4.3 Manipulation et description
Tout comme pour les statistiques plus classiques, nous commençons toujours notre exploration de séries chronologiques par une partie purement descriptive, soit numérique, soit graphique. De plus, nous savons que nous ne devons pas espérer obtenir d’emblée des données qui se présentent de manière parfaite. Un petit peu de manipulation de données est parfois nécessaire… et nous allons découvrir quelques fonctions utiles dans ce contexte pour les séries chronologiques.
Comme nous l’avons déjà vu, le graphe de base (obtenu par plot() ou en utilisant geom_line()) est une ligne brisée qui relie les différents points de la série, avec le temps sur l’axe des abscisses, et l’axe des ordonnées représentant les observations de la variable quantitative mesurée au fil du temps.
4.3.1 Statistiques glissantes
Les descripteurs statistiques tels que la moyenne, la médiane, l’écart type, etc. restent utiles pour les séries temporelles. Par contre, la valeur de ces descripteurs est susceptible de varier au cours du temps, et cette variation donne des indications utiles sur les mécanismes biologiques sous-jacents (par exemple, des fluctuations, des changements brutaux de régimes, etc.). Il nous faut donc calculer ces descripteurs pour des intervalles de temps précis le long de l’axe temporel de notre série. Les statistiques glissantes (sliding statistics en anglais) correspondent précisément à l’analyse de blocs successifs de données suivant un axe spatio-temporel. Dans {pastecs}, elles se calculent à l’aide de la fonction stat.slide().
