8.2 Distribution d’échantillonnage
Pour rappel, nous faisons de l’inférence sur base d’un échantillon parce que nous sommes incapables de mesurer tous les individus d’une population. Il faut au préalable que l’échantillon soit représentatif, donc réalisé dans les règles de l’art (par exemple, un échantillonnage aléatoire simple de la population). Nous pouvons calculer la moyenne d’un échantillon facilement (eq. (8.1)).
\[\begin{equation} \bar{x}=\sum_{i=1}^n{\frac{x_i}{n}} \tag{8.1} \end{equation}\]où \(x\) est une variable quantitative (donc numeric dans R) et \(n\) est la taille de l’échantillon, c’est à dire, le nombre d’individus mesurés. On notera \(\bar{x}\) la moyenne de \(x\), que l’on prononcera “x barre”.
Nous utiliserons également l’écart type, noté \(\sigma_x\) pour la population et \(s_x\) pour l’échantillon qui se calcule sur base de la somme des écarts à la moyenne au carré (eq. (8.2)) :
\[\begin{equation} s_x = \sqrt{\sum_{i=1}^n{\frac{(x_i - \bar{x})^2}{n-1}}} \tag{8.2} \end{equation}\]À noter que \(s^2\) est également appelée la variance42.
En fait, ce qui nous intéresse, ce n’est pas vraiment la moyenne de l’échantillon, mais celle de la population que l’on notera \(\mu\)43.
À vous de jouer !
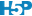
Nous pouvons nous demander comment varie la moyenne d’un échantillon à l’autre ? Il est possible de répondre à cette question de manière empirique en utilisant le générateur pseudo-aléatoire de R. Partons d’une distribution théorique de la population qui soit normale, de moyenne \(\mu\) = 8 et d’écart type \(\sigma\) = 2. Nous pouvons échantillonner neuf individus. Cela donne :
# [1] 9.138562 8.496824 9.573743 7.276562 8.300520 5.176688 4.209415
# [8] 10.700260 7.264703# [1] 7.793031Dans ce cas-ci, nous obtenons une moyenne de 7,8. Ce n’est pas égal à 8. Le hasard de l’échantillonnage en est responsable. La moyenne de l’échantillon tendra vers la moyenne de la population seulement lorsque \(n \longrightarrow \infty\). Réalisons un second échantillonnage fictif.
# [1] 8.660309Cette fois-ci, nous obtenons une moyenne de 8,7. Nous savons que la moyenne \(\mu\) qui nous intéresse est très probablement différente de la moyenne de notre échantillon, mais de combien ? Pour le déterminer, nous devons définir comment la moyenne de l’échantillon varie d’un échantillon à l’autre, c’est ce qu’on appelle la distribution d’échantillonnage. Nous pouvons le déterminer expérimentalement en échantillonnant un grand nombre de fois. On appelle cela une métaexpérience. En pratique, c’est difficile à faire, mais avec notre ordinateur et le générateur de nombres pseudo-aléatoires de R, pas de problèmes. Donc, comment se distribue la moyenne entre … disons dix mille échantillons différents de neuf individus tirés de la même population44 ?
means_n9 <- numeric(10000) # Vecteur de 10000 valeurs
