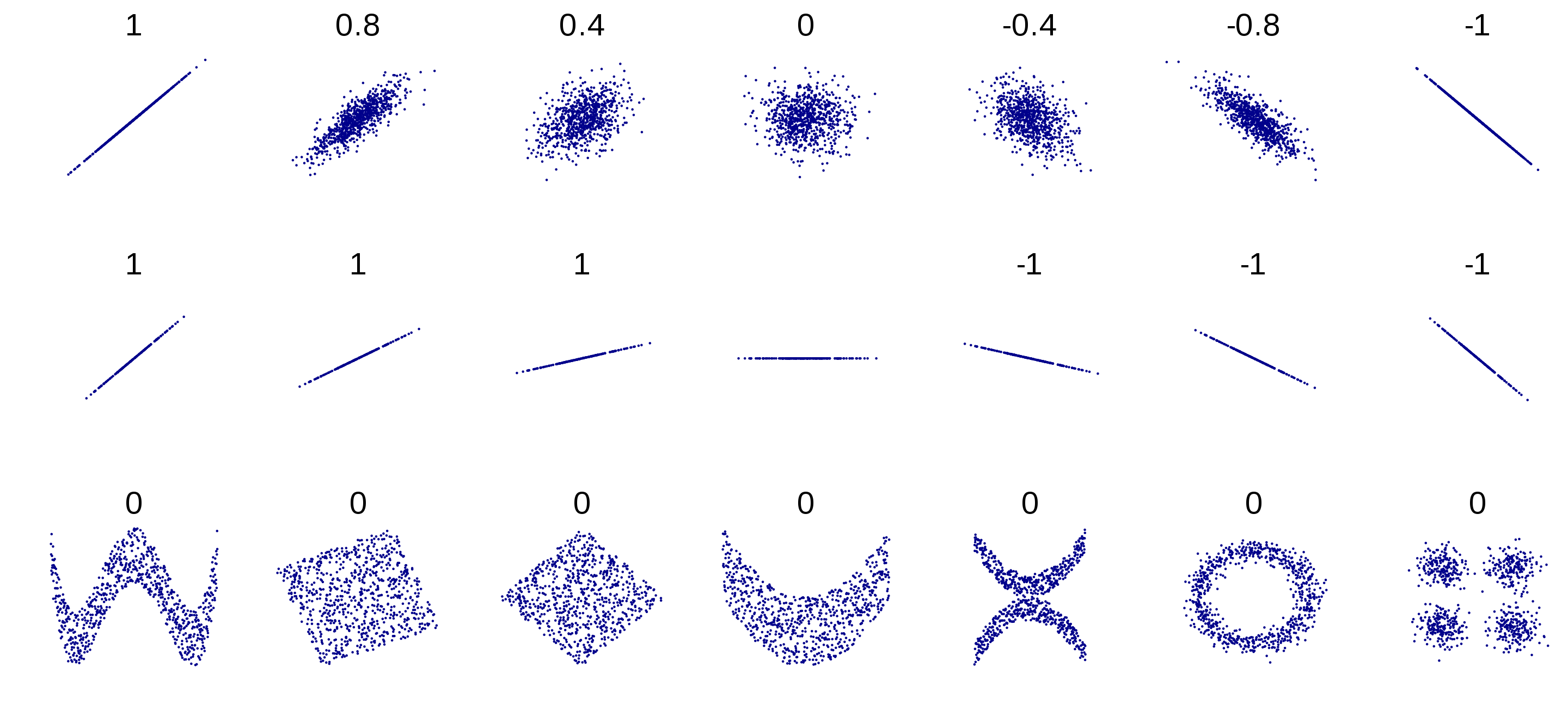
- Le coefficient de corrélation de Pearson mesure une association linéaire entre deux variables numériques. La figure suivante montre quelques nuages de points et les valeurs de r associées.
- L’existence d’une corrélation n’implique pas forcément que la variation d’une des deux variables est le résultat de la variation de l’autre (cause à effet). Il se peut, par exemple, qu’il y ait une troisième variable non prise en compte qui soit à l’origine de la variation, directement ou indirectement des deux autres. Une variable particulièrement pernicieuse de ce point de vue est le temps. À peu près tout ce qu’on étudie en biologie est variable dans le temps. Et donc, bien souvent, il existe des corrélations entre des variables qui n’ont rien à voir l’une avec l’autre lorsqu’elles sont toutes deux mesurées à différents moments, ce qu’on appelle des séries temporelles ou chronologiques. La vidéo suivante apporte d’autres éclaircissements sur ce sujet, sur base d’un exemple tiré de la littérature scientifique.