Exemple
Nous reprenons ici l’exemple du manuel de {pastecs}. On peut calculer des statistiques glissantes pour la série ClausocalanusA de marbio par groupe de 10 stations, les imprimer et faire un graphique de la “moyenne glissante” à l’aide des instructions suivantes :
marbio_ts <- ts(read("marbio", package = "pastecs"))
statsl <- stat.slide(1:68, marbio_ts[, "ClausocalanusA"],
xmin = 0, n = 7, deltat = 10)
statsl# # A data.frame: 10 x 7
# ` ` `[0,10[` `[10,20[` `[20,30[` `[30,40[` `[40,50[` `[50,60[` `[60,70[`
# <rownam> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
# 1 xmin 0 10 20 30 40 50 60
# 2 xmax 10 20 30 40 50 60 70
# 3 nbr.val 9 10 10 10 10 10 9
# 4 nbr.null 2 0 0 0 0 0 0
# 5 nbr.na 0 0 0 0 0 0 0
# 6 min 0 160 158 96 136 56 52
# 7 max 12 832 1980 1204 2484 824 656
# 8 median 4 344 732 752 260 340 120
# 9 mean 4.78 351. 810. 682 494. 365. 219.
# 10 std.dev 4.79 197. 620. 350. 711. 235. 202.plot(statsl, stat = "mean", leg = TRUE, lpos = c(55, 2500),
xlab = "Station", ylab = "ClausocalanusA")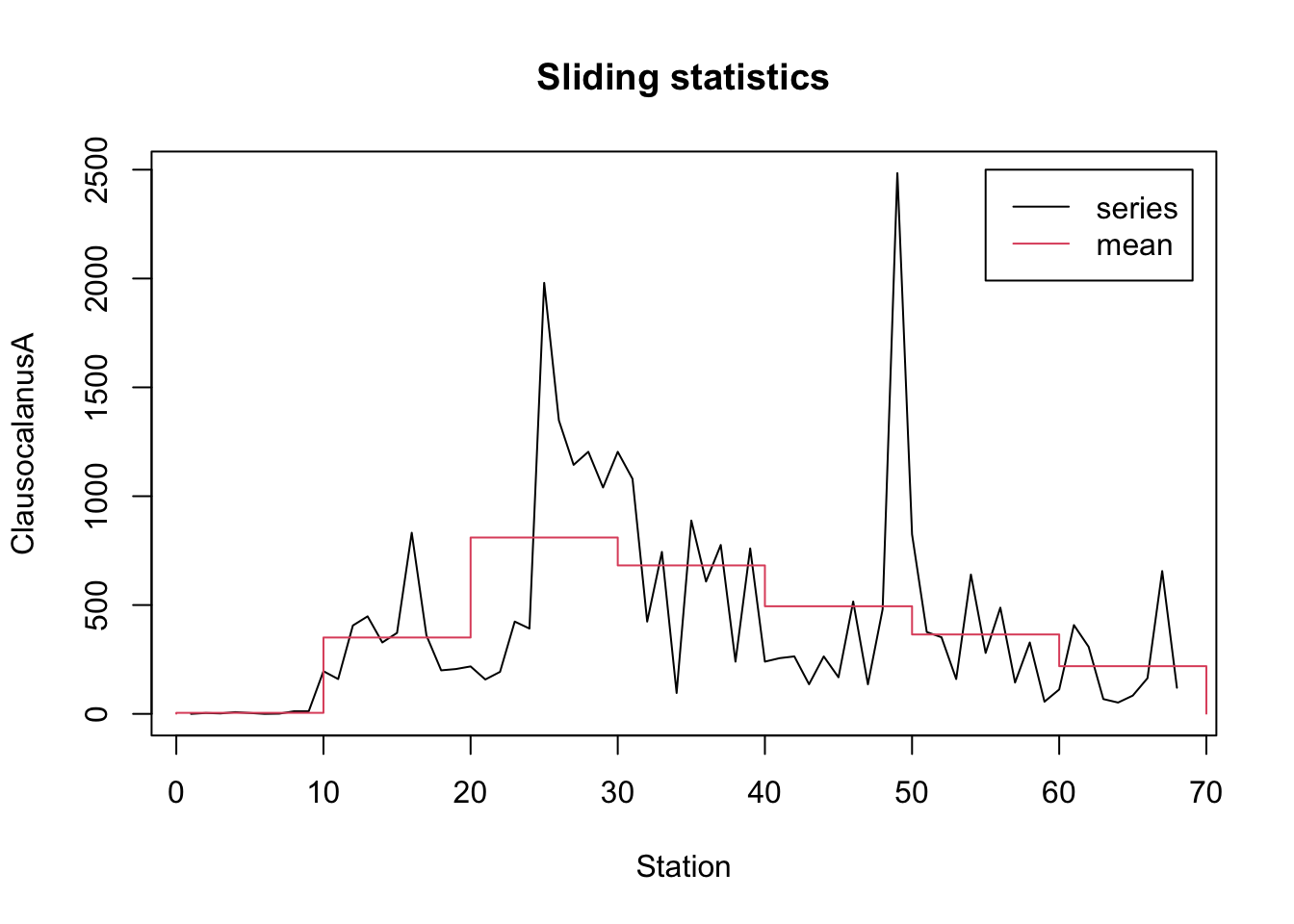
Toujours pour la même série, on peut calculer toutes les statistiques sur des intervalles irréguliers, puis représenter l’étendue (minimum, maximum) et la médiane pour chaque intervalle comme suit (ces intervalles correspondent aux différentes masses d’eaux croisées le long du transect, voir légende du graphique) :
statsl2 <- stat.slide(1:68, marbio_ts[, "ClausocalanusA"],