for (i in 1:10000)
means_n9[i] <- mean(rnorm(9, mean = 8, sd = 2))
chart(data = NULL, ~ means_n9) +
geom_histogram(bins = 30)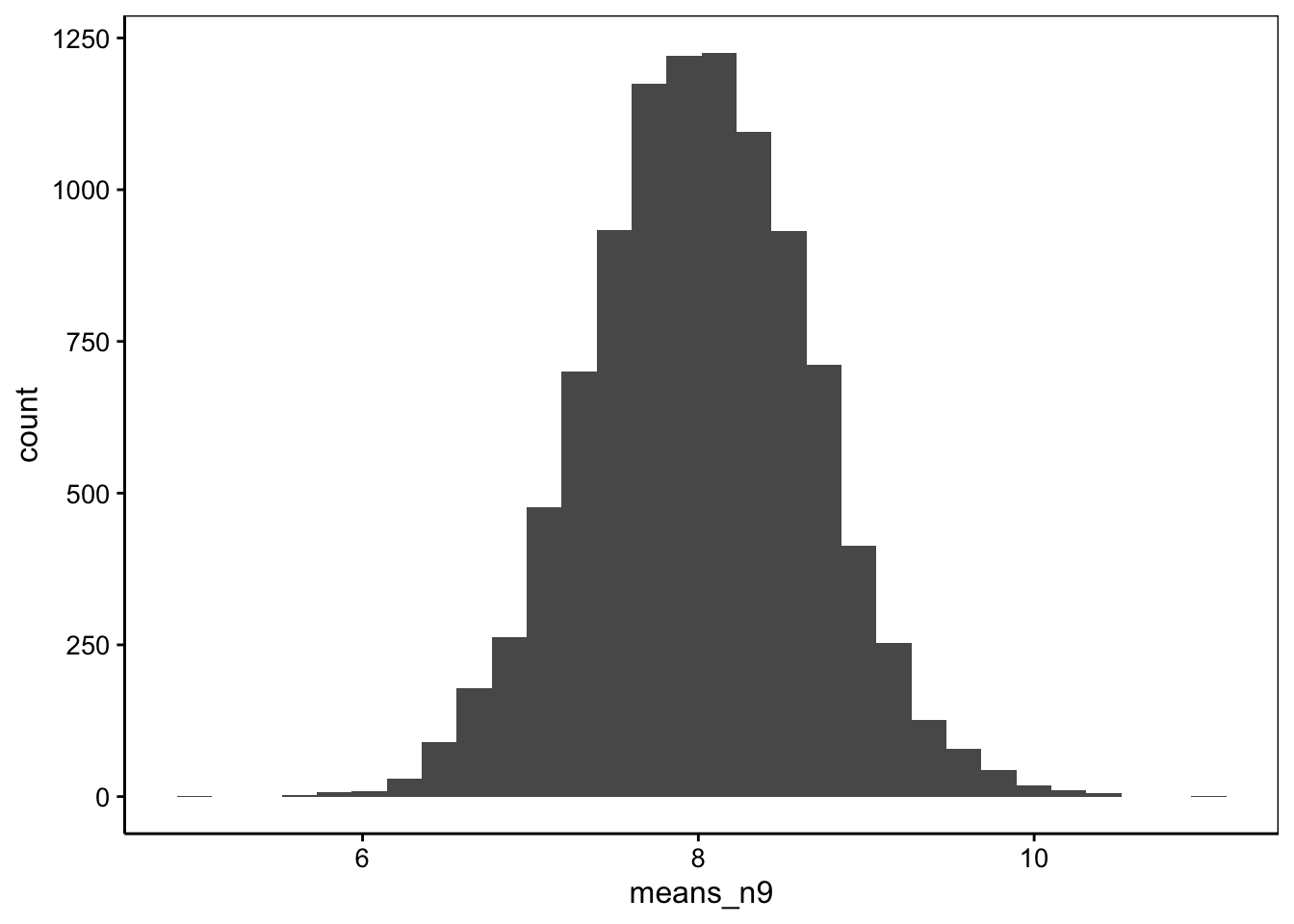
Nous obtenons une distribution symétrique centrée autour de 8. Cette distribution, nous la connaissons bien : c’est une distribution normale. Nous pourrions nous baser dessus à condition de connaitre \(\sigma_x\). Le hic, c’est que nous ne le connaissons pas plus que \(\mu_x\). Nous pouvons l’approximer à chaque fois en lui substituant \(s_x\), l’écart type de notre échantillon… mais ce faisant, nous introduisons une source supplémentaire de variation qui modifie la forme de la distribution. Le problème semble insoluble. C’est précisément ici que William Gosset intervient. Il est, en effet, arrivé à décrire cette loi de distribution de la moyenne d’échantillonnage en présence de l’estimation de l’écart type à l’aide de \(s_x\). C’est la distribution t de Student qui admet trois paramètres : des degrés de liberté ddl notés \(\nu\), une moyenne notée \(\mu\), un écart type noté \(\sigma\), et. Les degrés de liberté sont en lien avec la taille de l’échantillon. Ils valent :
\[ddl = n-1\]
Concernant la moyenne, et l’écart type, nous pouvons les estimer sur base de notre distribution d’échantillonnage empirique contenue dans le vecteur means_n9 :
# [1] 8.007725# [1] 0.6611474La moyenne de la distribution d’échantillonnage est donc égale à la moyenne de la population et nous avons vu qu’elle peut être approximée par la moyenne d’un échantillon. Quant à l’écart type, il vaut 2/3 environ, soit l’écart type de la population divisé par 3.
À vous de jouer !
Détaillons la métaexpérience toujours à partir de la même population, mais avec des échantillons plus petits, par exemple, avec \(n = 4\) :
means_n4 <- numeric(10000) # Vecteur de 10000 valeurs
for (i in 1:10000)
means_n4[i] <- mean(rnorm(4, mean = 8, sd = 2))
chart(data = NULL, ~ means_n4) +
geom_histogram(bins = 30)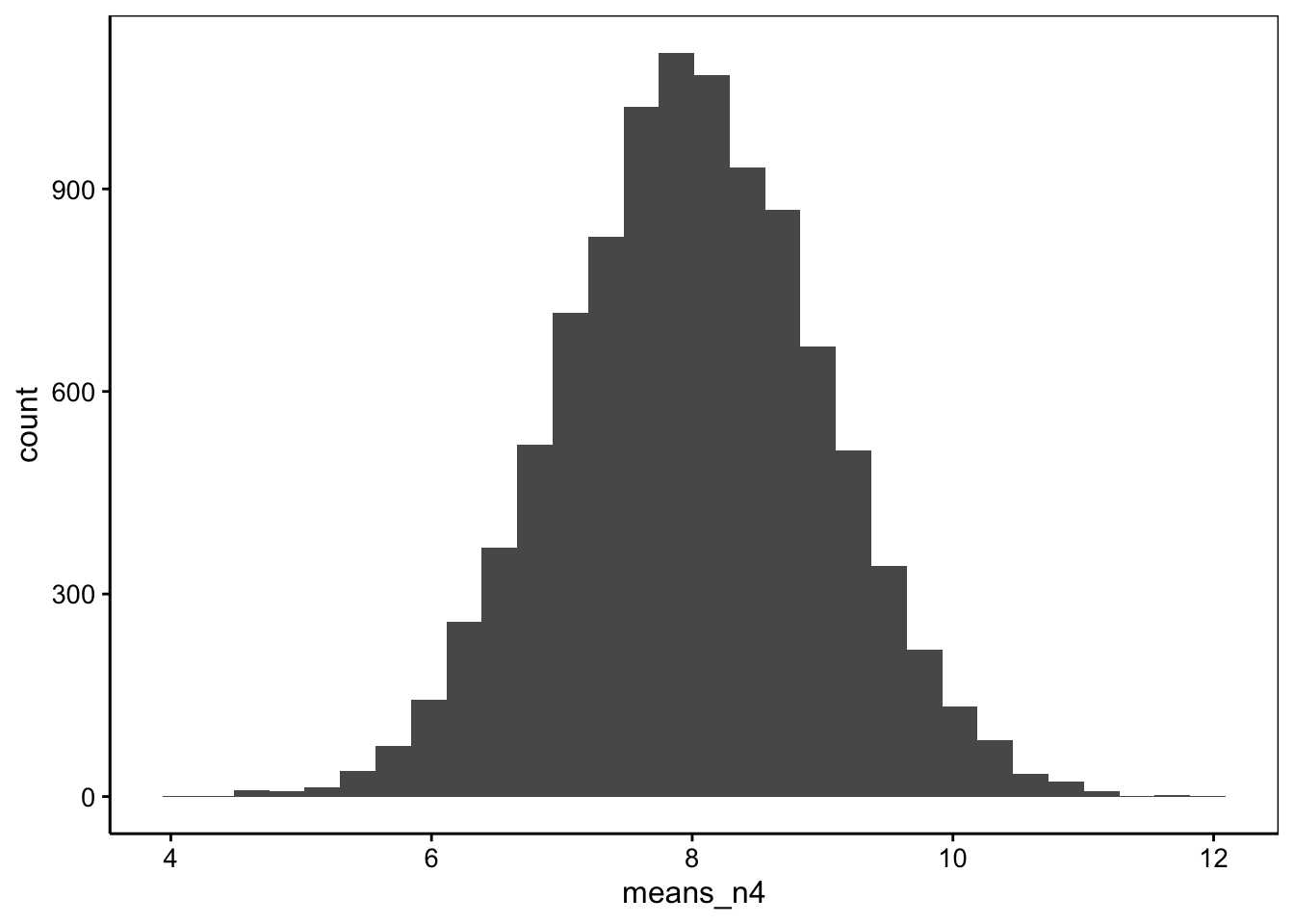
La distribution des moyennes des échantillons est toujours symétrique. En voici la moyenne et l’écart estimés à partir de notre métaexpérience :
