2.1 Validation croisée
Rappelez-vous qu’une règle à laquelle il ne faut jamais déroger, c’est de ne pas utiliser les mêmes individus en apprentissage et en test.
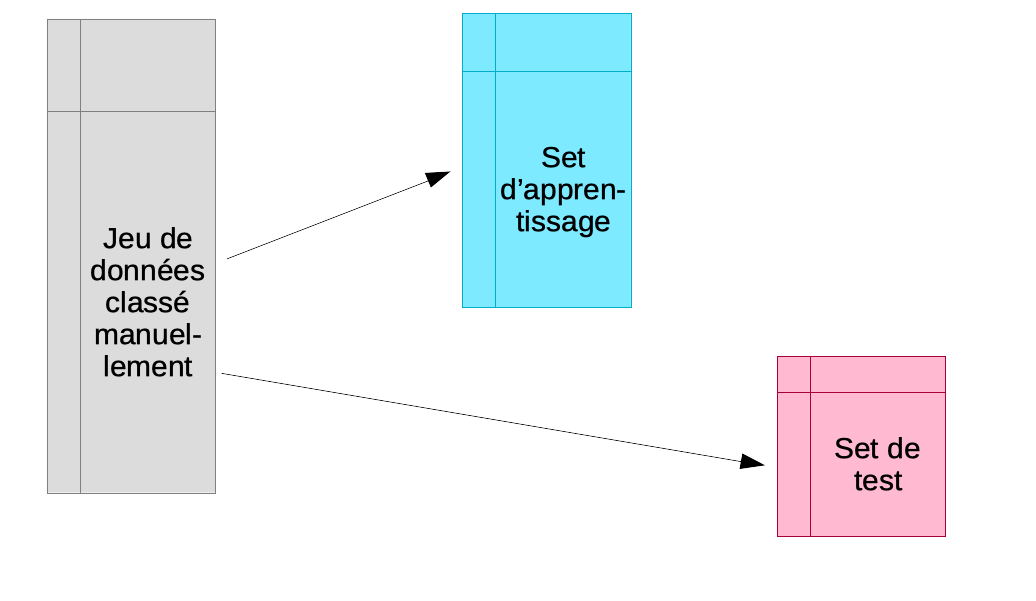
Souvent, la grosse difficulté est d’obtenir suffisamment d’objets de chaque classe identifiés manuellement pour permettre à la fois l’apprentissage et le test. Un test sur les mêmes objets que ceux utilisés lors de l’apprentissage mène à une surestimation systématique des performances du classifieur. Nous sommes donc contraints d’utiliser des objets différents dans les deux cas. Naturellement, plus, nous avons d’objets dans le set d’apprentissage et dans le set de test, et meilleur sera notre classifieur et notre évaluation de son efficacité.
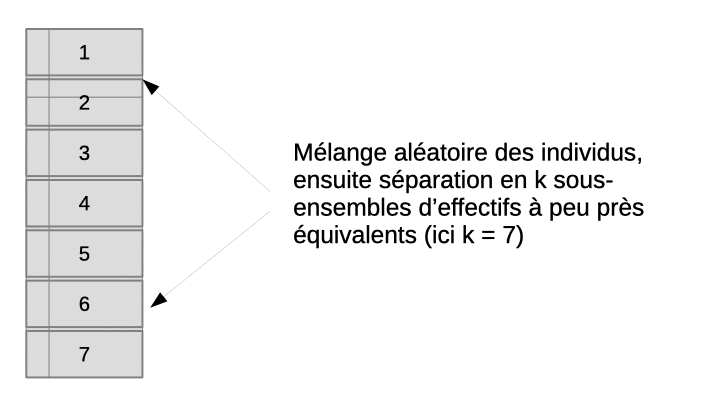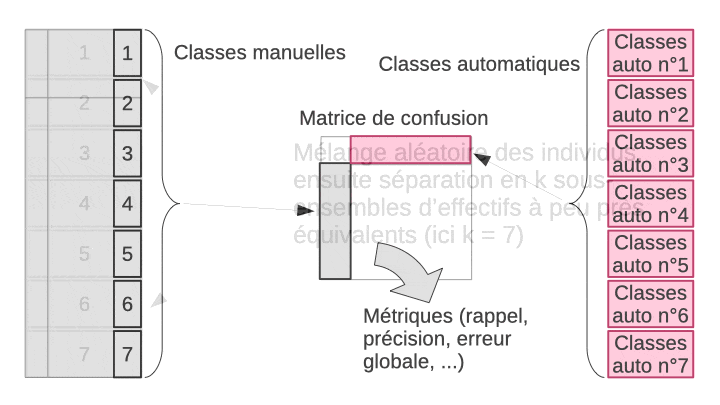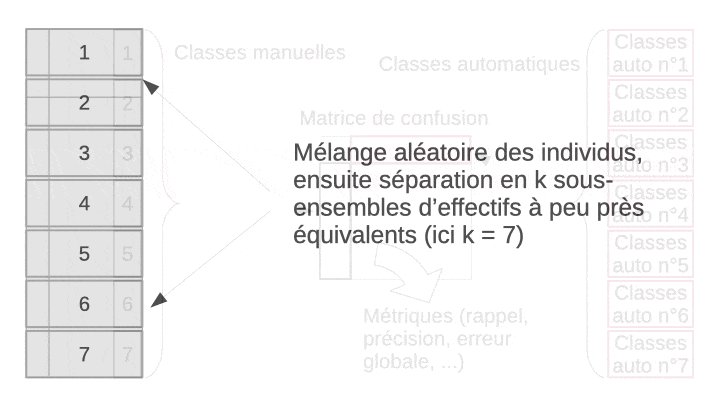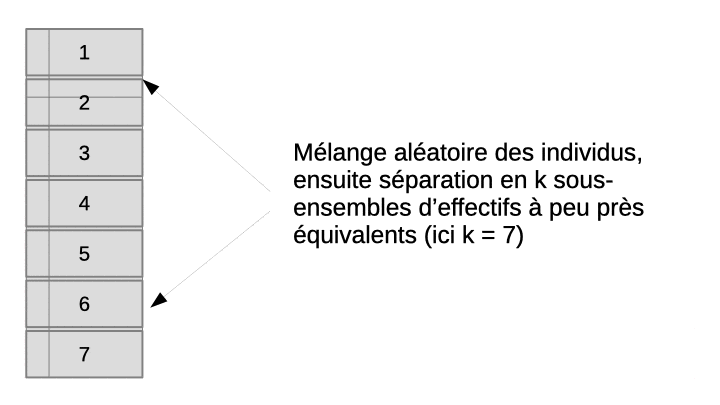
La validation croisée permet de résoudre ce dilemme en utilisant en fin de compte tous les objets, à la fois dans le set d’apprentissage et dans le set de test, mais jamais simultanément. L’astuce consiste à diviser aléatoirement l’échantillon en k sous-ensembles à peu près égaux en effectifs. Ensuite, l’apprentissage suivi du test est effectué n fois indépendamment. À chaque fois, on sélectionne tous les sous-ensembles sauf un pour l’apprentissage, et le sous-ensemble laissé de côté est utilisé pour le test. L’opération est répétée de façon à ce que chaque sous-ensemble serve de set de test tour à tour. Finalement, on rassemble les résultats obtenus sur les k sets de tests, donc, sur tous les objets de notre échantillon et on calcule la matrice de confusion complète en regroupant donc les résultats des k étapes indépendantes. Enfin, on calcule les métriques souhaitées sur cette matrice de confusion afin d’obtenir une évaluation approchée et non biaisée des performances du classifieur complet (entraîné sur l’ensemble des données à disposition). L’animation suivante visualise le processus pour que cela soit plus clair dans votre esprit.
À vous de jouer !
