1.3 Analyse discriminante linéaire
Il existe de nombreux algorithmes de classification supervisée. Nous allons commencer notre exploration de ces outils statistiques avec l’analyse discriminante linéaire. Cette analyse recherche la meilleure discrimination possible des groupes par rotation des axes, en diagonalisant la matrice variance-covariance inter-groupe, ce qui revient à calculer les combinaisons linéaires des variables initiales qui séparent le mieux ces groupes.
Il n’est pas utile ici de rentrer dans les détails mathématiques. Comme vous connaissez déjà les variances inter/intra-groupes (cf. ANOVA) d’une part, et le principe de rotation des axes de l’ACP d’autre part, vous êtes à même de comprendre le principe de l’ADL en combinant ces deux notions. Pour quantifier la séparation des différents classes, nous allons donc réutiliser encore une fois la séparation de la variance totale en variance inter-groupe et variance intra-groupe que nous avons déjà employée dans l’ANOVA. Sauf qu’ici, nous travaillons en multivarié avec des matrices ayant potentiellement un grand nombre de dimensions. Du point de vue purement mathématique, cela ne change rien, car la partition de la variable s’applique tout aussi bien à N > 2 dimensions. Ensuite, nous nous intéressons aux distances inter-groupes. Notez que, plus ces distances sont importantes, mieux nous séparons les classes.
Pour rappel, l’ACP est une technique qui effectue la diagonalisation d’une matrice (matrice variance-covariance, ou matrice de corrélation des données). D’un point de vue géométrique, nous avons vu que diagonaliser une matrice revient en fait à effectuer une rotation du système d’axes représenté par cette matrice, de sorte que les nouveaux axes ainsi obtenus correspondent à une maximisation de la variance sur les premiers nouveaux axes. En ACP, on cherchait à “étaler” les données le plus possible sur les deux ou trois premiers axes afin de visualiser comment les points (les individus) se répartissent. Cela correspond donc bien à obtenir la part de variance maximale du jeu de données exprimée sur ces axes.
En ADL, on réutilise le même principe, mais nous substituons la matrice inter-groupe à la matrice variance-covariance pour effectuer cette ACP. Le résultat est une autre rotation des axes qui va maximiser, cette fois-ci, les distances inter-groupes… et donc, séparer au mieux linéairement les différentes classes (entendez par là, par une division à l’aide d’hyperplans qui sont les équivalents à N dimension de droites de séparation dans un plan à deux dimensions, voir schéma ci-dessous). Les hyperplans de séparations sont déterminés par rapport aux barycentres des différentes classes. En d’autres termes, ils sont placés à égale distance des centres de gravité des différents nuages de points dans la représentation en composantes principales de l’ADL.
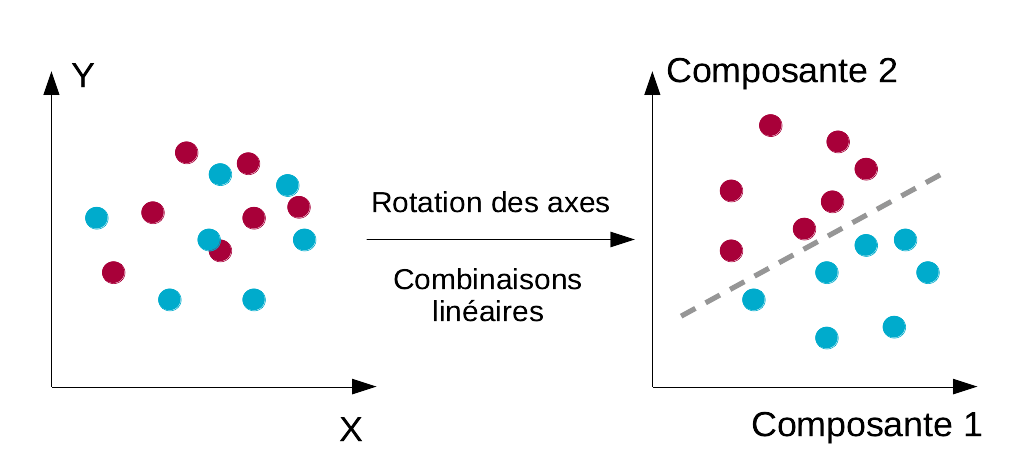
À partir de là, l’espace est divisé en plusieurs régions dont les frontières sont linéaires. Chaque région correspond à une classe. Il suffit alors de projeter de nouveaux individus dans cet espace (recalcul des coordonnées selon la rotation du système d’axes et représentation de ces coordonnées dans l’espace des individus de l’ADL). Nous regardons dans quelle sous-région nos points ont été se placer pour en déterminer la classe. Pour une autre explication, voyez ici.
Cet algorithme présente l’avantage d’être simple et rapide à calculer. Par contre, l’ADL n’est généralement pas la méthode la plus performante en classification supervisée, et elle impose que les différents groupes soient décrits par des sous-espaces uniques et délimités par des hyperplans dans l’hyperespace des p variables initiales, soit, une hypothèse de départ très forte. Il est possible de restreindre le classifieur à q < p composantes discriminantes principales, afin de simplifier et d’accélérer le calcul, si cela s’avère nécessaire (les détails sortent du cadre de ce cours).