# [1] 7.995668# [1] 1.002102La moyenne vaut toujours 8, mais cette fois-ci, l’écart type est plus grand, et il vaut 1, soit 2/2. Qu’est-ce que cela donne avec un échantillon nettement plus grand, disons \(n = 100\) ?
means_n100 <- numeric(10000) # Vecteur de 10000 valeurs
for (i in 1:10000)
means_n100[i] <- mean(rnorm(100, mean = 8, sd = 2))
chart(data = NULL, ~ means_n100) +
geom_histogram(bins = 30)
# [1] 7.999136# [1] 0.2005426On obtient toujours 8 comme moyenne, mais cette fois-ci, l’écart type est de 0,2, soit 2/10.
Pouvez-vous deviner comment l’écart type de la distribution t de Student varie sur base de ces trois métaexpériences ? Réfléchissez un petit peu avant de lire la suite.
La première bonne nouvelle, c’est que la moyenne des moyennes des échantillons vaut \(\mu_x = \mu\), la moyenne de la population que nous recherchons.
La seconde bonne nouvelle, c’est que la distribution des moyennes des échantillons est plus resserrée que la distribution d’origine. En fait, son écart type dépend à la fois de l’écart type de la population de départ et de \(n\), la taille de l’échantillon. Elle varie, en fait, comme \(\sigma_x = \frac{\sigma}{\sqrt{n}}\). Ainsi, avec \(n = 9\) nous obtenions \(\sigma_x = \frac{2}{\sqrt{9}} = \frac{2}{3}\) ; avec \(n = 4\), nous avions \(\sigma_x = \frac{2}{\sqrt{4}} = \frac{2}{2}\) ; enfin, avec \(n = 100\), nous observions \(\sigma_x = \frac{2}{\sqrt{100}} = \frac{2}{10}\).
8.2.1 Loi de distribution de Student
On dira :
\[\mu_x \sim t(n-1, \mu, \frac{\sigma}{\sqrt{n}})\]
La moyenne de l’échantillon suit une distribution t de Student avec comme degrés de liberté n moins un, comme moyenne, la moyenne de la population, et comme écart type, l’écart type de la population noté sigma divisé par la racine carrée de n. Ceci étant vrai lorsque \(\mu\) et \(\sigma\) sont estimés à partir de l’échantillon lui-même. La distribution t de Student dans R est représentée par <p|q|d|r>t(). Donc, qt() calcule un quantile à partir d’une probabilité, pt() une probabilité à partir d’un quantile, rt() renvoie un ou plusieurs nombres pseudo-aléatoires selon une distribution t, et dt() renvoie la densité de probabilité de la distribution.
Le calcul avec ces fonctions est un peu plus complexe, car les fonctions <p|q|r|d>t() ne considèrent que les distributions t de Student réduites (donc avec moyenne valant zéro et écart type de un). Nous devons ruser pour transformer le résultat en fonction des valeurs désirées. Considérons le cas \(n = 9\) avec une moyenne de 8 et un écart type de 2/3. Voici quelques exemples de calculs réalisables :
- Quelle est la probabilité que la moyenne d’un échantillon soit égale ou supérieure à 8,5 ?