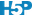
Au final, nous aurons utilisé tous les individus à la fois en apprentissage et en test, mais jamais simultanément. Le rassemblement des prédictions obtenues à chaque étape nous permet d’obtenir une grosse matrice de confusion qui contient le même nombre d’individus que l’ensemble de notre jeu de données initial. Naturellement, nous n’avons pas le même classifieur à chaque étape, et celui-ci n’est pas aussi bien construit que s’il utilisait véritablement toutes les observations. Mais plus le découpage est fin et plus nous nous en approchons. À la limite, pour n observations, nous pourrions réaliser k = n sous-ensembles, c’est-à-dire que chaque sous-ensemble contient un et un seul individu. Nous avons alors à chaque fois le classifieur le plus proche possible de celui que l’on obtiendrait avec véritablement toutes les observations puisqu’à chaque étape nous ne perdons qu’un seul individu en phase d’apprentissage. La contrepartie est un temps de calcul potentiellement très, très long puisqu’il y a énormément d’étapes. Cette technique porte le nom de validation par exclusion d’une donnée ou leave-one-out cross-validation en anglais, LOOCV en abrégé. À l’autre extrême, nous pourrions utiliser k = 2. Mais dans ce cas, nous n’utilisons que la moitié des observations en phase d’apprentissage à chaque étape. C’est le plus rapide, mais le moins exact.
À vous de jouer !
En pratique, un compromis entre exactitude et temps de calcul nous mène à choisir souvent la validation croisée dix fois (ten-fold cross-validation en anglais). Nous divisons aléatoirement en dix sous-ensembles d’à peu près le même nombre d’individus et nous répétons donc l’opération apprentissage -> test seulement dix fois. Chacun des dix classifieurs a donc été élaboré avec 90% des données totales, ce qui représente souvent un compromis encore acceptable pour estimer les propriétés qu’aurait le classifieur réalisé avec 100% des données. Toutefois, si nous constatons que le temps de calcul est raisonnable, rien ne nous empêche d’augmenter le nombre de sous-ensembles, voire d’utiliser la version par exclusion d’une donnée, mais en pratique nous observons tout de même que cela n’est pas raisonnable avec de très gros jeux de données et avec les algorithmes les plus puissants, mais aussi les plus gourmands en temps de calcul comme la forêt aléatoire ou les réseaux de neurones que nous aborderons dans le prochain module.