L’association entre deux variables numériques peut ainsi s’envisager selon trois niveaux impliquant des hypothèses de plus en plus fortes quant aux mécanismes responsables de cette association :
La corrélation. Ici les deux variables numériques sont sur le même pied d’égalité. Nous nous bornons à observer l’association sans élaborer plus d’explication sur son existence. C’est le coefficient de corrélation qui la quantifie.
La relation. Ici, nous modélisons l’association, par exemple par une droite, dite droite de régression. Nous verrons cet outil très important des statistiques et de la science des données dans la partie modélisation du cours de Science des Données biologiques II. Dans ce cas, nous considérons qu’un mécanisme sous-jacent est responsable de la forme du nuage de points, et nous considérons qu’une fonction mathématique peut être utilisée pour prédire les valeurs d’une variable connaissant celles de l’autre.
La causalité. En plus de la relation, nous considérons que c’est la variation d’une des deux variables qui est à l’origine, directement ou indirectement de la variation de l’autre. Une relation de cause à effet ne peut être démontrée de manière sûre que par l’expérience, comme expliqué dans la vidéo plus haut.
6.5.1.1 Matrice de corrélation
Dans un cas multivarié (plus de deux variables), nous pouvons toujours étudier les associations entre variables numériques à l’aide de r à condition de calculer ces descripteurs statistiques pour tous les couples de variables considérées deux à deux. Pour N variables, nous rassemblerons tous ces calculs dans une matrice carrée N par N qui croise tous les cas deux à deux possibles dans un même tableau.
Prenons un exemple à trois variables. Le jeu de données trees rassemble la mesure du diamètre, de la hauteur et du volume de bois de cerisiers noirs. La matrice de corrélation peut se calculer à l’aide de cor() dans R, ou mieux, à l’aide de correlation() dans SciViews::R.
Diamètre à 1,4m [m] | Hauteur [m] | Volume de bois [m^3] |
|---|---|---|
0.211 | 21.3 | 0.292 |
0.218 | 19.8 | 0.292 |
0.224 | 19.2 | 0.289 |
0.267 | 21.9 | 0.464 |
0.272 | 24.7 | 0.532 |
... | ... | ... |
0.444 | 25.0 | 1.577 |
0.455 | 24.4 | 1.651 |
0.457 | 24.4 | 1.458 |
0.457 | 24.4 | 1.444 |
0.523 | 26.5 | 2.180 |
Premières et dernières 5 lignes d'un total de 31 | ||
Matrice de coefficients de corrélation de Pearson r | |||
|---|---|---|---|
| diameter | height | volume |
diameter | 1.000 | 0.519 | 0.967 |
height | 0.519 | 1.000 | 0.597 |
volume | 0.967 | 0.597 | 1.000 |
Vous noterez que :
- Les éléments sur la diagonale de la matrice de corrélation valent toujours 1. En effet, il s’agit de la corrélation d’une variable en fonction d’elle-même, or
\[r_{x,x} = 1\]
- Le triangle inférieur et le triangle supérieur (de part et d’autre de la diagonale) sont identiques, ou si vous préférez, sont comme le reflet dans un miroir l’un de l’autre. C’est parce que le coefficient de corrélation de x et y est toujours le même que celui de y et x.
\[r_{x,y} = r_{y,x}\]
Pour ces raisons seul le triangle inférieur (ou supérieur) est informatif. Le reste (diagonale et autre triangle) est trivial ou répétitif. Vous trouverez parfois une représentation de la matrice de confusion sous la forme uniquement du triangle inférieur. La méthode summary() effectue une telle représentation, et simplifie encore la représentation pour aider à trouver les corrélations importantes dans un gros tableau.
# Matrix of Pearson's product-moment correlation:
# (calculation uses everything)
# d h v
# diameter 1
# height . 1
# volume B . 1
# attr(,"legend")
# [1] 0 ' ' 0.3 '.' 0.6 ',' 0.8 '+' 0.9 '*' 0.95 'B' 1Voyez la page d’aide de correlation() pour plus d’information via ?correlation. Vous pouvez passer un data frame à la fonction, ou encore, utiliser correlation(data = df, ~ var1 + var2 + var3) avec une formule pour spécifier les variables à traiter. L’argument use = permet de spécifier quoi faire en cas de valeurs manquantes. Si vous indiquez "complete.obs", toute ligne du tableau contenant au moins une valeur manquante sera éliminée avant le calcul. Avec "pairwise.complete.obs" les éliminations de valeurs manquantes se font pour chaque paire de variables individuellement des autres.
Il existe aussi des représentations graphiques spécialisées, appelées corrélogrammes pour visualiser les coefficients de corrélations dans un cas multivarié. La fonction plot() appliquée à notre objet Correlation en offre une version simple.