# [1] 0.2373656Elle est de 24% environ. Notez que nous avons renseigné la moyenne et l’écart type de la distribution t dans mu et s, respectivement. Ensuite, les degrés de liberté (9 - 1) sont indiqués dans l’argument df =. Enfin, nous avons précisé lower.tail = FALSE pour obtenir l’aire à droite dans la distribution.
- Considérant une aire à gauche de 5%, quelle est la moyenne de l’échantillon qui la délimite ?
# [1] 6.760301Il s’agit du quantile 6,76. Tout cela est quand même un peu contraignant. Nous pouvons aussi utiliser la fonction dist_student_t() qui, elle, admet des arguments df=, mu= et sigma= afin d’effectuer les calculs pour n’importe quelle distribution t de Student, pas seulement la distribution réduite. Dans ce cas, les fonctions cdf() et quantile() ne permettent cependant pas de spécifier que l’on souhaite l’aire à droite, mais on se souvient que c’est égal à un moins l’aire à gauche.. Voilà ce que cela donne pour les deux calculs précédents :
student_t <- dist_student_t(df = 8, mu = 8, sigma = 2/3)
# Aire à droite du quantile 8.5 (1 - x car cdf() renvoie toujours l'aire à gauche)
1 - cdf(student_t, 8.5)# [1] 0.2373656# [1] 6.760301L’utilisation de dist_student_t() simplifie considérablement les calculs… mais <p|q|r|d>t() restent plus concis si votre calcul concerne la distribution t de Student réduite. Le graphique correspondant au dernier calcul est le suivant :
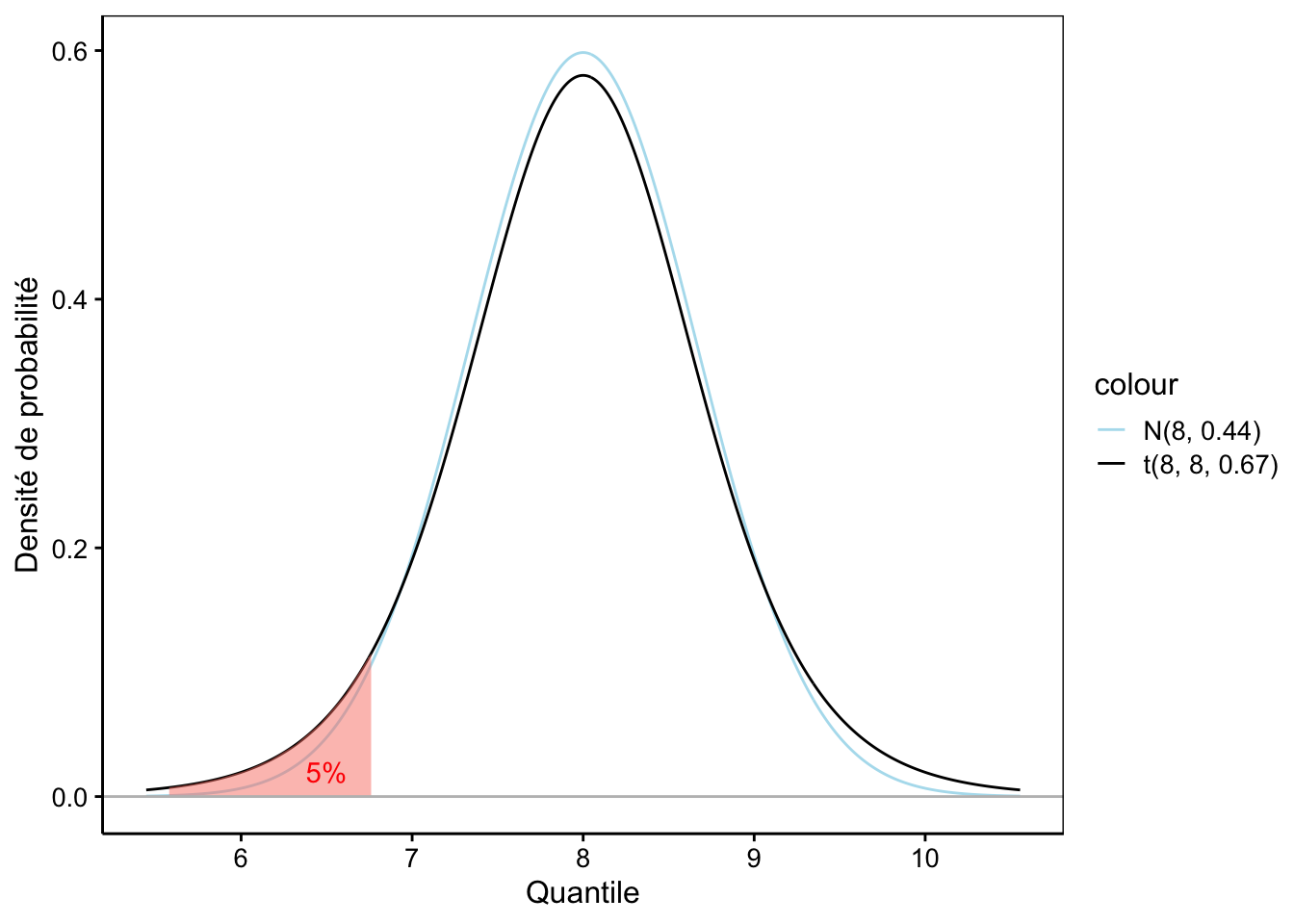
Figure 8.1: Une distribution de Student avec aire à gauche de 5% mise en évidence en rouge. La distribution Normale équivalente est superposée en bleu clair.