2.1.1 Application sur les manchots
Appliquons cela tout de suite avec l’ADL sur nos manchots. Plus besoin de séparer le jeu de données en set d’apprentissage et de test indépendants. La fonction cvpredict(, cv.k = ...) va se charger de ce partitionnement selon l’approche décrite ci-dessus en cv.k étapes. Notre analyse s’écrit alors :
# Importation et remaniement des données (comme précédemment)
penguins <- read("penguins", package = "palmerpenguins") %>.%
sdrop_na(.) ->
penguinsUne fois notre tableau complet, correctement nettoyé et préparé, nous faisons2 :
# ADL avec toutes les données
penguins_lda <- mlLda(data = penguins, species ~ bill_length +
bill_depth + flipper_length + body_mass)
# Prédiction par validation croisée 10x
set.seed(7567) # Pensez à varier le nombre à chaque fois ici !
penguins_pred <- cvpredict(penguins_lda, cv.k = 10)
# Matrice de confusion
penguins_conf <- confusion(penguins_pred, penguins$species)
plot(penguins_conf)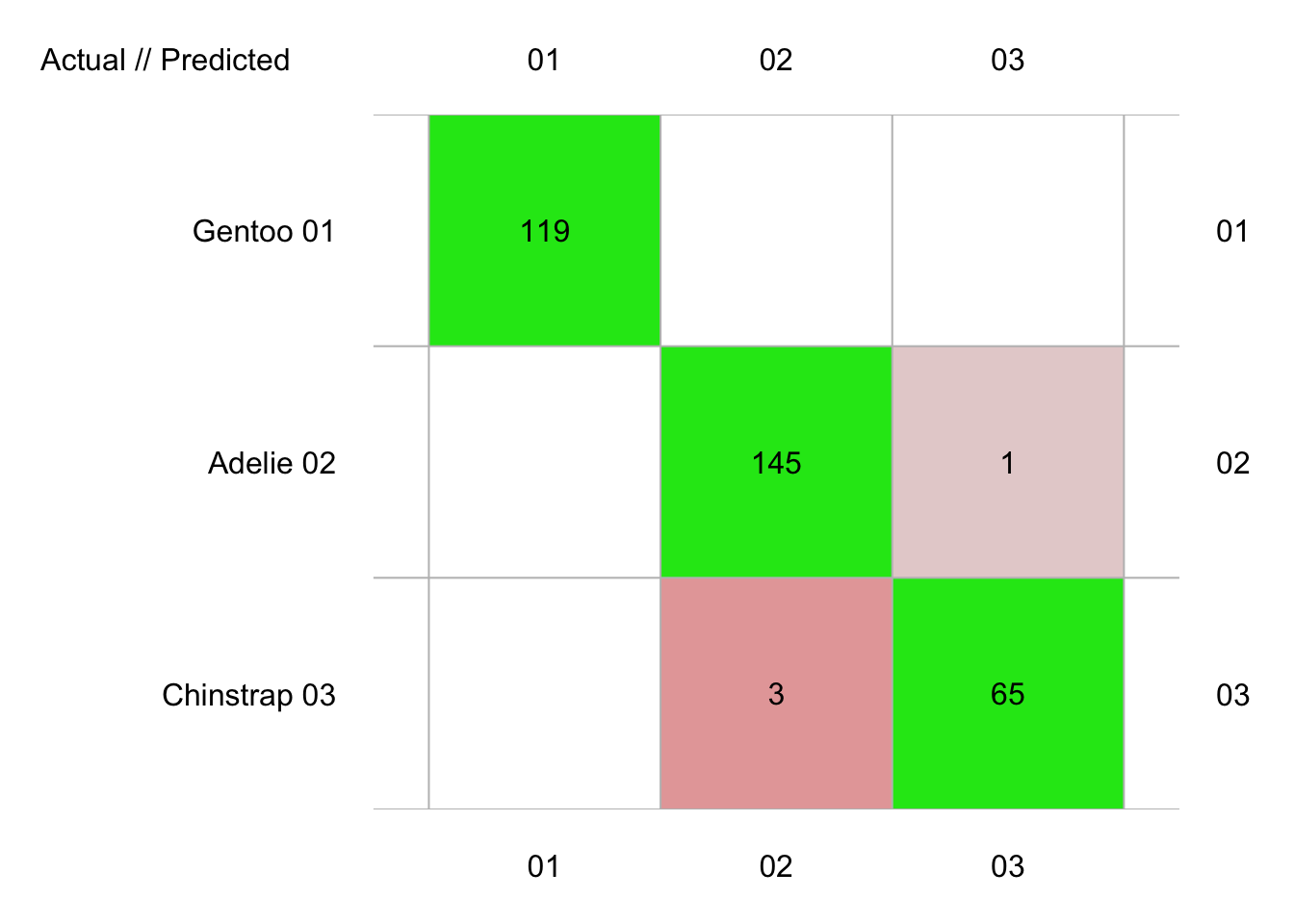
Ici, nous avons quatre erreurs, mais attention, ceci est comptabilisé sur trois fois plus de données que précédemment, puisque l’ensemble du jeu de données a servi ici en test, contre un tiers seulement auparavant. Donc, notre estimation des performances du classifieur est légèrement meilleure, mais la tendance générale avec une parfaite séparation de “Gentoo”, mais une petite erreur entre “Chinstrap” et “Adelie” reste la même. Les métriques sont disponibles à partir de notre objet penguins_conf comme d’habitude :
# 333 items classified with 329 true positives (error = 1.2%)
#
# Global statistics on reweighted data:
# Error rate: 1.2%, F(micro-average): 0.986, F(macro-average): 0.986
#
# Fscore Recall Precision Specificity NPV FPR
# Gentoo 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 0.000000000
# Adelie 0.9863946 0.9931507 0.9797297 0.9839572 0.9945946 