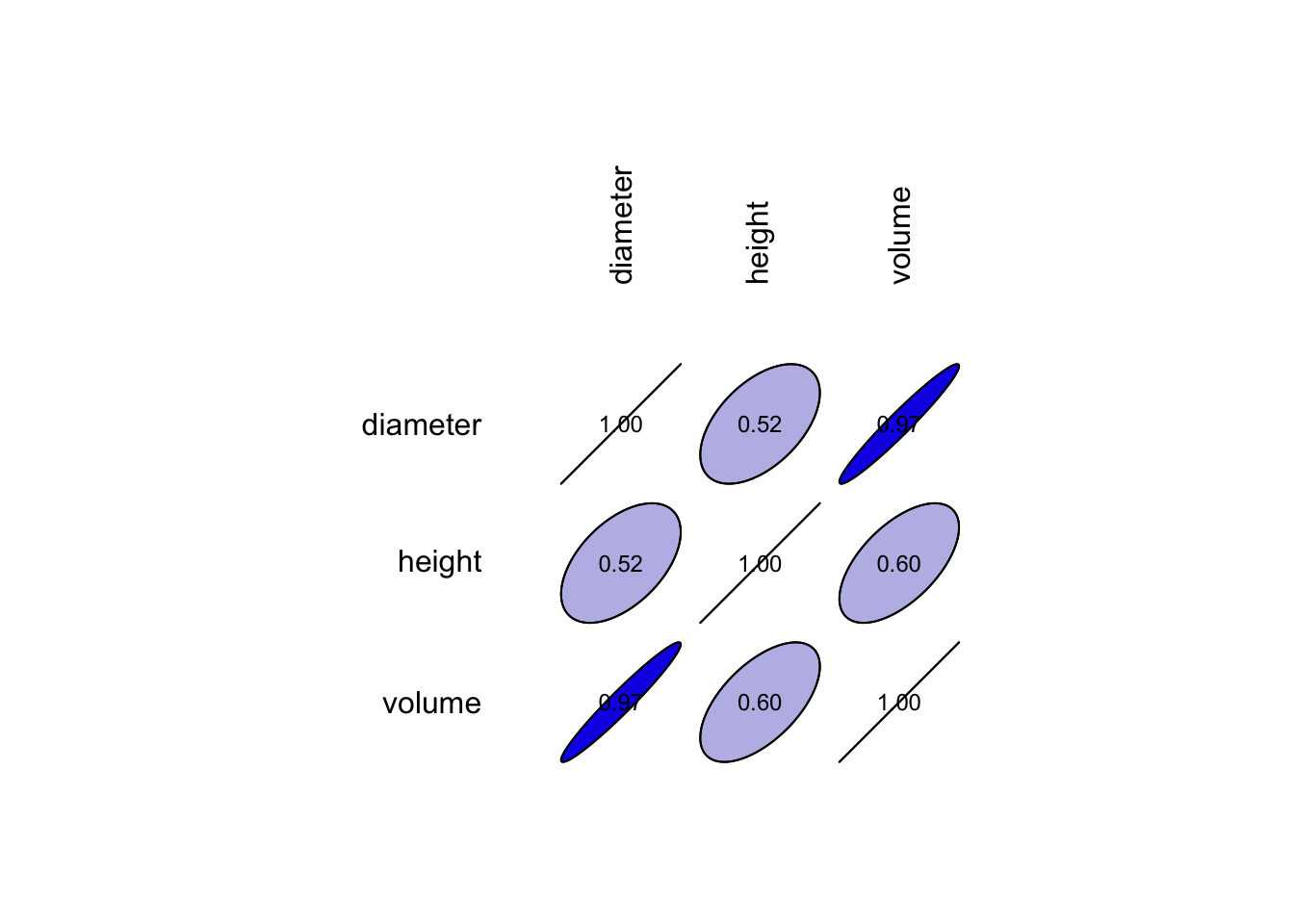
La matrice est représentée par des ellipses de plus en plus allongées au fur et à mesure que r se rapproche de 1. Une couleur bleue est utilisée pour les corrélations positives et une couleur rouge pour les corrélations négatives (mais vous pouvez aussi choisir d’autres couleurs). Ici, toutes les corrélations sont positives. Sur le jeu de données zooplancton, nous pouvons réaliser un corrélogramme plus intéressant qui illustre mieux la diversité de cette représentation graphique. Considérons, à titre d’exemple, les variables