Nous pouvons voir sur la Fig. 8.1 que la distribution t de Student est plus resserrée en son centre, mais plus étalée aux extrémités que la distribution normale de même moyenne et écart type45. Néanmoins, elle est d’autant plus proche d’une normale que les degrés de liberté sont grands. On dit qu’elle converge vers une normale lorsque \(ddl \longrightarrow \infty\). En pratique, pour des degrés de liberté égaux ou supérieurs à 30, nous pourrons considérer que les deux distributions sont pratiquement confondues.
À vous de jouer !
Revenons à nos calculs de quantiles et probabilités. Les questions que l’on se posera seront plutôt :
- Quelle est la probabilité que la moyenne d’un échantillon diffère de 0,5 unité de la vraie valeur ? Au lieu de considérer l’aire à gauche ou à droite, on considérera une aire répartie symétriquement à moitié à gauche et à moitié à droite. La réponse à la question est :
# Aire à gauche de 8 +/- 0.5 :
student_t <- dist_student_t(df = 8, mu = 8, sigma = 2/3)
(left_area <- cdf(student_t, 7.5))# [1] 0.2373656# [1] 0.2373656# [1] 0.4747312Vous avez remarqué quelque chose de particulier ? Oui, les deux aires à gauche et à droite sont identiques. C’est parce que la distribution est symétrique. On peut donc simplifier le calcul en récupérant l’aire d’un seul côté et en multipliant le résultat par deux :
# [1] 0.4747312Dans l’autre sens, il suffit donc de diviser la probabilité (= l’aire) par deux, parce qu’elle se répartit à parts égales à gauche et à droite dans les régions les plus extrêmes de la distribution. Ainsi, les quantiles qui définissent une aire extrême de 5% dans notre distribution sont (notez que la valeur de probabilité utilisée ici est 0,025, soit 2,5%) :
# [1] 6.462664# [1] 9.537336On pourra aussi dire que la moyenne d’un échantillon de neuf observations issu de notre population théorique de référence sera comprise entre 6,5 et 9,5 (ou 8 ± 1,5) dans 95% des cas. La Fig. (ref?)(fig:tdistri2) le montre graphiquement.
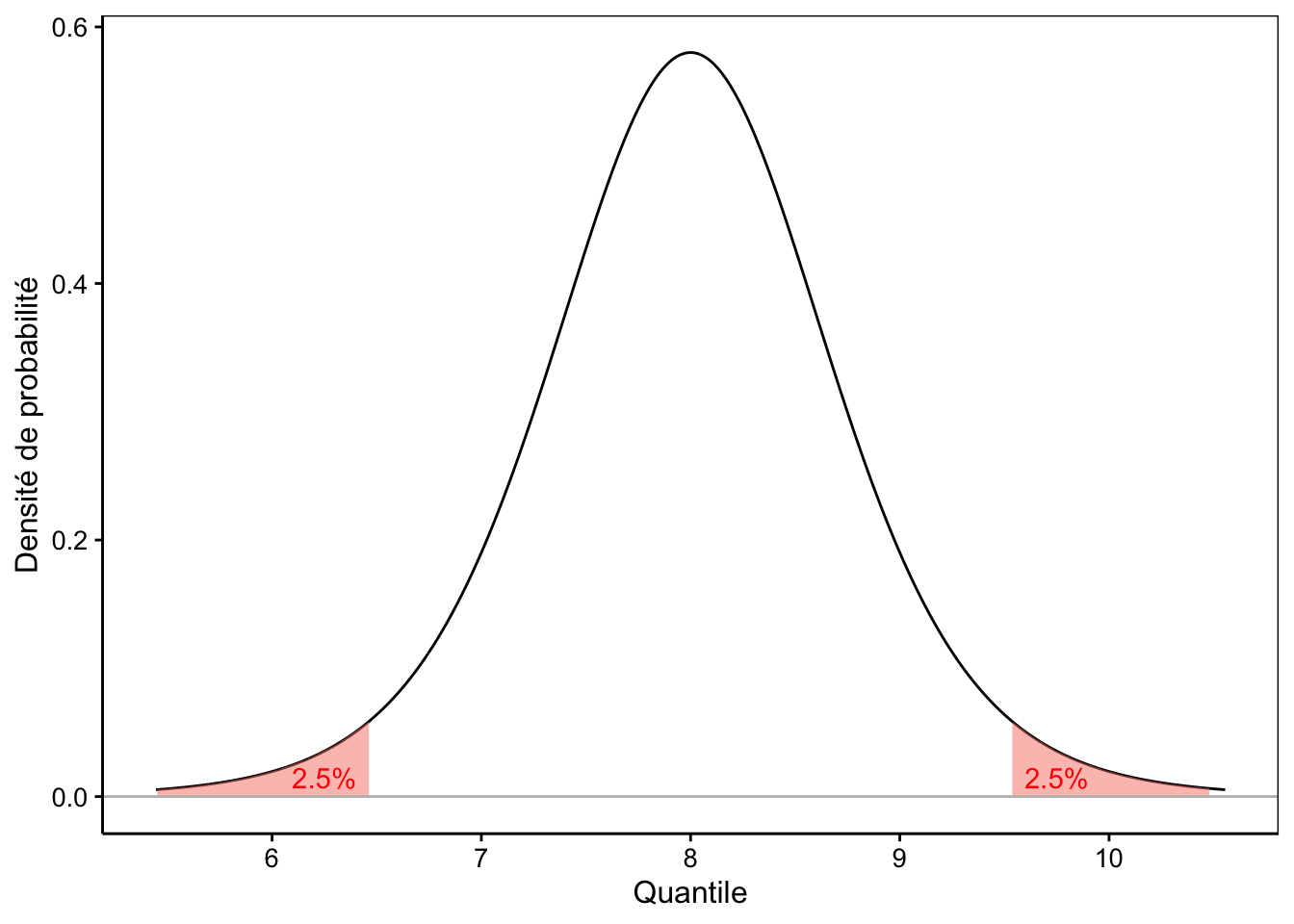
Figure 8.2: Une distribution de Student avec aire extrême de 5% mise en évidence en rouge.