1.3.1 Manchots antarctiques
Partons d’un exemple pratique sur trois populations de manchots adultes proches de la station de recherche PALMER en Antarctique. Mais avant de charger notre jeu de données, nous allons indiquer à R que nous voulons utiliser le dialecte SciViews, et également son module dédié au machine learning ("ml"en abrégé). Nous pouvons également indiquer que nous voulons utiliser le français pour les labels, unités et titres de graphiques et de tableaux partout où ce sera disponible avec lang = "fr". N’indiquez rien si vous voulez l’anglais car c’est la langue par défaut.
# ✓ Default language: fr
# ✓ Default data frame object (dtx): data.table# ── Attaching packages ───────────────────────────────────── SciViews::R 1.5.0 ──# ✓ rsample 0.1.1 ✓ ROCR 1.0.11
# ✓ recipes 0.2.0 ✓ mlearning 1.2.0
# ✓ parsnip 0.2.1# ── Conflicts ─────────────────────────────────────────── SciViews_conflicts() ──
# x data.table:::=() masks rlang:::=()
# x svFlow::!!() masks rlang::!!()
# x svMisc::?() masks utils::?()
# x dplyr::between() masks data.table::between()
# x collapse::D() masks stats::D()
# x dplyr::filter() masks stats::filter()
# x dplyr::first() masks data.table::first()
# x dplyr::lag() masks stats::lag()
# x dplyr::last() masks data.table::last()
# x dplyr::select() masks MASS::select()
# x parsnip::varying() masks collapse::varying()
# x data.io::write() masks base::write()R charge une série de packages qui constituent le dialecte SciViews, et il charge aussi des packages R spécifiques au machine learning, comme {mlearning} ou {recipes}. Dorénavant, leurs fonctions sont directement disponibles. Rappelez-vous bien d’utiliser cette instruction en début de script R ou de document R Markdown à chaque fois que vous voulez utiliser le dialecte SciViews::R. Une liste de conflits indique des fonctions homonymes dans différents packages, cellec chargéec plus haut masquant celles chargées plus bas. Ne vous en préoccupez pas parce que SciViews::R s’est arrangé pour que les fonctions que vous utiliserez ici soient celles qui sont directement disponibles. Nous pouvons maintenant lire le jeu de données penguins depuis le package {palmerpenguins} à l’aide de read() comme nous en avons l’habitude.
La fonction skimr::skim() nous donne un aperçu du contenu de ce jeu de données. Si vous voulez des informations supplémentaires, consultez la page d’aide du jeu de données ou palmerpenguins.
| Name | penguins |
| Number of rows | 344 |
| Number of columns | 8 |
| Key | NULL |
| _______________________ | |
| Column type frequency: | |
| factor | 3 |
| numeric | 5 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| species | 0 | 1.00 | FALSE | 3 | Ade: 152, Gen: 124, Chi: 68 |
| island | 0 | 1.00 | FALSE | 3 | Bis: 168, Dre: 124, Tor: 52 |
| sex | 11 | 0.97 | FALSE | 2 | mal: 168, fem: 165 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| bill_length_mm | 2 | 0.99 | 43.92 | 5.46 | 32.1 | 39.23 | 44.45 | 48.5 | 59.6 | ▃▇▇▆▁ |
| bill_depth_mm | 2 | 0.99 | 17.15 | 1.97 | 13.1 | 15.60 | 17.30 | 18.7 | 21.5 | ▅▅▇▇▂ |
| flipper_length_mm | 2 | 0.99 | 200.92 | 14.06 | 172.0 | 190.00 | 197.00 | 213.0 | 231.0 | ▂▇▃▅▂ |
| body_mass_g | 2 | 0.99 | 4201.75 | 801.95 | 2700.0 | 3550.00 | 4050.00 | 4750.0 | 6300.0 | ▃▇▆▃▂ |
| year | 0 | 1.00 | 2008.03 | 0.82 | 2007.0 | 2007.00 | 2008.00 | 2009.0 | 2009.0 | ▇▁▇▁▇ |
Ce jeu de données contient 8 variables et 344 individus. La variable que nous cherchons à prédire ici est species (variable réponse de type factor). Trois espèces de manchots sont étudiées :
- Adelie (152 individus)
- Gentoo (124 individus)
- Chinstrap (68 individus)
Bien que nous n’ayons pas un plan balancé (même nombre d’items pour chaque niveau de notre variable réponse), les différences restent encore acceptables, soit un peu plus du simple au double entre Chinstrap et Adelie. Nous pourrions sous-échantillonner les espèces les plus abondantes, mais nous diminuons alors la taille de notre jeu de données. Des techniques existent pour balancer le nombre d’items, dont la plus en vogue : SMOTE (“Synthetic Minority Over-sampling”). Elle peut s’avérer utile dans des cas plus problématiques. Nous poursuivrons ici sans modifier artificiellement le nombre d’items dans notre jeu de données.
En quoi un nombre différent d’items dans chaque classe peut-il poser problème en classification supervisée ? En fait comme le calcul du classifieur se base souvent sur une métrique globale, comme la minimisation de l’erreur totale, en cas de différences extrêmes dans les effectifs par classe, nous pourrions arriver à des situations paradoxales. Imaginez par exemple une maladie très rare. Si nous partons d’un échantillon aléatoire de la population, même important, nous auront énormément de patients sains, mais forcément très peu de cas positifs. Par exemple, 1,5% de notre set d’apprentissage est constitué de patients malades. Dans ce cas, un classifieur trivial qui classerait tout le monde comme sain ferait globalement 98,5% de prédictions correctes et notre métrique d’erreur totale serait de 1.5%. C’est difficile à battre, et en même temps pas très utile. Donc, deux points à retenir à partir de la réflexion sur ce cas fictif :
Toujours essayer de balancer les items dans les classes, mais sans exagération (une différence du simple au double est encore gérable, pour fixer les idées),
Le point de référence pour définir si un classifieur est efficace dépend de la classe la plus abondante. Avec un plan balancé à deux classes, un classifieur qui classe correctement 70% des items fait 20% mieux que le classement au hasard. Par contre, si la classe la plus abondante représente 75% du set, il fera moins bien de 5% qu’un classement purement au hasard (sic !)