contiguës size jusqu’à density (que l’on peut indiquer par size:density dans un sselect()) :
zoo <- read("zooplankton", package = "data.io")
zoo %>.%
sselect(., size:density) %>.%
correlation(.) ->
zoo_cor
plot(zoo_cor)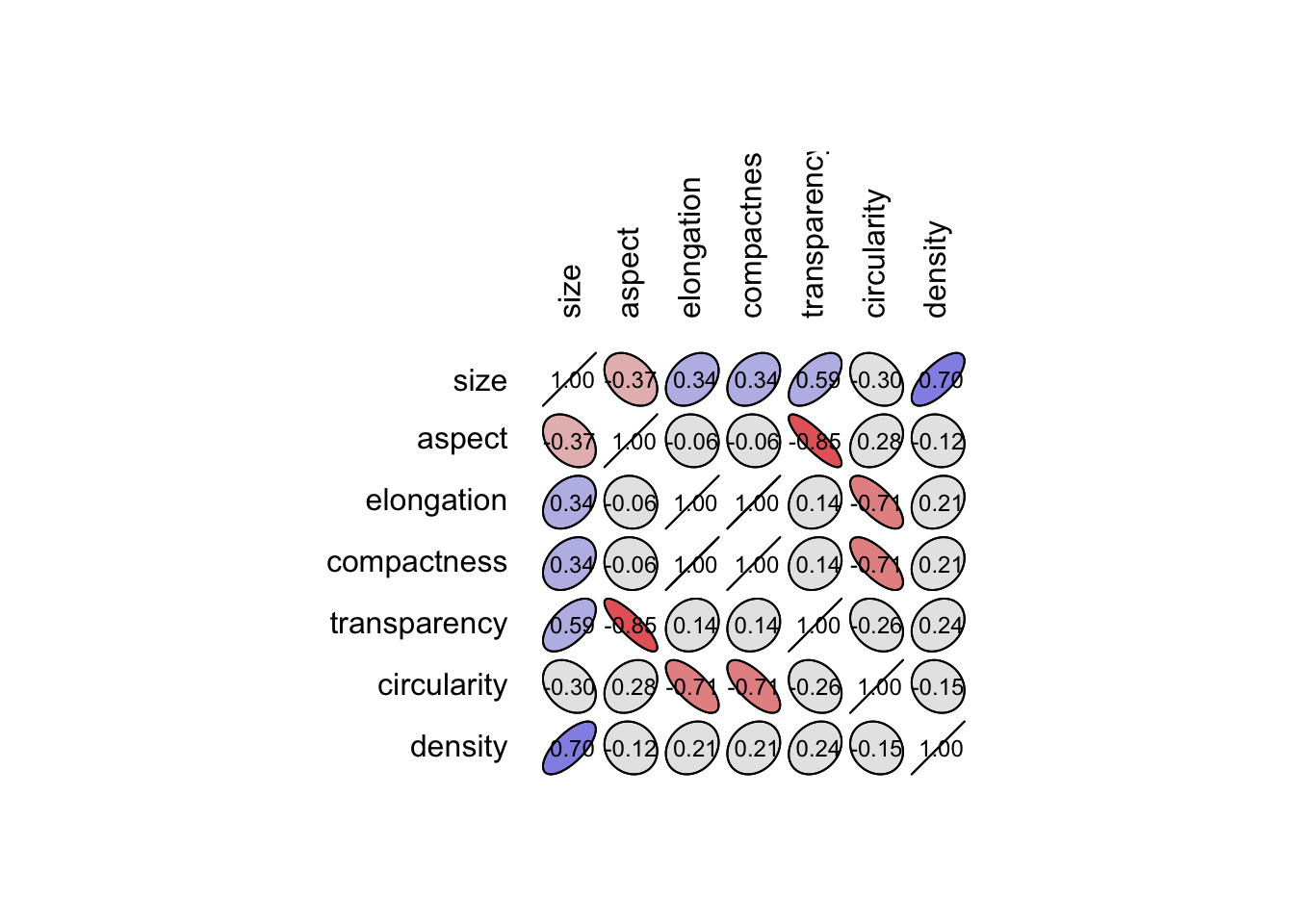
Vous noterez que les variables elongation et compactness sont redondantes (r = 1). De plus, les données le long de la diagonale et sur le triangle supérieur n’apportent rien. Nous pouvons aussi bien décider de ne représenter que le triangle inférieur sur notre corrélogramme en ajoutant un argument type = "lower".