8.2.2 Intervalle de confiance
Le dernier calcul que nous venons de faire (Fig. 8.2) correspond à ce que l’on nomme l’intervalle de confiance à 95% de la moyenne.
Un intervalle de confiance à x% autour d’une valeur estimée définit une zone à gauche et à droite de la valeur estimée telle que la vraie valeur se situe x% du temps dans cet intervalle.
En fait, la distribution est centrée sur \(\mu\), la valeur inconnue que l’on recherche, mais l’intervalle peut être translaté sur l’axe pour se centrer sur la moyenne \(\bar{x}\) d’un échantillon en particulier. Il définit alors une région sur l’axe qui comprend avec une probabilité correspondante, \(\mu\) la moyenne inconnue.
Avec ce nouvel outil, nous pouvons donc préciser nos estimations de la moyenne de la population \(\mu\) en associant à la valeur estimée via la moyenne de l’échantillon \(\bar{x}\) un intervalle de confiance. Si nous notons \(t_p^{n-1}\) le quantile correspondant à l’aire à gauche valant p pour une distribution t réduite de \(n-1\) degrés de liberté, on pourra écrire :
\[\mathrm{IC}(1 - \alpha) = \mu_x \pm t_{\alpha/2}^{n-1} \cdot \sigma_x\]
On notera aussi \(\hat{\mu}\) ou “mu chapeau” comme l’estimateur de \(\mu\), c’est-à-dire, la valeur que nous utilisons pour l’approximer au mieux. Ici, il s’agit de \(\bar{x}\), la moyenne de notre échantillon. De même, \(\hat{\sigma}\) est l’estimateur de l’écart type de la population. La valeur que nous avons à disposition est \(s_x\), l’écart type de notre échantillon. Nous pourrons aussi écrire :
\[\mathrm{IC}(1 - \alpha) \simeq \hat{\mu} \pm t_{\alpha/2}^{n-1} \cdot \frac{\hat{\sigma}}{\sqrt{n}}\]
… et en remplaçant les estimateurs :
\[\mathrm{IC}(1 - \alpha) \simeq \bar{x} \pm t_{\alpha/2}^{n-1} \cdot \frac{s_x}{\sqrt{n}}\]
Étant donné l’importance que revêt \(\frac{s_x}{\sqrt{n}}\), nous appellerons cette quantité erreur standard de x et nous la noterons \(SE_x\).
Nous pouvons tout aussi bien écrire :
\[\mathrm{IC}(1 - \alpha) \simeq \bar{x} \pm t_{\alpha/2}^{n-1} \cdot SE_x\]
Ce qui est intéressant avec ces deux dernières formulations, c’est que l’IC est calculable sur base de notre échantillon uniquement.
Analogie avec l’homme invisible qui promène son chien. Si vous avez des difficultés à comprendre l’IC, imaginez plutôt que vous recherchez l’homme invisible (c’est \(\mu\)). Vous ne savez pas où il est, mais vous savez qu’il promène son chien en laisse. Or, le chien est visible (c’est \(\bar{x}\) la moyenne de l’échantillon). La laisse est également invisible, mais vous connaissez sa longueur maximale (c’est votre IC). Donc, vous pouvez dire, voyant le chien que l’homme invisible est à distance maximale d’une longueur de laisse du chien.
Valeur α
Quel est l’impact du choix de \(\alpha\) sur le calcul de l’IC ? Plus \(\alpha\) sera petit, plus le risque de se tromper sera faible. Cela peut paraître intéressant, donc, de réduire \(\alpha\) le plus possible. Mais alors, la longueur de l’IC augmente. Si nous poussons à l’extrême, pour \(\alpha\) = 0%, nous aurons toujours un IC compris entre \(-\infty\) et \(+\infty\). Et cela, nous en sommes certains à 100% ! Trivial et pas très utile.
À vous de jouer !
Comme pour tout en statistique, nous devons accepter un certain risque de nous tromper si nous voulons obtenir des résultats utilisables. Plus ce risque est grand, plus la réponse est précise (ici, plus l’IC sera petit, voir Fig. 8.3), mais plus le risque de se tromper augmente. On cherchera alors un compromis qui se matérialise souvent par le choix de \(\alpha\) = 5%. Nous nous tromperons une fois sur vingt, et nous aurons un IC généralement raisonnable pour ce prix. Naturellement, rien ne vous oblige à utiliser 5%. Vous pouvez aussi choisir 1% ou 0,1% si vous voulez limiter les risques.