On observe la présence de quelques données manquantes que nous supprimerons plus loin avant de faire notre analyse. Nous allons également renommer et donner un label à nos variables quantitatives (nos attributs).
penguins %<-% rename(penguins, # %<-% pour collecter" le résultat d'une fonctions tidy!
bill_length = bill_length_mm,
bill_depth = bill_depth_mm,
flipper_length = flipper_length_mm,
body_mass = body_mass_g)
penguins <- labelise(penguins,
label = list(
species = "Espèce", island = "Île", bill_length = "Longueur du bec",
bill_depth = "Épaisseur du bec", flipper_length = "Longueur des nageoires",
body_mass = "Masse", sex = "Sexe", year = "Année de la mesure"),
units = list(
bill_length = "mm", bill_depth = "mm", flipper_length = "mm",
body_mass = "g"))Nous nous intéressons uniquement pour l’instant aux variables explicatives numériques, et nous éliminons également les lignes du tableau qui contiennent des valeurs manquantes.
penguins %>.%
select(., -year, -island, -sex) %>.%
drop_na(.) %->% # %->% pour collecter les résultats de fonctions tidy à nouveau
penguinsdrop_na() (ou son équivalent dans la famille “speedy”, sdrop_na()) est bien pratique pour obtenir un tableau de données propre sans aucunes valeurs manquantes. Cependant, elle est assez impitoyable si les colonnes à considérer ne sont pas précisées : toute ligne du tableau qui contient au moins une valeur manquante est éliminée. Toujours sélectionner les valeurs que l’on veut retenir dans le modèle avant de l’appliquer, ou alors, préciser le nom des colonnes à utiliser. Sinon, on retirera aussi des lignes pour lesquelles les variables qui ne nous intéressent pas ont aussi des valeurs manquantes (ici, le sexe).
Le graphique ci-dessous trace un nuage de points pour voir si les trois espèces se différencient selon seulement deux variables. On observe une répartition assez bonne entre nos trois espèces pour les deux variables représentées. Ce graphique nous laisse penser que l’algorithme de classification a de grandes chances d’être efficace pour séparer ces trois espèces, car le jeu de donnée montre une tendance claire. N’oublions pas que nous avons au total quatre attributs à disposition et l’ADL utilisera toute cette information pour séparer les espèces encore mieux.
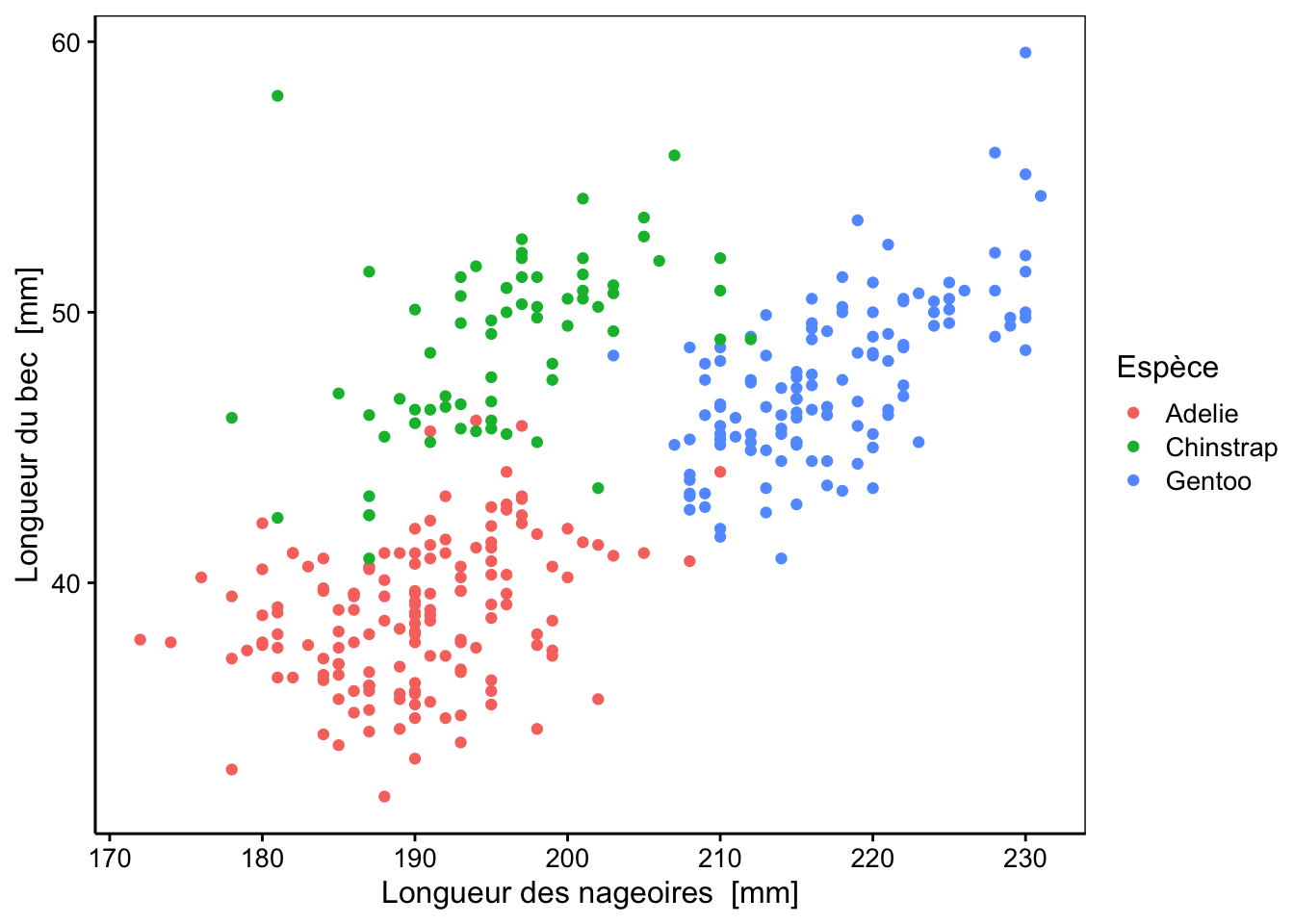
N’hésitez pas à explorer par vous-même ce jeu de données : il y a en effet pas mal de graphiques intéressants à réaliser avant de se lancer dans une analyse plus approfondie (boites de dispersion, matrice de corrélation ou de nuages de points …)
Le jeu de données est découpé en un set d’apprentissage et un set de test. Nous décidons de conserver 2/3 des observations pour le set d’apprentissage.