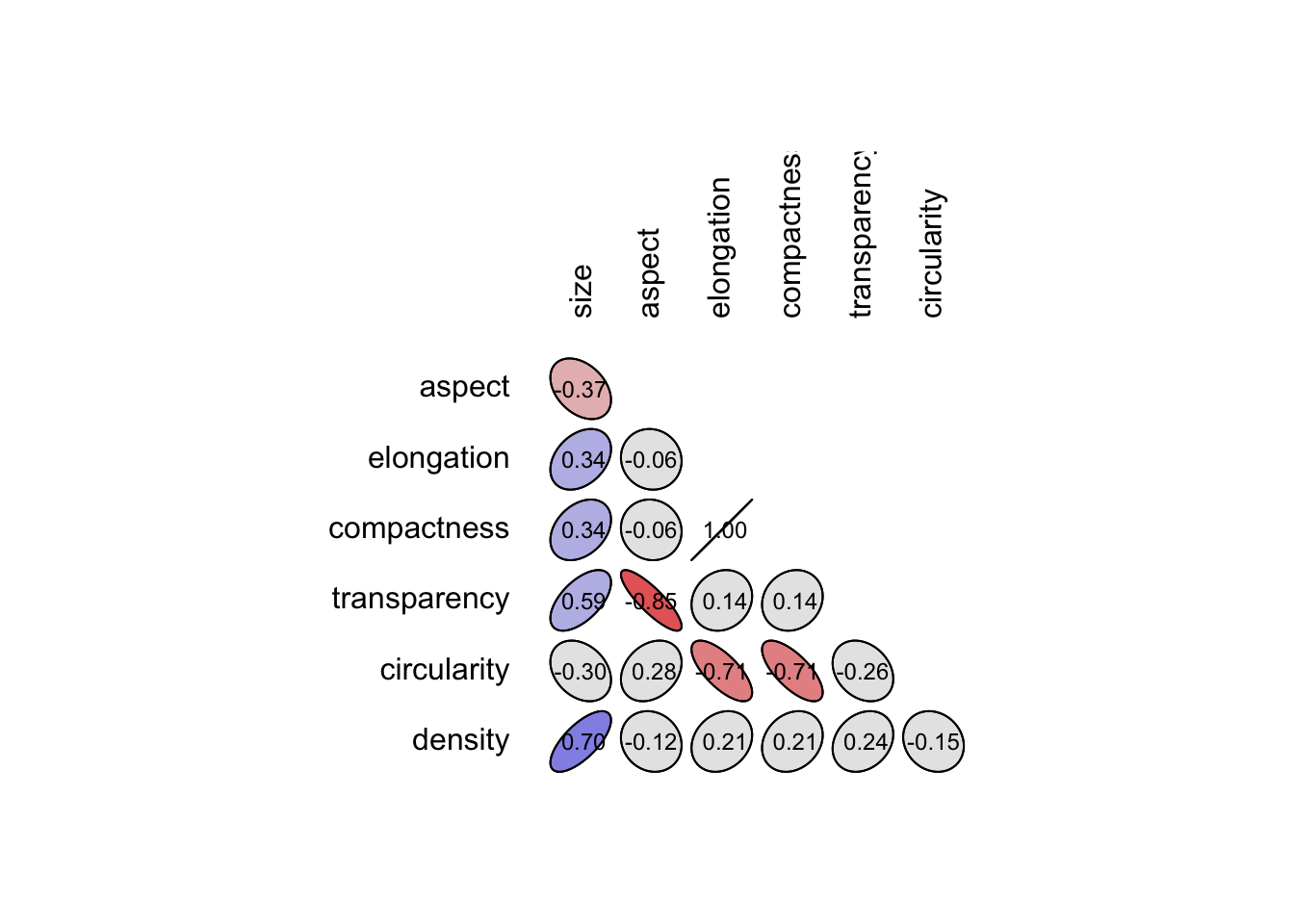
6.5.1.2 Importance des graphiques
Faites bien attention avec le coefficient de corrélation, la matrice de corrélation et le corrélogramme, car des formes de nuages de points complexes peuvent se solder par des valeurs peu indicatives !
Un jeu de données artificiel appelé “quartet d’Anscombe” montre très bien comment des données très différentes peuvent avoir même moyenne, même variance et même coefficient de corrélation. Ce n’est qu’avec un graphique en nuage de points (ou matrice de nuages de points, voir plus loin) qu’il est possible de détecter le problème.
# x1 x2 x3 x4 y1 y2 y3 y4
# <num> <num> <num> <num> <num> <num> <num> <num>
# 1: 10 10 10 8 8.04 9.14 7.46 6.58
# 2: 8 8 8 8 6.95 8.14 6.77 5.76
# 3: 13 13 13 8 7.58 8.74 12.74 7.71
# 4: 9 9 9 8 8.81 8.77 7.11 8.84
# 5: 11 11 11 8 8.33 9.26 7.81 8.47
# 6: 14 14 14 8 9.96 8.10 8.84 7.04Séparons les quatre variables x d’un côté et les quatre variables y de l’autre.
Que valent les moyennes, les variances, les écarts-types pour les quatre variables x ?
# x1 x2 x3 x4
# 9 9 9 9# x1 x2 x3 x4
# 11 11 11 11# x1 x2 x3 x4
# 3.316625 3.316625 3.316625 3.316625Nous voyons que les quatre variables ont identiquement la même moyenne, la même variance et le même écart-type.
Que valent les moyennes, les variances, les écarts-types pour les quatre variables y ?
# y1 y2 y3 y4
# 7.500909 7.500909 7.500000 7.500909# y1 y2 y3 y4
# 4.127269 4.127629 4.122620 4.123249# y1 y2 y3 y4
# 2.031568 2.031657 2.030424 2.030579À nouveau, c’est les mêmes valeurs pour les quatre séries, aux arrondis près. Que donnent les coefficients de corrélation33 ?