xcut = c(0, 17, 25, 30, 41, 46, 70),
basic = TRUE, desc = TRUE, norm = TRUE, pen = TRUE, p = 0.95)
statsl2# # A data.frame: 29 x 6
# ` ` `[0,17[` `[17,25[` `[25,30[` `[30,41[` `[41,46[` `[46,70[`
# <rownames> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
# 1 xmin 0 17 25 30 41 46
# 2 xmax 17 25 30 41 46 70
# 3 nbr.val 16 8 5 11 5 23
# 4 nbr.null 2 0 0 0 0 0
# 5 nbr.na 0 0 0 0 0 0
# 6 min 0 158 1040 96 136 52
# 7 max 832 424 1980 1204 264 2484
# 8 range 832 266 940 1108 128 2432
# 9 sum 2785 2151 6716 7060 1088 9236
# 10 median 12 212 1204 744 256 308
# # … with 19 more rowsplot(statsl2, stat = "median", xlab = "Stations", ylab = "Effectifs",
main = "Clausocalanus A") # Médiane
lines(statsl2, stat = "min") # Minimum
lines(statsl2, stat = "max") # Maximum
lines(c(17, 17), c(-50,2600), col = 4, lty = 2) # Séparations des masses d'eaux
lines(c(25, 25), c(-50,2600), col = 4, lty = 2)
lines(c(30, 30), c(-50,2600), col = 4, lty = 2)
lines(c(41, 41), c(-50,2600), col = 4, lty = 2)
lines(c(46, 46), c(-50,2600), col = 4, lty = 2)
text(c(8.4, 21, 27.5, 35, 43.5, 57.2), 2300,
labels = c("Zone périphérique", "D1", "C", "Front", "D2", "Zone centrale")) # Labels
legend(0, 1900, c("série", "médian", "étendue"), col = 1:3, lty = 1)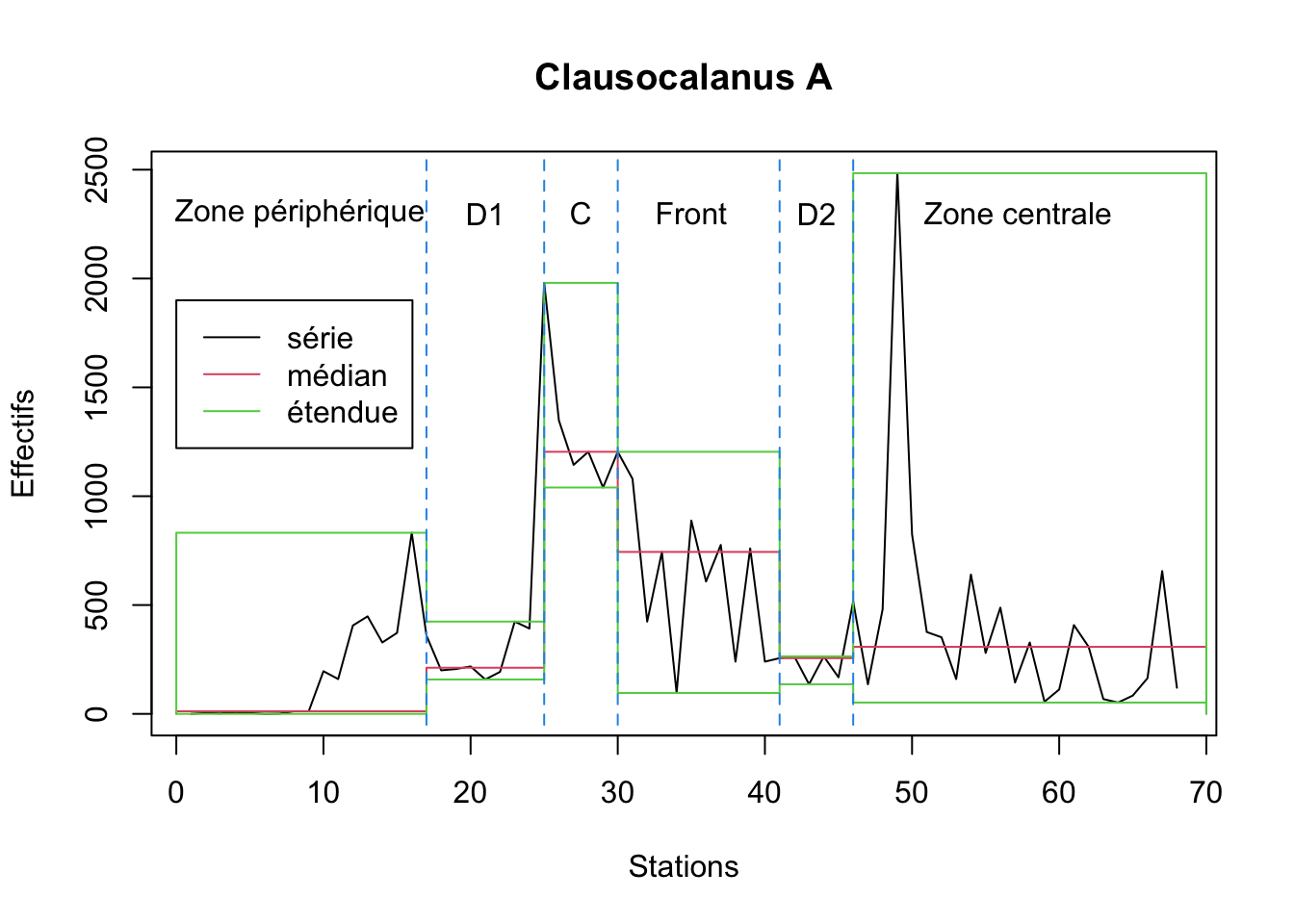
Enfin, on peut extraire différentes statistiques, les valeurs de la série initiale (y), les valeurs de temps de la série (x), et le vecteur temps de coupure des périodes (xcut) à partir de l’objet stat.slide renvoyé :