Très important : pensez bien toujours à préparer et remainer vos données avant la séparation en set d’apprentissage et set de test. Ainsi, vous vous assurez d’avoir deux tableaux compatibles. Les points à prendre en considération ici sont : (1) vérifier que la variable à prédire est bien sous forme factor (utilisez class(df$var) pour le déterminer si le tableau s’appelle df et la variable s’appelle var, ensuite utiliser df$var <- as.factor(df$var) si c’est nécessaire), (2) éliminer les variables inutilisées avec select() ou sselect(), (3) transformer les variables qui doivent l’être avec mutate() ou smutate() (transformation log, puissance, standardisation, etc., sachant que l’ADL apprécie les associations linéaires entre les variables), (4) éliminer éventuellement les données manquantes avec drop_na() ou sdrop_na() tout à la fin et vérifier ensuite qu’il reste suffisamment de données pour construire et tester notre classifieur. Notez bien que nous avons fait tout cela plus haut avec notre jeu de données exemple penguins.
Nous séparons nos observations en deux sets indépendants. Nous utilisons cependant la fonction set.seed() afin de fixer le début du générateur de nombres pseudo-aléatoires, ce qui donne une série de nombres qui ont les mêmes propriétés que des nombres tirés au sort, mais ce tirage au sort est reproductible à chaque fois que nous exécutons ce code (pensez naturellement à changer la valeur du “seed” à chaque fois que vous incluez cette fonction dans votre code. C’est une erreur grave que d’utiliser partout la même valeur !).
Ensuite, nous utilisons la fonction intial_split() en indiquant la fraction souhaitée dans le set d’apprentissage. De manière optionnelle, nous pouvons aussi indiquer strata = suivi du nom d’une variable du jeu de données (il s’agit souvent de la variable réponse elle-même) pour stratifier le sous-échantillonnage selon cette variable. Cela nous permet de garder les mêmes proportions pour chaque espèce de manchot dans le set d’apprentissage et le set de test. C’est donc très utile. Ensuite, les fonctions training() et testing() se chargent de récupérer les sous-tableaux d’apprentissage et de test.
set.seed(324)
penguins_split <- initial_split(penguins, 2/3, strata = species)
# Récupération du set d'apprentissage
penguins_train <- training(penguins_split)
# Récupération du set de test
penguins_test <- testing(penguins_split)Le set d’apprentissage a 227 items et le set de test a 115 individus. Les proportions entre espèces sont ici bien mieux respectée qu’un échantillonnage purement au hasard, non stratifié sur l’espèce (proportions identiques à l’unité près).
- Pour le set d’apprentissage :
#
# Adelie Chinstrap Gentoo
# 100 45 82- Pour le set de test :
#
# Adelie Chinstrap Gentoo
# 51 23 411.3.1.1 Apprentissage avec ADL
Nous utilisons le package {mlearning} pour réaliser notre analyse ici. Ce package est chargé automatiquement avec SciViews::R("ml"). La fonction mlLda() expose une interface que nous avons déjà employée à de nombreuses reprises. Il faut fournir le set d’apprentissage (data =) et la formule. Dans notre cas, nous souhaitons prédire l’espèce à l’aide de plusieurs attributs.
penguins_lda <- mlLda(data = penguins_train,
species ~ bill_length + bill_depth + flipper_length + body_mass)Cependant dans le cas particulier où toutes les variables du tableau sont utilisées pour l’analyse, comme c’est le cas ici, la formule peut être abrégée en class ~ ., ce qui signifie que la variable dépendante qualitative class (ou variable réponse) est étudiée en fonction de toutes les autres variables du tableau, considérées toutes comme des attributs. En fait, ce n’est pas tout à fait synonyme, car dans ce dernier cas, les fonctions du package {mlearning} utilisent des astuces de programmation pour optimiser les calculs (autant en vitesse qu’en utilisation de la mémoire vive). Il est donc très fortement conseillé d’utiliser cette dernière forme, ce qui nécessite d’avoir correctement nettoyé son jeu de données au préalable.