# [1] 0.8164205 0.8162365 0.8162867 0.8165214Nous avons à nouveau quatre fois la même valeur… et pourtant :
pl <- list(
chart(data = anscombe, y1 ~ x1) + geom_point(),
chart(data = anscombe, y2 ~ x2) + geom_point(),
chart(data = anscombe, y3 ~ x3) + geom_point(),
chart(data = anscombe, y4 ~ x4) + geom_point()
)
combine_charts(pl)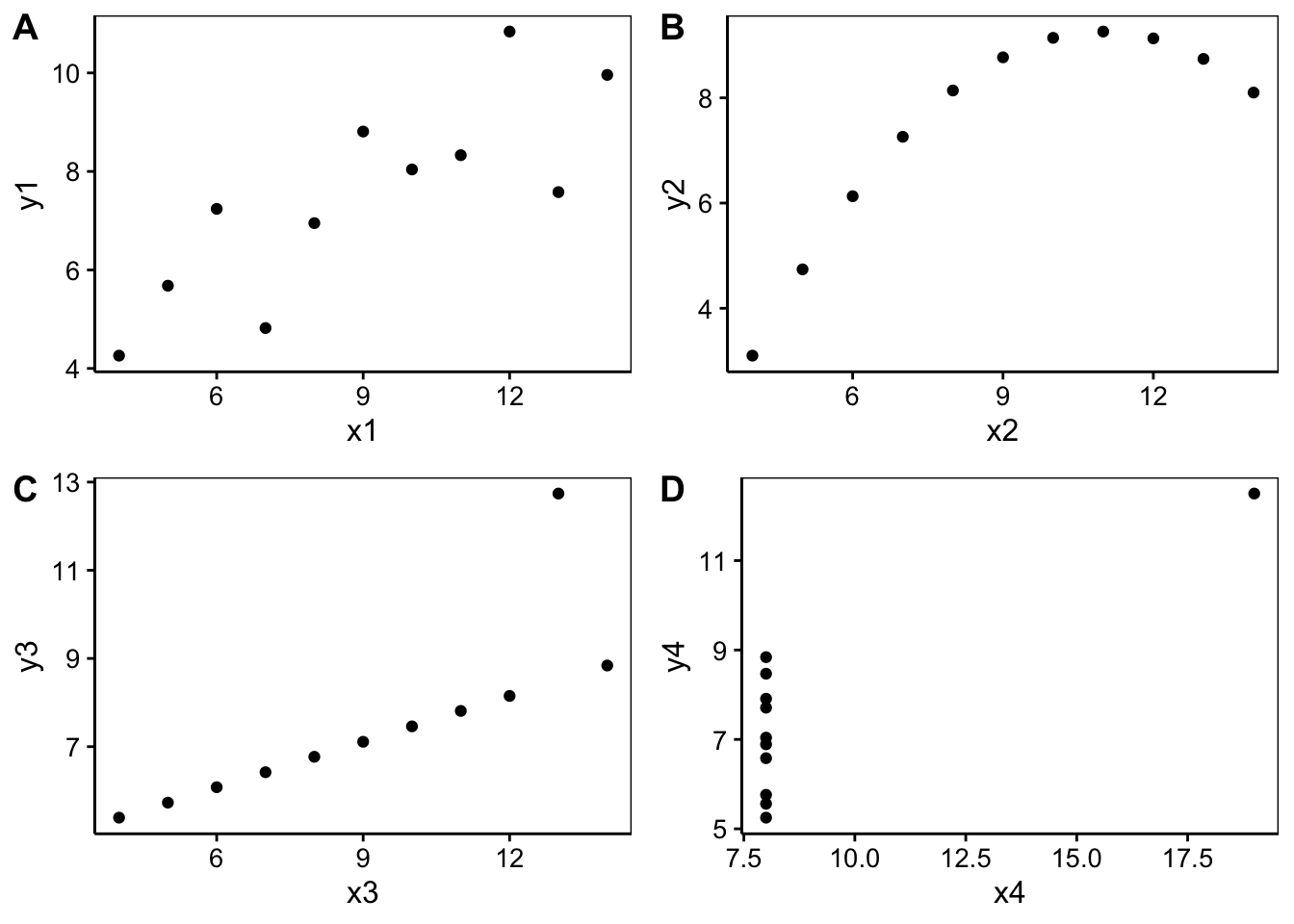
Nous voyons que ces quatre paires de variables n’ont rien à voir les unes avec les autres ! Il est même possible d’aller encore plus loin, voir le datasaurus dozen, ou encore ici.