0.016042781
# Chinstrap 0.9701493 0.9558824 0.9848485 0.9962264 0.9887640 0.003773585
# FNR FDR FOR LRPT LRNT LRPS
# Gentoo 0.000000000 0.00000000 0.000000000 Inf 0.000000000 Inf
# Adelie 0.006849315 0.02027027 0.005405405 61.90639 0.006960989 181.25000
# Chinstrap 0.044117647 0.01515152 0.011235955 253.30882 0.044284759 87.65152
# LRNS BalAcc MCC Chisq Bray Auto Manu A_M TP
# Gentoo 0.00000000 1.0000000 1.0000000 333.0000 0.000000000 119 119 0 119
# Adelie 0.02038043 0.9885540 0.9757151 317.0227 0.003003003 148 146 2 145
# Chinstrap 0.01532369 0.9760544 0.9628006 308.6860 0.003003003 66 68 -2 65
# FP FN TN
# Gentoo 0 0 214
# Adelie 3 1 184
# Chinstrap 1 3 264Notez cependant ici que vous ne devez pas vous contenter de générer et imprimer le tableau contenant toutes les métriques. En fonction de votre objectif, vous choisissez les métriques les plus pertinentes en les indiquant dans l’argument type= de summary() dans l’ordre que vous voulez. L’argument sort.by= permet, en outre, de trier les lignes de la meilleure à la moins bonne valeur pour une métrique donnée. Par exemple, si nous ne voulons que “Recall”, “Precision” et “Fscore” dans cet ordre, en triant par “Recall”, nous ferons :
# 333 items classified with 329 true positives (error = 1.2%)
#
# Global statistics on reweighted data:
# Error rate: 1.2%, F(micro-average): 0.986, F(macro-average): 0.986
#
# Recall Precision Fscore
# Gentoo 1.0000000 1.0000000 1.0000000
# Adelie 0.9931507 0.9797297 0.9863946
# Chinstrap 0.9558824 0.9848485 0.9701493Précédemment, nous avions 3,5% d’erreur, et maintenant, nous n’en avons plus que 1,2%. C’est normal que notre taux d’erreur baisse, car nos classifieurs par validation croisée utilisent 90% des données alors qu’auparavant, nous n’en utilisions que les 2/3. Les performances de nos classifieurs s’améliorent avec l’augmentation des données jusqu’à atteindre un palier. Il faut essayer de l’atteindre en pratique : s’il est possible d’ajouter plus de données, nous comparons avant-après, et si les performances s’améliorent, nous ajoutons encore plus de données jusqu’à atteindre le palier. Notez aussi que la quantité de données nécessaires dépend également de l’algorithme de classification. En général, plus il est complexe, plus il faudra de données. Pensez-y si vous en avez peu et utilisez alors préférentiellement des algorithmes plus simples comme ADL dans ce cas.