# # A data.frame: 4 x 6
# ` ` `[0,17[` `[17,25[` `[25,30[` `[30,41[` `[41,46[` `[46,70[`
# <rownames> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
# 1 mean 174. 269. 1343. 642. 218. 402.
# 2 median 12 212 1204 744 256 308
# 3 min 0 158 1040 96 136 52
# 4 max 832 424 1980 1204 264 2484# [1] 0 4 2 8 4 0 1 12 12 196 160 406 448 328 372
# [16] 832 360 200 206 218 158 193 424 392 1980 1348 1144 1204 1040 1204
# [31] 1080 424 744 96 888 608 776 240 760 240 256 264 136 264 168
# [46] 516 136 480 2484 824 376 352 160 640 280 488 144 328 56 112
# [61] 408 308 68 52 84 164 656 120# [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
# [26] 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
# [51] 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68# [1] 0 17 25 30 41 46 70À vous de jouer !
Effectuez maintenant les exercices du tutoriel C04La_ts_intro (Introduction aux séries chronologiques).
BioDataScience3::run("C04La_ts_intro")4.3.2 Manipulations de ts
Les jeux de données bricolés artificiellement sont parfois bien utiles pour explorer de nouvelles techniques. En effet, puisque nous les construisons nous-mêmes, nous savons dès le départ de quoi ils sont faits. Et donc, nous pouvons vérifier que le résultat obtenu est bien conforme. Par exemple, nous pouvons construire une série de données mensuelle commençant en avril 1998 (start = c(1998, 4)), contenant 100 valeurs et comportant une composante sinusoïdale d’une période annuelle ainsi qu’une composante aléatoire ayant une distribution normale de moyenne nulle et d’écart type 0.5 :