# Utilisation de la forme condensée de notre formule
penguins_lda <- mlLda(data = penguins_train, species ~ .)
penguins_lda# A mlearning object of class mlLda (linear discriminant analysis):
# Call: mlLda.formula(formula = species ~ ., data = penguins_train)
# Trained using 227 cases:
# Adelie Chinstrap Gentoo
# 100 45 82Nous pouvons visualiser nos données selon les deux premiers axes discriminants (notés LD1 et LD2) à l’aide du graphique suivant :
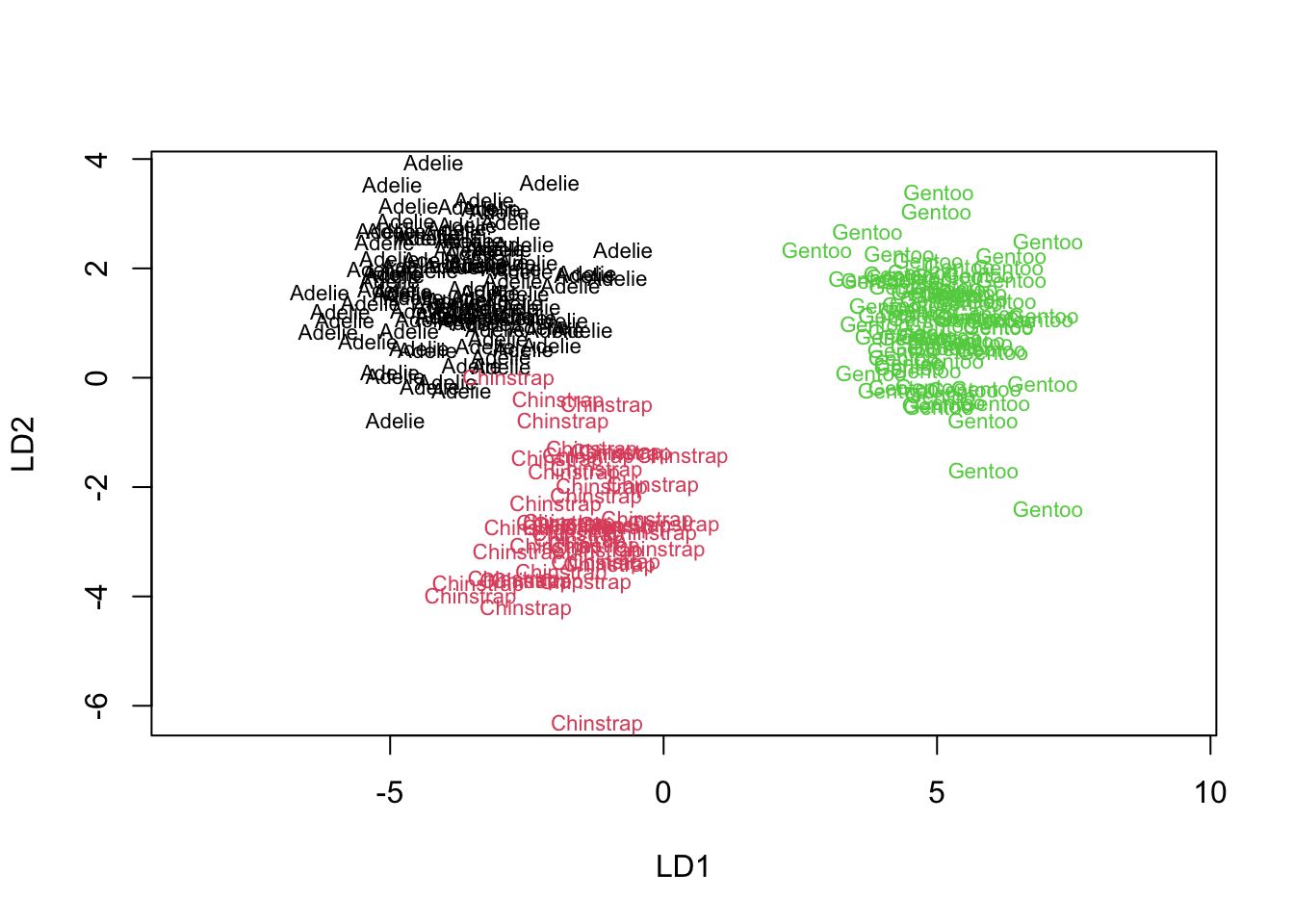
Nous voyons bien que la séparation est très bonne. Gentoo est très clairement séparé des deux autres, tandis que la frontière entre Chinstrap et Adelie est un peu moins nette, mais toutefois clairement visible.
Visualisation des sous-régions correspondant aux trois espèces dans un plan.
Bien que {mlearning} n’offre aucune fonction pour visualiser le découpage que réalise l’ADL pour décider à quelle classe un point appartient, nous pouvons la créer avec un peu de code en R (les détails de cette fonction vont au-delà de ce cours, mais si vous êtes curieux, vous pouvez inspecter le code pour comprendre comment elle fonctionne).
