1.1 Principes de base
Rappelez-vous, la classification sert à regrouper les individus d’un jeu de données en différents groupes ou classes. Lorsque vous avez utilisé la classification hiérarchique ascendante ou le dendrogramme, vous avez réalisé de la classification non supervisée. La classification non supervisée permet de choisir des classes librement sur base de l’information de similitude ou différence entre les individus contenus dans le jeu de données.
Nous allons aborder maintenant la classification supervisée. La classification supervisée (une sous-partie de l’apprentissage machine ou “machine learning” en anglais) permet d’utiliser un ordinateur pour lui faire apprendre à classer des objets selon nos propres critères que nous spécifions par ailleurs. Par exemple, en biologie, nous sommes amenés à classer le vivant (la fameuse classification taxonomique selon la nomenclature binomiale de Linné). Nous pourrions être amenés à nous faire seconder par un ordinateur pour classer nos plantes en herbier, nos insectes en collections … ou nos photos d’oiseaux ou de poissons. À partir du moment où nous pouvons collecter ou mesurer différentes caractéristiques quantitatives ou qualitatives sur chaque individu, et que pour certains, nous en connaissons le nom scientifique, la classification supervisée pourrait être utilisée pour classer automatiquement d’autres individus, uniquement sur base des mêmes mesures. Mais ceci n’est qu’un exemple d’application possible parmi beaucoup d’autres en biologie…
Un jeu de données est composé d’observations (les lignes du tableau) et de variables (les colonnes du tableau) sur ces observations. En classification supervisée, les observations se nomment les items ou les cas (nos différents spécimens de plantes, insectes…) et les variables se nomment les attributs (les variables quantitatives ou qualitatives mesurées sur chaque spécimen).
À vous de jouer !
En taxonomie assistée par ordinateur, nous cherchons donc à accélérer le dépouillement de gros échantillons en identifiant de manière automatique (ou semi-automatique) la faune et/ou la flore qui les composent. L’approche la plus souvent employée est l’analyse d’image pour mesurer des caractères visuels sur ces photographies. Il s’agit donc d’une classification sur base de critères morphologiques. Les organismes qui composent la faune et/ou la flore sont les items et les critères morphologiques sont les attributs. Vous avez certainement déjà rêvé d’avoir quelqu’un qui fait vos identifications à votre place… pourquoi pas votre ordinateur ?
Parmi tous les items, on va choisir un sous-ensemble représentatif que l’on classe manuellement sans erreur. On obtient donc un ensemble de groupes connus et distincts. On va diviser ce sous-ensemble en un set d’apprentissage pour entraîner l’algorithme de classification, et un set de test pour en vérifier les performances.
La classification supervisée va se décomposer en réalité en trois phases.
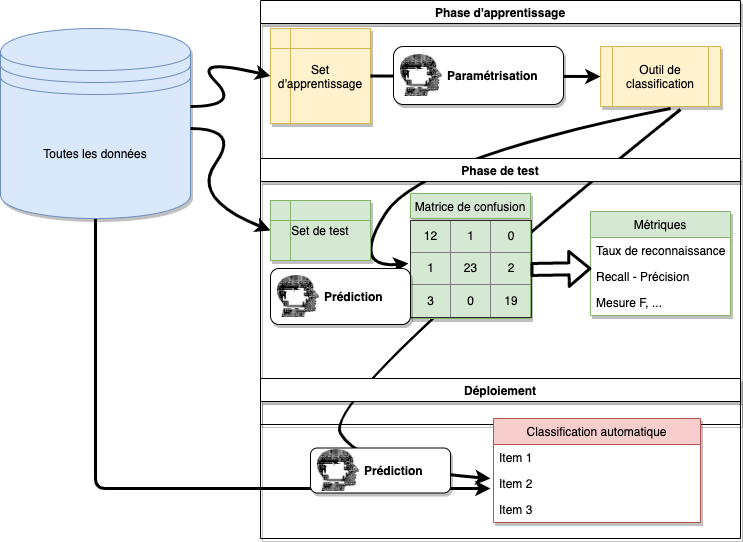
Apprentissage : un classifieur, basé sur un algorithme de classification est entraîné (paramétré) pour classer les items sur base du set d’apprentissage.
Test : les performances du classifieur sont évaluées à l’aide du set de test.
Déploiement : si le classifieur obtient des performances satisfaisantes, il est utilisé pour classer automatiquement tous les autres items du jeu de données.
Les trois phases sont appliquées sur des individus différents, donc souvent sur des tableaux de données différents eux aussi. Vous devez veiller à ce que ces trois tableaux soient compatibles entre eux, c’est-à-dire, qu’ils contiennent les mêmes variables dans les mêmes formats. En particulier, vous devez veiller à ce que la variable à prédire porte le même nom et soit sous forme factor dans R, à la fois dans le set d’apprentissage et dans le set de test.
Vous devez également veiller à ce qu’il n’y ait pas de données manquantes, si la méthode de classification utilisée ne les supporte pas (cas le plus fréquent). Les modifications éventuelles des données sont donc à réaliser avant de séparer le tableau de données initial en set d’apprentissage et set de test. De cette façon, le pré-traitement n’est effectué qu’une seule fois, et nous sommes certains que les deux tableaux d’apprentissage et de test sont conformes après séparation. Pour le déploiement, n’oubliez pas d’effectuer les mêmes préparatifs des variables avant de prédire les classes à partir de ce troisième tableau.