# Jan Feb Mar Apr May Jun
# 1998 0.43284443 0.55796734 1.70265599
# 1999 -1.24312825 -0.49738897 1.19660403 0.05225123 0.57422522 2.21443653
# 2000 -1.27975774 -0.39864209 0.19718918 -0.25121656 0.79224043 0.67165187
# 2001 -1.33085705 -0.31227960 -0.34076874 1.26087821 0.90076680 0.72463865
# 2002 -1.49102561 -1.23752020 0.36432449 0.16888829 0.49321406 0.41112583
# 2003 -0.33160770 0.03132431 0.75403988 0.54097729 0.91892553 1.01564832
# 2004 -0.66010261 -0.55657839 0.90346085 0.88632106 0.28931583 0.52236703
# 2005 -0.18028826 -1.67848525 0.75703973 0.37294084 1.04893710 1.20347449
# 2006 -0.72877221 -0.71386908 -0.33470161 0.97725885 0.35056006 2.09328093
# Jul Aug Sep Oct Nov Dec
# 1998 0.71754359 1.65962493 -0.34002388 -0.93349797 -0.08686532 -1.06923582
# 1999 1.30384411 1.35349511 -0.14072954 -0.58534641 -1.44827029 -1.04973955
# 2000 1.27543290 0.27594795 -0.10605802 -0.42613394 -1.26309700 0.04021914
# 2001 0.43546515 0.99636669 -0.31451471 -0.36733500 -1.35331820 -1.11501552
# 2002 0.81847016 0.36884872 0.51316559 -0.83152133 -0.71954553 -0.82510491
# 2003 1.63474275 1.08403393 -0.04882395 -0.01570617 -0.54439103 -1.40656027
# 2004 1.66861579 0.30669569 0.53616651 0.03691720 -0.86264360 -1.26470062
# 2005 0.86734660 -0.04116614 -0.72024479 -0.40289493 -1.21954480 -1.17567484
# 2006 0.89088635Créons maintenant une série multiple en prenant notre série de départ, ainsi qu’une version décalée de cinq mois à l’aide de la fonction stats::lag() et représentons cela graphiquement :
mtser <- ts.intersect(tser, stats::lag(tser, 5))
plot(mtser, xlab = "Temps", main = "Série tser et série décalée de 5 mois")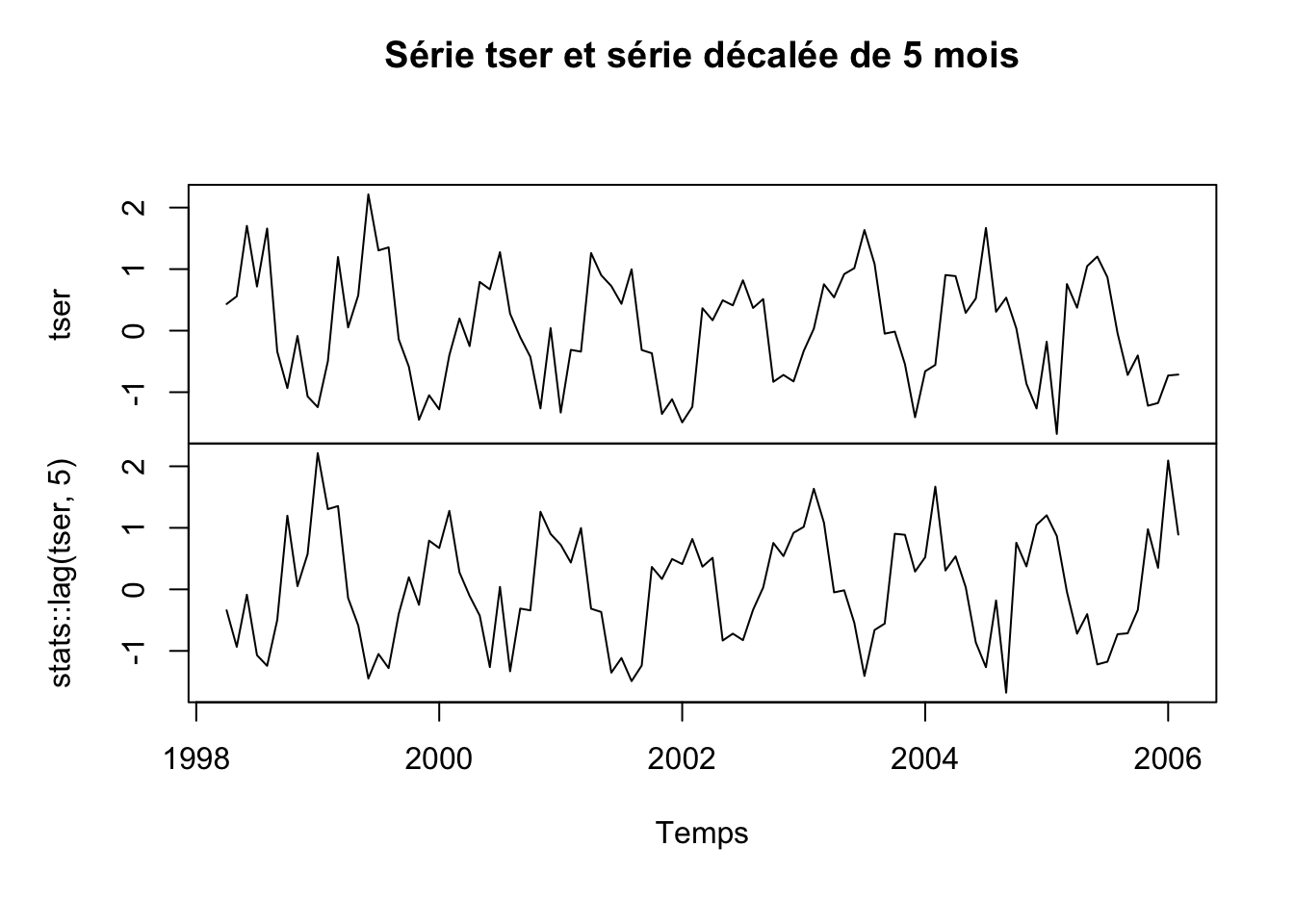
4.3.2.1 Manipulation du temps
Les fonctions tsp(), start(), end() et frequency() permettent de récupérer les différents paramètres de temps de la série :
# [1] 1998.25 2006.50 12.00# [1] 1998 4# [1] 2006 7# [1] 12Nous avons déjà vu la fonction time() qui permet de reconstituer le vecteur temps pour la série. La fonction cycle() indique l’appartenance de chaque donnée de la série à un cycle. Elle permet, par exemple, de séparer les données