Pour visualiser ce qui se passe dans un plan à deux dimensions, nous allons refaire une prédiction à l’aide de deux variables seulement :
penguins_train2 %<-% select(penguins_train, flipper_length, bill_length, species)
penguins_lda2 <- mlLda(data = penguins_train2, species ~ .)
summary(penguins_lda2)# A mlearning object of class mlLda (linear discriminant analysis):
# Initial call: mlLda.formula(formula = species ~ ., data = penguins_train2)
# Call:
# lda(sapply(train, as.numeric), grouping = response, .args. = ..1)
#
# Prior probabilities of groups:
# Adelie Chinstrap Gentoo
# 0.4405286 0.1982379 0.3612335
#
# Group means:
# flipper_length bill_length
# Adelie 189.1400 38.5070
# Chinstrap 196.8667 49.4000
# Gentoo 216.2805 47.1439
#
# Coefficients of linear discriminants:
# LD1 LD2
# flipper_length 0.1185428 0.1240402
# bill_length 0.1413687 -0.3604124
#
# Proportion of trace:
# LD1 LD2
# 0.7214 0.2786Nous voyons que 72% de la variance interclasse est sur LD1 et 28% sur LD2. Un partitionnement dans le plan des variables de départ est obtenu comme suit :
# predplot() function inspired from MASS, chap. 12, p. 340
predplot <- function(object, main = "", len = 100, ...) {
pen_data <- as.data.frame(penguins_train2)
plot(pen_data[, 1], pen_data[, 2], type = "n", #log = "xy",
xlab = "Longueur des nageoires [mm]", ylab = "Longueur du bec [mm]", main = main)
for (il in 1:3) {
set <- pen_data$species == levels(pen_data$species)[il]
text(pen_data[set, 1], pen_data[set, 2],
labels = substr(as.character(pen_data$species[set]), 1, 3), col = 1 + il)
}
xp <- seq(170, 235, length = len)
yp <- seq(30, 60, length = len)
penT <- expand.grid(flipper_length = xp, bill_length = yp)
Z <- predict(object, penT, type = "both",...)
zp <- as.numeric(Z$class)
zp <- Z$membership[, 3] - pmax(Z$membership[, 2], Z$membership[, 1])
contour(xp, yp, matrix(zp, len), add = TRUE, levels = 0, labex = 0)
zp <- Z$membership[, 1] - pmax(Z$membership[, 2], Z$membership[, 3])
contour(xp, yp, matrix(zp, len), add = TRUE, levels = 0, labex = 0)
invisible()
}
predplot(penguins_lda2)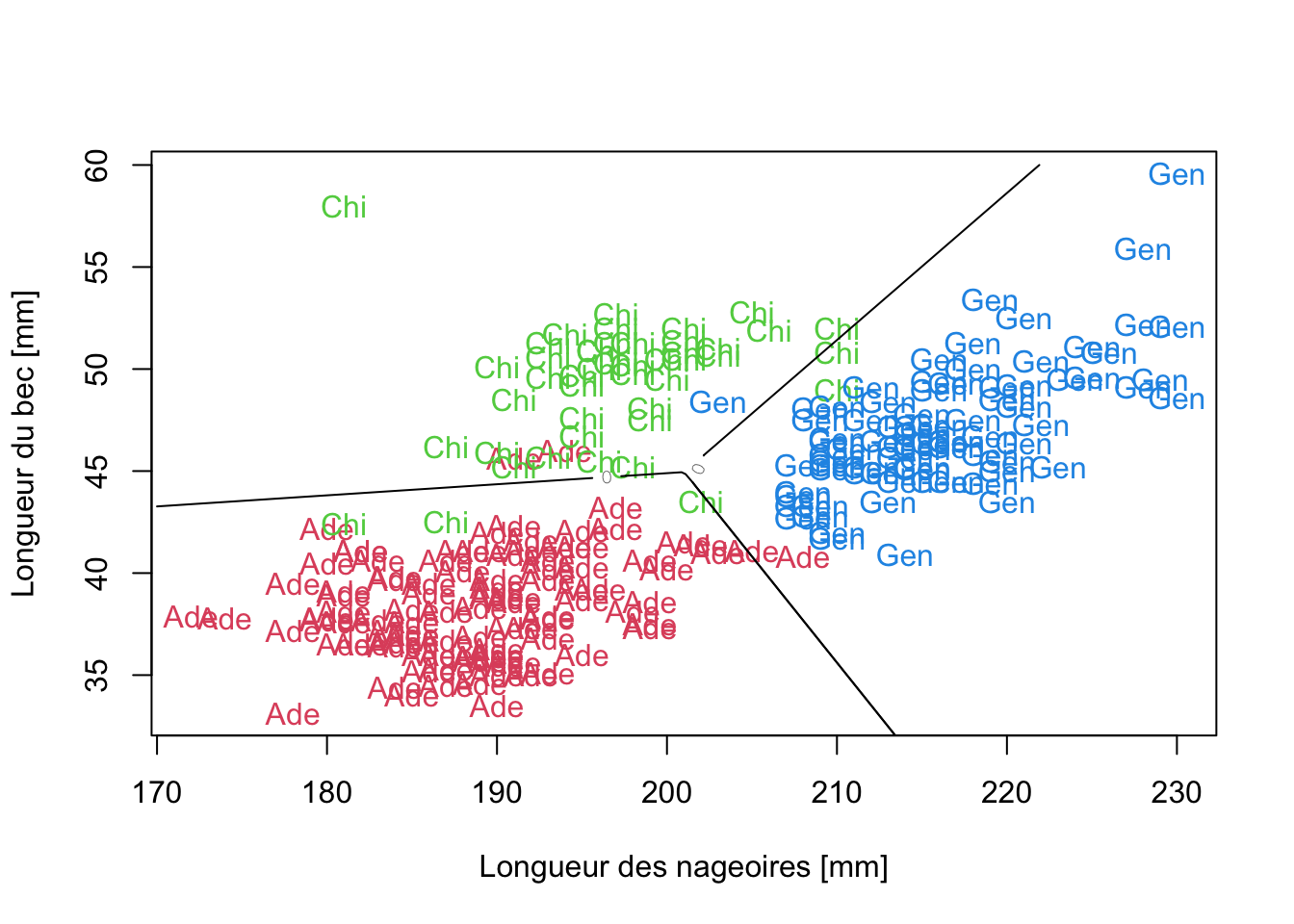
Nous distinguons clairement que le plan a été divisé en 3 parties séparées par des segments de droites pour en délimiter les frontières. C’est comme cela que fonctionne l’ADL.