Si nous voulons faire un “leave-one-out”, nous ferions (sachant que nos données comptent 333 cas, nous indiquons ici cv.k = 333) :
penguins_pred_loo <- cvpredict(penguins_lda, cv.k = 333)
# Matrice de confusion
penguins_conf_loo <- confusion(penguins_pred_loo, penguins$species)
plot(penguins_conf_loo)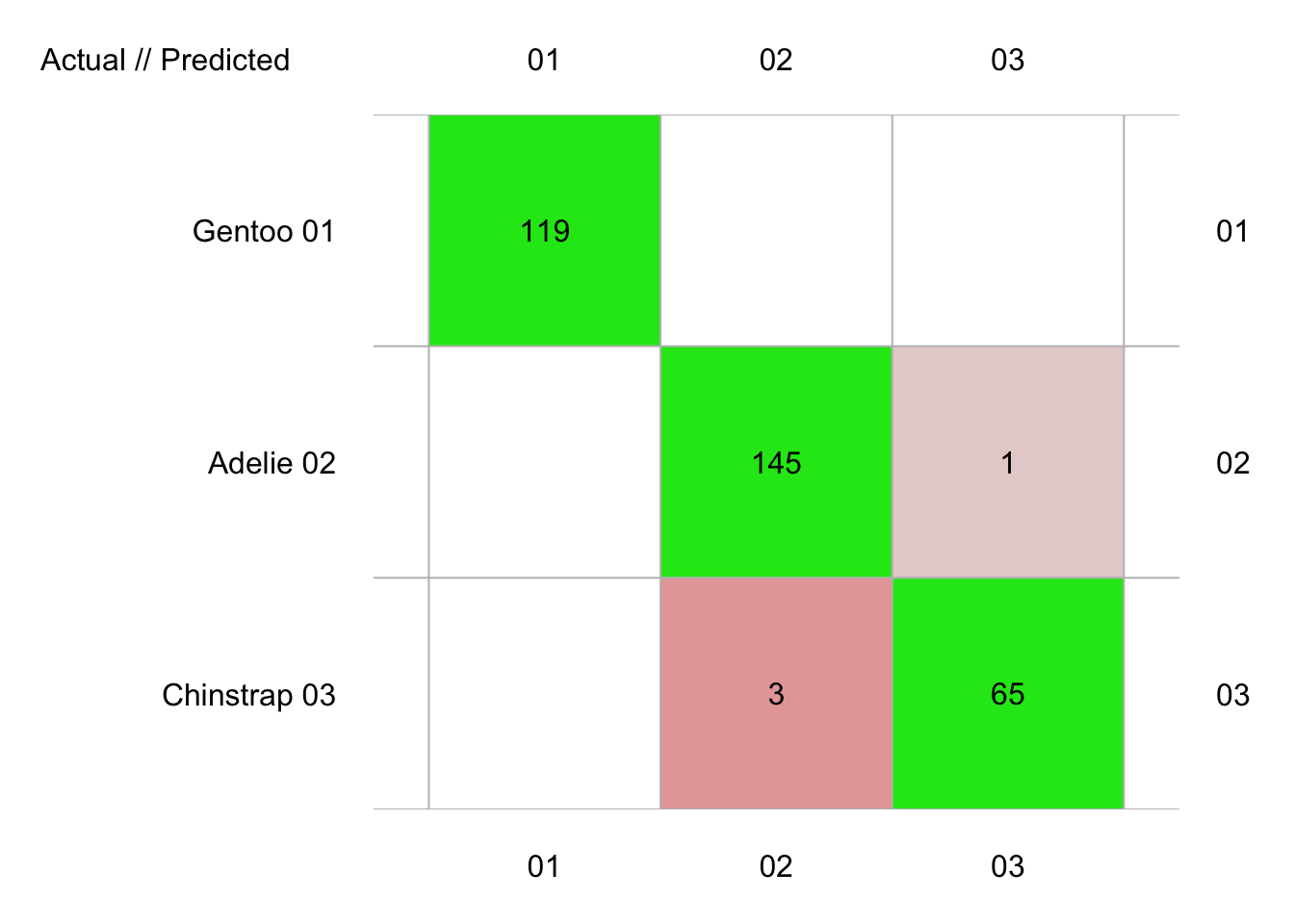
# 333 items classified with 329 true positives (error = 1.2%)
#
# Global statistics on reweighted data:
# Error rate: 1.2%, F(micro-average): 0.986, F(macro-average): 0.986
#
# Recall Precision Fscore
# Gentoo 1.0000000 1.0000000 1.0000000
# Adelie 0.9931507 0.9797297 0.9863946
# Chinstrap 0.9558824 0.9848485 0.9701493Le résultat est le même. Donc, nous venons de montrer que, dans le cas de ce jeu de données et de l’ADL, une validation croisée dix fois permet d’estimer les performances du classifieur aussi bien que l’approche bien plus coûteuse en calculs (342 classifieurs sont calculés et testés) du “leave-one-out”. Bien évidemment, ce ne sera pas toujours le cas.
À vous de jouer !
Effectuez maintenant les exercices du tutoriel C02La_cv (Validation croisée).
BioDataScience3::run("C02La_cv")À retenir
Bien que plus complexe en interne, la validation croisée est très facile à utiliser avec {mlearning} grâce à la fonction
cvpredict(),L’approche par validation croisée optimise l’utilisation des données à disposition. C’est la technique à préférer, sauf si nous disposons vraiment de données à profusion.
Ici nous avons choisi de conserver toutes les variables dans le jeu de données. Mais nous ne pouvons utiliser que les variables quantitatives comme attributs avec l’ADL. Nous specifions donc les variables à utiliser dans la formule complète. Nous aurions aussi bien pu créer d’abord un tableau réduit à ces variables plus la classe et ensuite utiliser la formule
class ~ .comme nous l’avons fait dans le module précédent. Vous pouvez ainsi comparer les deux approches possibles.↩︎