par mois si la base de temps est l’année à l’aide de la fonction split(). Ensuite, il est possible de traiter ou de représenter séparément les statistiques mois par mois pour en faire, par exemple, des boites de dispersions parallèles :
# Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
# 1998 4 5 6 7 8 9 10 11 12
# 1999 1 2 3 4 5 6 7 8 9 10 11 12
# 2000 1 2 3 4 5 6 7 8 9 10 11 12
# 2001 1 2 3 4 5 6 7 8 9 10 11 12
# 2002 1 2 3 4 5 6 7 8 9 10 11 12
# 2003 1 2 3 4 5 6 7 8 9 10 11 12
# 2004 1 2 3 4 5 6 7 8 9 10 11 12
# 2005 1 2 3 4 5 6 7 8 9 10 11 12
# 2006 1 2 3 4 5 6 7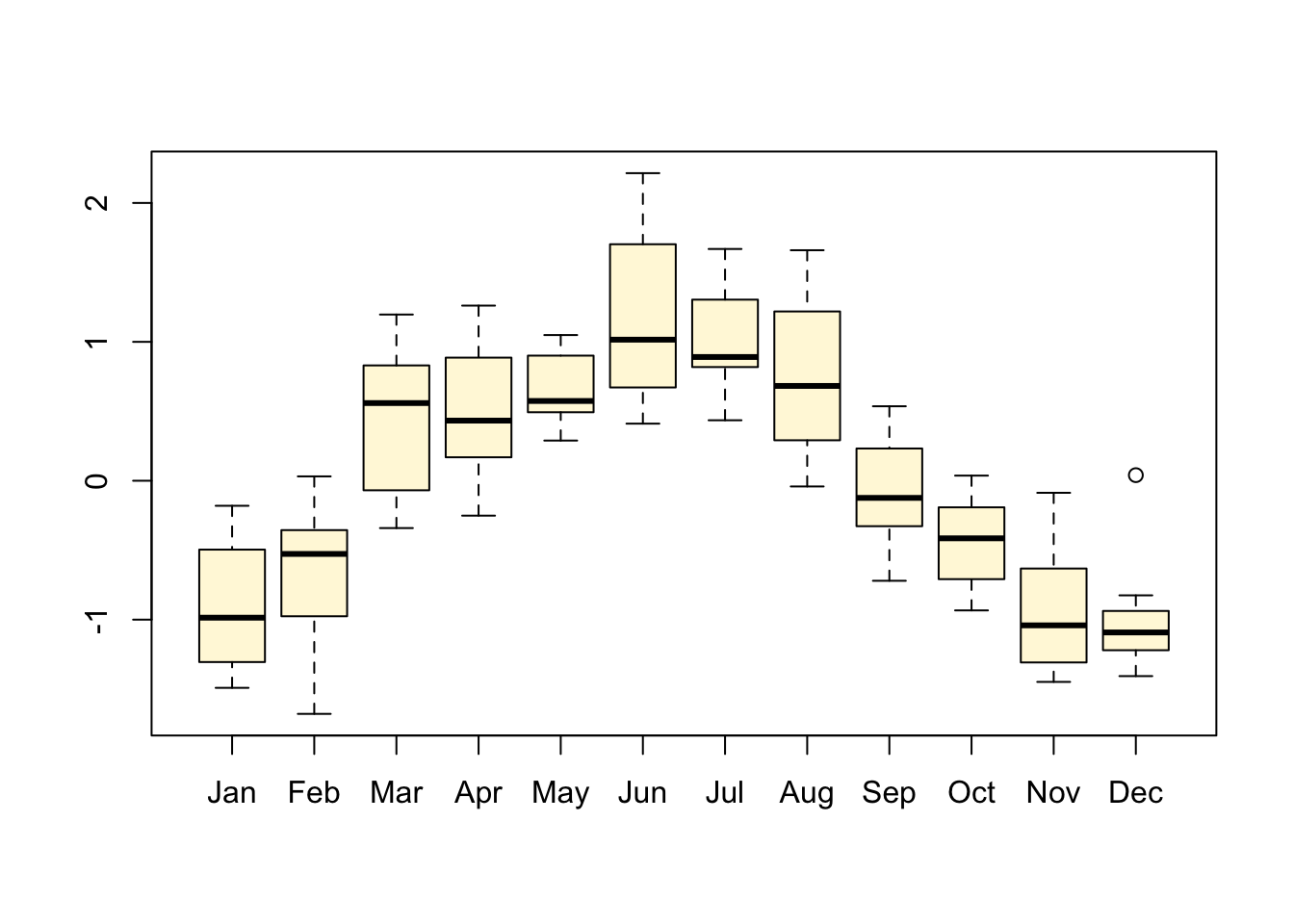
Une autre manipulation courante de l’axe temporel consiste à agréger les données en des pas de temps plus longs. aggregate() permet de réduire le nombre d’observations en diminuant la fréquence. Par exemple pour transformer la série tser qui a un pas de temps d’un mois en une série de pas de temps d’un trimestre, en calculant des moyennes trimestrielles, nous ferons (puisqu’il y a quatre trimestres dans une année, nous indiquons 4 ici) :
# Qtr1 Qtr2 Qtr3 Qtr4
# 1998 0.89782259 0.67904821 -0.69653303
# 1999 -0.18130440 0.94697099 0.83886989 -1.02778542
# 2000 -0.49373688 0.40422525 0.48177428 -0.54967060
# 2001 -0.66130180 0.96209455 0.37243904 -0.94522291
# 2002 -0.78807377 0.35774273 0.56682815 -0.79205726
# 2003 0.15125216 0.82518371 0.88998425 -0.65555249
# 2004 -0.10440672 0.56600131 0.83715933 -0.69680901
# 2005 -0.36724459 0.87511748 0.03531189 -0.93270486
# 2006 -0.59244763 1.14036661Notez encore une fois que R assume que l’unité de temps est l’année et il crée des intitulés particuliers pour des séries de fréquence égale à 4 (Qtr1 -> Qtr4) ou à 12 (intitulé des mois en abrégé).
Si nous ne souhaitons pas utiliser la série sur toute sa longueur, nous pouvons employer window() pour extraire une sous-série contenue dans une fenêtre de temps spécifique sans modifier la fréquence des observations. Par exemple, pour extraire les années 1999 à 2001 complètes de tser, on utilisera :