6.5.1.3 Matrice de nuages de points
La matrice de nuages de points part du même principe que la matrice de corrélation ou que le corrélogramme : représenter plusieurs variables deux à deux selon une grille N par N pour N variables numériques. Ici, il s’agit de représenter des nuages de points deux à deux. Nous venons de voir pourquoi c’est important de le faire en complément des autres outils dans le cadre de notre exploration de l’association entre ces variables. Pour réaliser ce graphique, nous pouvons utiliser ggscatmat() du package {GGally} :
# Registered S3 method overwritten by 'GGally':
# method from
# +.gg ggplot2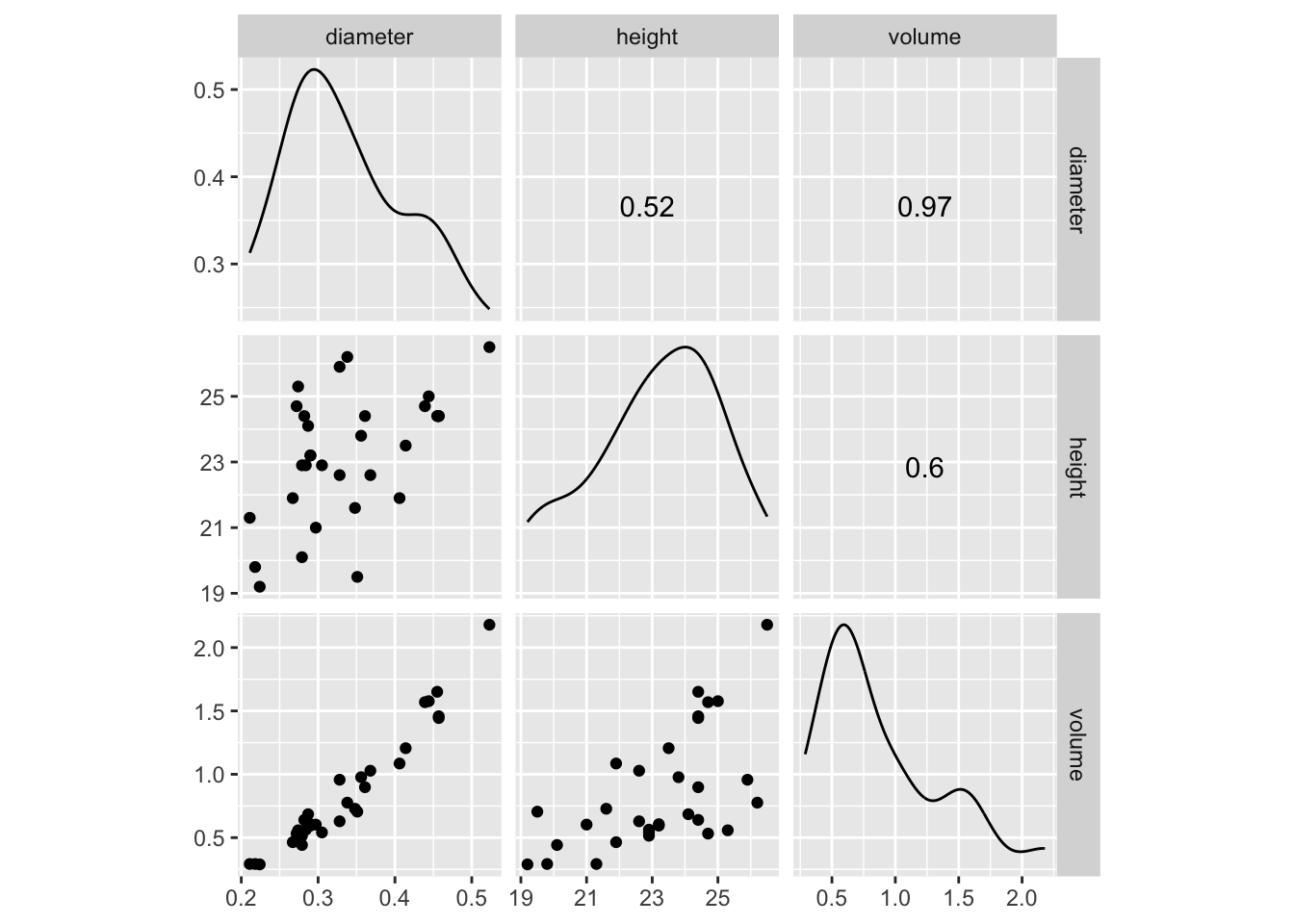
Comme dans le cas de la matrice de corrélation, les graphiques en nuage de points sur la diagonale ne seraient pas très utiles puisqu’ils représenteraient une variable par rapport à elle-même. Ils sont donc remplacés par des graphes de densité montrant la répartition des données pour chaque variable considérée individuellement. Sur le triangle supérieur, ce sont les coefficients de corrélation de Pearson qui sont indiqués. Sur le triangle inférieur, les différentes possibilités de nuages de points deux à deux sont représentées. La variable sur l’axe des abscisses se lit dans la colonne au-dessus et la variable représentée sur l’axe des ordonnées se lit dans la ligne à droite. Par exemple, le graphique en bas à gauche correspond au diamètre en abscisse et au volume en ordonnée. Cette représentation graphique est donc complémentaire au corrélogramme.