Dans R, une série de packages prévus pour fonctionner ensemble selon un système cohérent appelé tidymodels offre une autre façon plus flexible de préparer les attributs, ce que l’on appelle en anglais le feature engineering, via le package {recipes}. La transformation est encodée dans le classifieur lui-même et est appliquée automatiquement de la même façon sur le set de test, de validation ou pour toute prédiction ultérieure. Dans ce cas, il est préférable, au contraire, de partir des variables brutes ayant été altérées au minimum.Il y a de très nombreux domaines d’applications de ces techniques de classification supervisée de type “machine learning”. Par exemple en médecine, ces techniques s’utilisent pour analyser les mesures effectuées par un scanner, un système de radiographie aux rayons X, un électrocardiogramme ou un électroencéphalogramme… pour y détecter des anomalies. Votre moteur de recherche favori sur Internet utilise ces techniques pour classer les pages en “pertinentes” et “non pertinentes”. La reconnaissance vocale ou de l’écriture manuscrite entrent dans cette catégorie également, de même que l’analyse de sentiment sur base de texte (déterminer l’état d’esprit de l’auteur du texte sur base des mots et expressions qu’il utilise).
Il faut s’attendre à ce que dans quelques années, des algorithmes plus efficaces, et des ordinateurs plus puissants pourront effectuer des tâches aujourd’hui dévolues à des spécialistes, comme le médecin spécialisé en radiographie pour l’exemple cité plus haut. Nous sommes même à l’aube des véhicules capables de conduire tous seuls, sur base de l’analyse des images fournies par leurs caméras ! Et bien sûr… les LLM (large language models en anglais) font une percée dans la vie de monsieur tout le monde avec ChatGPT et des dizaines de systèmes similaires. Ces systèmes, basés sur l’apprentissage profond, effectuent également une sorte de classification supervisée très élaborée des mots les plus probables dans un discours l’un après l’autre… ce qui finit par former un texte original qui ressemble à ce qu’un humain aurait écrit (mais parfois le sens laisse à désirer, parfois pas) !
1.1.1 Conditions d’application
Ces outils ont très certainement éveillé votre curiosité. Imaginez qu’à l’avenir il ne sera peut plus utile d’apprendre la classification des bourdons (clin d’œil à un des laboratoires de l’Université de Mons). Un ordinateur pourra le faire à votre place. Il y a néanmoins certaines conditions d’application à satisfaire préalablement afin de pouvoir utiliser efficacement l’apprentissage machine ou “machine learning” :
Tous les groupes sont connus et disjoints. Chaque cas appartient à une et une seule classe (sinon, refaire un découpage plus judicieux des classes). Un individu ne peut appartenir simultanément à deux ou plusieurs classes, et nous ne pouvons pas rencontrer de cas n’appartenant à aucune classe. Éventuellement, rajouter une classe fourre-tout nommée “autre” pour que cette condition puisse être respectée.
La classification manuelle est réalisée sans erreur dans les sets d’apprentissage et de test. C’est une contrainte forte. Vérifiez soigneusement vos sets avant utilisation. Éventuellement, recourez à l’avis de plusieurs spécialistes et établissez un consensus, ou éliminez les cas litigieux… mais attention alors à ne pas déroger à la condition suivante !
Toute la variabilité est représentée dans le set d’apprentissage. Vous devez vous assurer de rassembler les individus représentant toute la variabilité de chaque classe pour la phase d’apprentissage (et de test aussi).
Les mesures utilisées sont suffisamment discriminantes entre les classes. Vous devez vous arranger pour définir et mesurer des attributs qui permettent de séparer efficacement les classes. Vous pourrez le constater visuellement en représentant, par exemple, deux attributs quantitatifs sur un graphique en nuage de points, et en y plaçant les points représentant vos individus en couleurs différentes en fonction de leurs classes. Si des regroupements bien distincts sont visibles sur le graphique, vous êtes bons … sinon c’est mal parti. Utilisez éventuellement des techniques comme l’analyse des composantes principales (ACP) pour visualiser de manière synthétique un grand nombre d’attributs. L’ingénierie et sélection judicieuse des attributs est une partie cruciale, mais difficile de la classification supervisée. L’apprentissage profond (“deep learning”) tente de s’en débarrasser en incluant cette partie du travail dans le programme d’apprentissage lui-même.
Le système est statique : pas de changement des attributs des items à classer par rapport à ceux des sets d’apprentissage et de test. Des situations typiques qui peuvent se produire et qui ruinent votre travail sont un été particulièrement chaud et sec par rapport aux saisons pendant lesquelles des plantes ont été prélevées pour le set d’apprentissage. Par conséquent, vos fleurs ont des caractéristiques morphologiques différentes suite à cette longue canicule et sont donc moins bien, voire, totalement mal classées. Un autre exemple serait le changement d’appareil de RMN qui donne des images légèrement différentes du précédent. Le set d’apprentissage de la première RMN ne permet alors peut-être pas de créer un classifieur capable de classer valablement les analyses réalisées avec le second appareil.
Toutes les classes ont des représentants dans les sets. Il parait assez évident que si le set d’apprentissage ne contient aucun item pour une classe, l’algorithme de classification ne peut pas être entraîné à reconnaître cette classe-là. Par contre, il est également indispensable que le set de test soit pourvu d’un minimum d’items par classe, afin d’établir correctement une estimation des performances du classifieur pour chaque classe. Attention avec une répartition aléatoire entre apprentissage et test pour une très petite quantité totale de données dans une ou plusieurs classes, cette situation pourrait apparaître par le biais du hasard.
En pratique, ces conditions d’application ne sont pas remplies strictement dans les faits, mais le but est de s’en rapprocher le plus possible. Par exemple, il est impossible en pratique de garantir qu’il n’y ait absolument aucune erreur dans les sets d’apprentissage et de test. Si le taux d’erreur reste faible (quelques pour cent voire encore moins), l’impact de ces erreurs sera suffisamment négligeable. Par contre, avec 20 ou 30% d’erreurs, par exemple, nous ne pourrons plus travailler valablement.