# Jan Feb Mar Apr May Jun
# 1999 -1.24312825 -0.49738897 1.19660403 0.05225123 0.57422522 2.21443653
# 2000 -1.27975774 -0.39864209 0.19718918 -0.25121656 0.79224043 0.67165187
# 2001 -1.33085705 -0.31227960 -0.34076874 1.26087821 0.90076680 0.72463865
# Jul Aug Sep Oct Nov Dec
# 1999 1.30384411 1.35349511 -0.14072954 -0.58534641 -1.44827029 -1.04973955
# 2000 1.27543290 0.27594795 -0.10605802 -0.42613394 -1.26309700 0.04021914
# 2001 0.43546515 0.99636669 -0.31451471 -0.36733500 -1.35331820 -1.11501552La fonction stats::lag() permet de décaler la série en arrière dans le temps (ou en avant si on fournit une valeur de décalage négative) ; nous l’avons déjà utilisée plus haut. La fonction diff() calcule la différence entre une série et elle-même décalée dans le temps de k observations. Les fonction ts.intersect() et ts.union() permettent de réunir deux ou plusieurs séries au sein d’une même matrice multivariée, avec une échelle de temps commune. Les fréquences respectives des séries à assembler doivent être identiques. Là où ts.intersect() retient uniquement l’intervalle de temps commun à toutes les séries, ts.union() conservera l’ensemble de l’intervalle temporel, toutes séries confondues.
Exercez-vous !
Manipulez et décrivez les différentes séries d’exemples. Notez par exemple que EEG est constituée de mesures effectuées à un rythme de 256 par seconde, mais que l’axe du temps reprend simplement les observations les unes après les autres (ou si vous préférez, une “unité” de temps de 1/256 sec et une fréquence de 1). Comment feriez-vous pour transformer cette série avec une unité de temps de la seconde ? Ou de la milliseconde ?