1.3.1.2 Phase de test
Nous allons maintenant vérifier les performances de ce classifieur à l’aide de la matrice de confusion et des métriques que nous pouvons en dériver. Nous commençons par prédire les classes de notre set de test avec notre objet penguins_lda (fonction predict() tout simplement). Si elle est appliquée sur l’objet classifieur sans aucun autre argument, ce sont les items du set d’apprentissage qui sont classés, sinon, on rajoute comme second argument le nom du tableau (de test par exemple) dans l’argument newdata= (à ne surtout pas confondre avec un argument data= utilisé ailleurs) dont le nom est, ici, facultatif.
# [1] Adelie Adelie Adelie Adelie Adelie Adelie Adelie
# [8] Adelie Adelie Adelie Adelie Adelie Adelie Adelie
# [15] Adelie Adelie Adelie Adelie Adelie Adelie Adelie
# [22] Adelie Chinstrap Adelie Adelie Adelie Adelie Adelie
# [29] Adelie Adelie Adelie Adelie Adelie Adelie Adelie
# [36] Adelie Adelie Adelie Adelie Adelie Adelie Adelie
# [43] Chinstrap Adelie Adelie Adelie Adelie Adelie Adelie
# [50] Adelie Adelie Gentoo Gentoo Gentoo Gentoo Gentoo
# [57] Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo
# [64] Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo
# [71] Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo
# [78] Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo
# [85] Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo
# [92] Gentoo Chinstrap Chinstrap Chinstrap Chinstrap Chinstrap Chinstrap
# [99] Chinstrap Chinstrap Chinstrap Adelie Chinstrap Chinstrap Chinstrap
# [106] Chinstrap Chinstrap Adelie Chinstrap Chinstrap Chinstrap Chinstrap
# [113] Chinstrap Chinstrap Chinstrap
# Levels: Adelie Chinstrap GentooCet objet contient donc les 115 prédictions réalisées par notre classifieur. Nous réalisons un tableau de contingence à double entrée en croisant ces données avec les espèces déterminées par les spécialistes qui se trouvent dans la variable species de notre set de test (que le classifieur n’a, bien entendu pas utilisé pour faire ses prédictions). Dans le langage de la classification supervisée, ce tableau de contingence à double entrée s’appelle une matrice de confusion donc.
# Argument 1: prédictions, argument 2: valeurs connues pour `species`
penguins_conf <- confusion(penguins_pred, penguins_test$species)
penguins_conf# 115 items classified with 111 true positives (error rate = 3.5%)
# Predicted
# Actual 01 02 03 (sum) (FNR%)
# 01 Gentoo 41 0 0 41 0
# 02 Adelie 0 49 2 51 4
# 03 Chinstrap 0 2 21 23 9
# (sum) 41 51 23 115 3La fonction plot() appliquée à notre objet penguins_conf de classe confusion nous donne une présentation visuelle colorée plus facile à lire que le tableau textuel brut (pensez à des cas plus complexes avec beaucoup plus de classes).
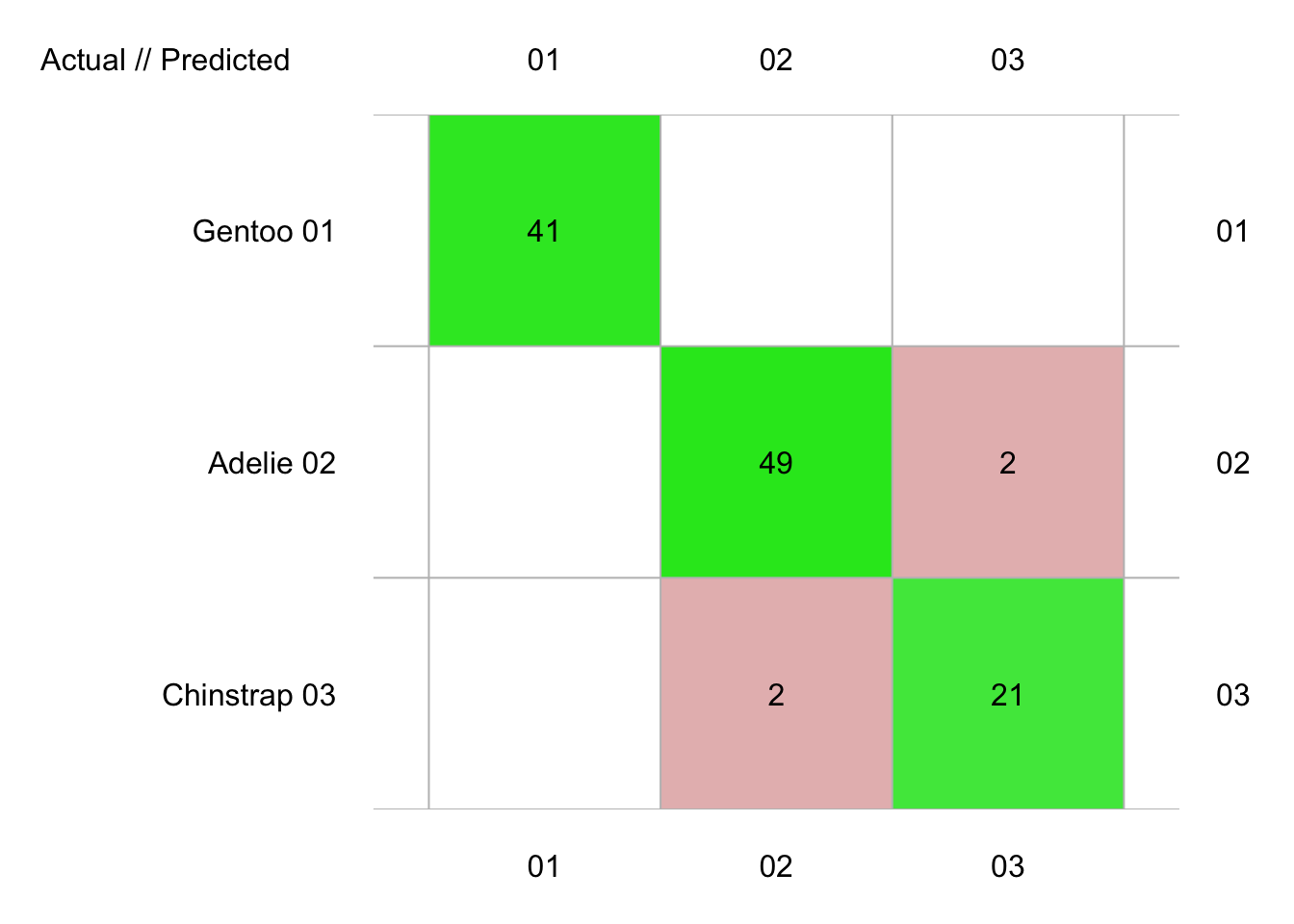
Notre classifieur a commis deux fois deux erreurs sur les données du set de test. Il semble que Gentoo puisse se classifier sans erreurs par rapport aux deux autres espèces, alors qu’une erreur (faible) subsiste dans la discrimination entre Adelie et Chinstrap. Nous obtiennons tout le détail des métriques que nous avons étudiées précédemment en faisant appel à la fonction summary().