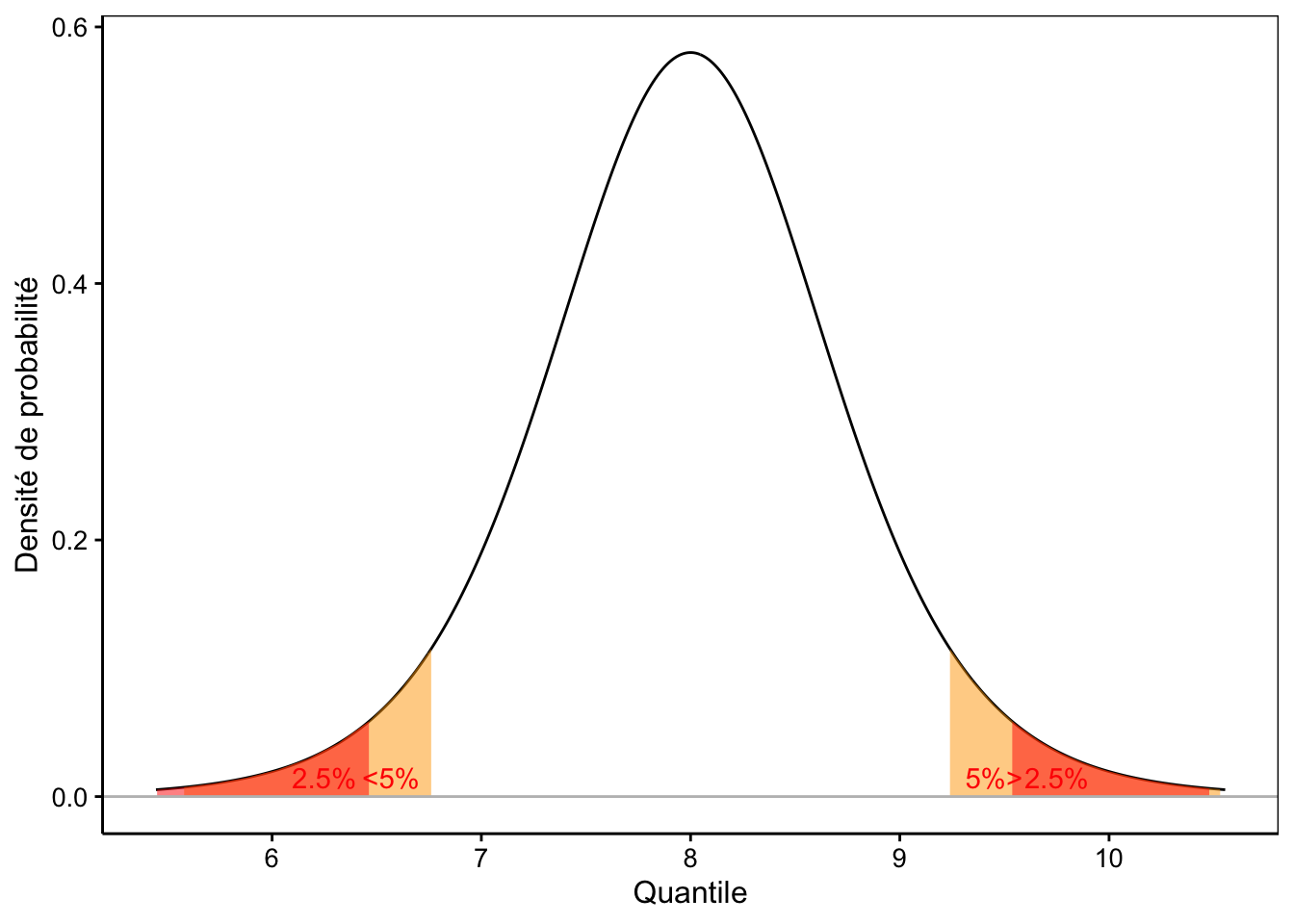
Figure 8.3: Une distribution de Student avec comparaison de l’IC 95% (entre les aires en rouge) et l’IC 90% (entre les aires en orange partiellement recouvertes par celles en rouge).
8.2.3 Théorème central limite (encore)
Jusqu’ici, nous avons considéré une population au départ qui a une distribution normale, mais rien ne dit que ce soit le cas. Que se passe-t-il lorsque la distribution est différente ? Ici encore, nous pouvons effectuer une métaexpérience. Considérons, par exemple, une distribution uniforme de même moyenne = 8 et écart type = 2 que précédemment. Sachant que l’écart type d’une distribution uniforme vaut \(\frac{max - min}{\sqrt{12}}\), voir ici, l’intervalle est de : \(2 \cdot \sqrt{12} = 6,928\). Nous avons donc :