6.5.1.4 Matrice de variance-covariance
De même que nous pouvons calculer une matrice de corrélation, nous pouvons calculer une matrice de covariance, mais sachant que \(cov_{x,x} = var_x\), nous avons également les variances le long de la diagonale. Pour cette raison, nous appelons ce tableau, une matrice de variance-covariance. Par exemple, pour le jeu de données trees, cela donne :
| diameter | height | volume |
|---|---|---|---|
diameter | 0.00634 | 0.0805 | 0.0358 |
height | 0.08051 | 3.8001 | 0.5414 |
volume | 0.03584 | 0.5414 | 0.2166 |
Comme ces descripteurs statistiques ne sont pas normés, ils sont plus difficiles à interpréter. Nous préférons donc la matrice de corrélation pour étudier l’association entre plusieurs variables numériques. Néanmoins, la matrice de variances-covariance interviendra plus tard dans d’autres traitements statistiques et il est utile de la connaitre (par exemple, dans le cadre de l’ACP que nous étudierons en Science des Données biologiques II).
6.5.1.5 Corrélations de Spearman et Kendall
Le coefficient de corrélation de Pearson représente une corrélation linéaire. Cependant, il se peut que vous soyez intéressé par une corrélation non linéaire, un nuage de points qui s’allonge le long d’une courbe. Dans ce cas, vous pouvez utiliser soit le coefficient \(\rho\) de Spearman, soit le \(\tau\) de Kendall.
Le \(\rho\) de Spearman est le même calcul que le coefficient de Pearson, mais appliqué sur les données préalablement transformées en rangs (observations rangées de la plus petite à la plus grande, et ensuite, les valeurs sont remplacées par le numéro d’ordre de chaque observation : 1, 2, 3… pour les trois plus petites par exemple). Sa valeur vaudra +1 ou -1 lorsque les points s’alignent parfaitement le long de n’importe quelle fonction monotone croissante ou décroissante.
Le \(\tau\) de Kendall utilise un calcul selon la même logique que les tests de Wilcoxon ou de Kruskal-Wallis que nous découvrirons dans les prochains modules (wilcox) et (kruskal). Nous allons ici compter le nombre de paires concordantes \(n_c\) définies par \(x_i < x_j\ \mathrm{et}\ y_i < y_j\), ou \(x_i > x_j\ \mathrm{et}\ y_i > y_j\). Nous compterons aussi le nombre de paires discordantes \(n_d\) telles que \(x_i < x_j\ \mathrm{et}\ y_i > y_j\), ou \(x_i > x_j\ \mathrm{et}\ y_i < y_j\). Enfin, si \(x_i = x_j\ \mathrm{et}\ y_i = y_j\), la paire n’est pas comptabilisée. Nous avons alors pour un échantillon de n observations des variables numériques x et y :
\[\tau_{x,y} = \frac{n_c - n_d}{\frac{1}{2} \cdot n \cdot (n - 1)}\]
En pratique dans R, les fonctions cor() et correlation() peuvent être utilisées, mais en spécifiant method = "spearman" ou method = "kendall". Pour trees, cela donne :
# Matrix of Spearman's rank correlation rho:
# (calculation uses everything)
# diameter height volume
# diameter 1.000 0.441 0.955
# height 0.441 1.000 0.579
# volume 0.955 0.579 1.000# Matrix of Kendall's rank correlation tau:
# (calculation uses everything)
# diameter height volume
# diameter 1.000 0.317 0.830
# height 0.317 1.000 0.450
# volume 0.830 0.450 1.000… à comparer avec la matrice de corrélation de Pearson :
# Matrix of Pearson's product-moment correlation:
# (calculation uses everything)
# diameter height volume
# diameter 1.000 0.519 0.967
# height 0.519 1.000 0.597
# volume 0.967 0.597 1.000Les valeurs obtenues diffèrent, mais les tendances restent similaires ici. Les différences sont d’autant plus importantes que le nuage de points est curvilinéaire. À vous de bien choisir votre coefficient en fonction de ce que vous recherchez, une association linéaire (Pearson) ou pas (Spearman, le plus utilisé, ou Kendall éventuellement).
Ici, nous croisons les x et les y, et extrayons la diagonale de ce tableau qui correspond aux coefficients entre x1 et y1, entre x2 et y2, entre x3 et y3 et entre x4 et y4, respectivement.↩︎