# 115 items classified with 111 true positives (error = 3.5%)
#
# Global statistics on reweighted data:
# Error rate: 3.5%, F(micro-average): 0.958, F(macro-average): 0.958
#
# # A data.frame: 3 x 24
# ` ` Fscore Recall Precision Specificity NPV FPR FNR FDR FOR
# <rownam> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
# 1 Gentoo … 1 1 1 1 1 0 0 0 0
# 2 Adelie … 0.961 0.961 0.961 0.969 0.969 0.0312 0.0392 0.0392 0.0312
# 3 Chinstr… 0.913 0.913 0.913 0.978 0.978 0.0217 0.0870 0.0870 0.0217
# # … with 15 more variables: LRPT <dbl>, LRNT <dbl>, LRPS <dbl>, LRNS <dbl>,
# # BalAcc <dbl>, MCC <dbl>, Chisq <dbl>, Bray <dbl>, Auto <dbl>, Manu <dbl>,
# # A_M <dbl>, TP <int>, FP <dbl>, FN <dbl>, TN <dbl>À vous de jouer !
Effectuez maintenant les exercices du tutoriel C01Lb_ml1 (Première analyse discriminante linéaire).
BioDataScience3::run("C01Lb_ml1")Pièges et astuces
Tout comme cela avait déjà été expliqué lors de la présentation de l’ ACP, il est crucial de bien nettoyer son jeu de données avant de réaliser une ADL. Il est également très important de vérifier que les relations entre les variables prédictives (les attributs) sont linéaires dans le cas de l’analyse discriminante linéaire. Sinon, il faut transformer les données de manière appropriée. Rappelez-vous que l’ADL s’intéresse aux corrélations linéaires entre vos variables. Il existe d’autres variantes, comme l’analyse discriminante quadratique qui permet de traiter d’autres cas de figure, voir ici.
À vous de jouer !
Réalisez le travail C01Ia_debug.
Travail individuel pour les étudiants inscrits au cours de Science des Données Biologiques III à l’UMONS à terminer avant le 2022-10-10 12:30:00.
Initiez votre projet GitHub Classroom
Voyez les explications dans le fichier README.md.
1.3.1.3 Déploiement
Notre jeu de données ne reprenait que les données du set d’apprentissage et du set de test. Néanmoins, les scientifiques qui ont utilisé ces données pourraient légitimement considérer que le classifieur est suffisamment fiable pour pouvoir classer les trois espèces de manchots sur base des quatre mesures effectuées sur n’importe quel individu. Ainsi, s’ils possèdent par ailleurs des données biométriques sur les manchots de la région pour lesquelles il manque l’identification de l’espèce, ils pourraient utiliser leur classifieur pour les prédire. Si le jeu de donnée biométrique s’appelle par exemple palmer2data, ils feront predict(penguins_lda, palmer2data) pour obtenir une prédiction des espèces de manchots pour les individus repris dans palmer2data.
À vous de jouer !
Réalisez le travail C01Ib_lda.
Travail individuel pour les étudiants inscrits au cours de Science des Données Biologiques III à l’UMONS à terminer avant le 2022-10-13 12:30:00.
Initiez votre projet GitHub Classroom
Voyez les explications dans le fichier README.md.