# [1] 4.535898# [1] 11.4641Vérification :
# [1] 1.987185Quelle est la distribution de la moyenne d’échantillonnage lorsque \(n\) = 4 ?
set.seed(678336)
m_unif_n4 <- numeric(10000) # Vecteur de 10000 valeurs
for (i in 1:10000)
m_unif_n4[i] <- mean(runif(4, min = xmin, max = xmax))
## Distribution normale correspondante pour comparaison
mu <- 8
s <- 2/2
x <- seq(-4.5 * s + mu, 4.5 * s + mu, l = 1000) # Quantiles
normal1 <- dist_normal(mu = mu, sigma = s)
chart(data = NULL, ~ m_unif_n4) +
geom_histogram(bins = 30) +
geom_line(aes(x = x, y = dfun(normal1)(x) * 3000))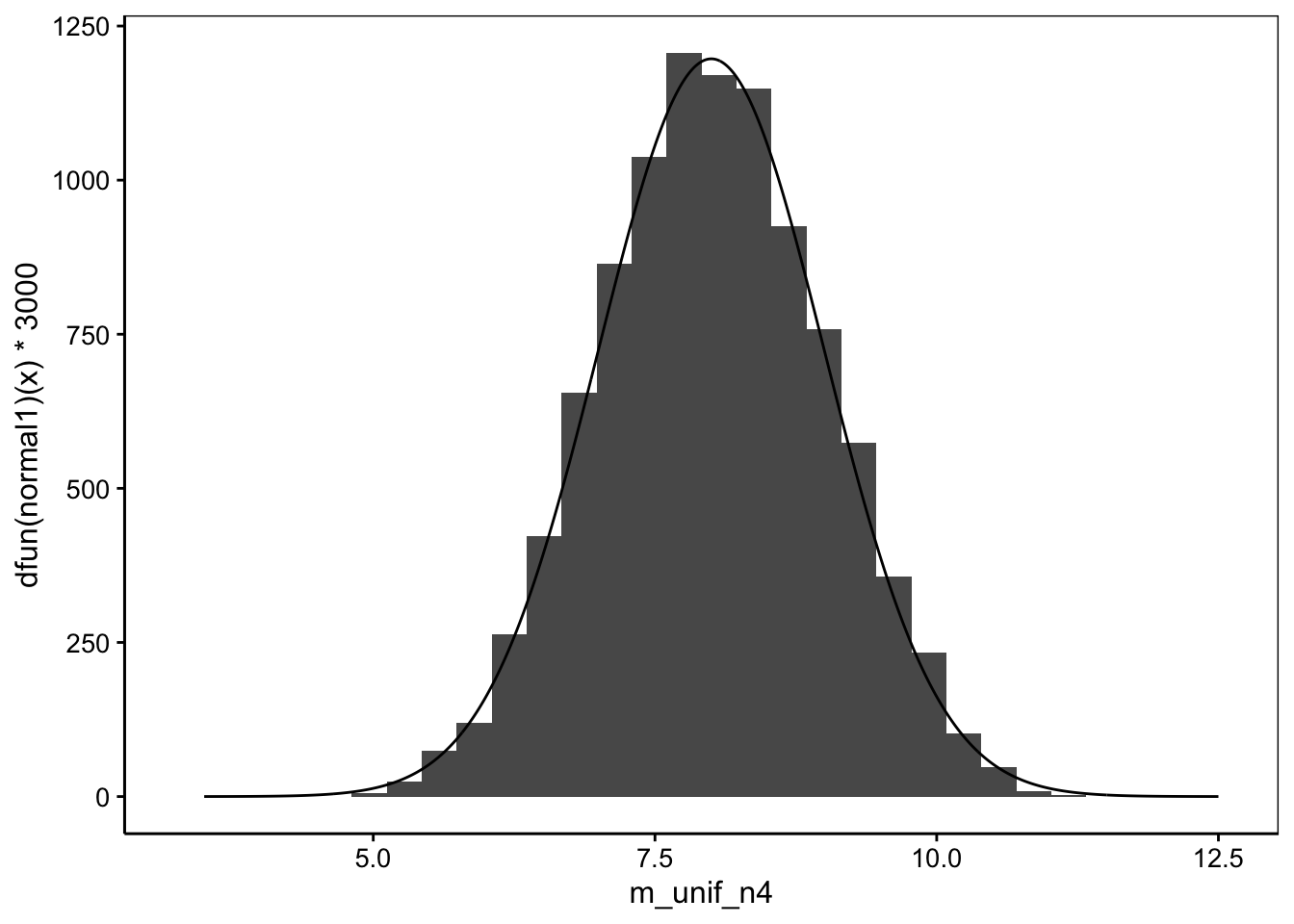
La moyenne de l’échantillon se distribue quand même selon une normale ! Nous venons de montrer de manière empirique que lorsque la distribution de la population est différente d’une distribution normale, la distribution d’échantillonnage tend quand même vers une distribution normale (en tous les cas, dans le cas d’une distribution de la population uniforme). Ceci se démontre de manière mathématique par le fameux théorème central limite que nous avons déjà abordé et qui est si cher aux statisticiens (nous vous épargnons cette démonstration ici). De plus, si l’écart type est également estimé à partir de l’échantillon, nous travaillerons avec une distribution t de Student de même moyenne et écart type, avec \(n-1\) degrés de liberté à la place de la distribution normale.
Conditions de validité de l’IC
L’IC sera pertinent si :
- l’échantillon est représentatif (par exemple, échantillonnage aléatoire),
- les observations au sein de l’échantillon sont indépendantes les unes des autres,
- la distribution de la population…
- est normale, alors l’IC basé sur la distribution t de Student sera exact,
- est approximativement normale, l’IC sera approximativement exact,
- est non normale, l’IC sera approximativement exact si \(n\) est grand.
L’équation proposée est, en fait, valable pour un échantillon et est calculée comme tel par R à l’aide des fonctions
sd()pour l’écart type ouvar()pour la variance. Pour la population ou pour un échantillon de taille très grande, voire infinie, nous pourrions plutôt diviser par \(n\) au lieu de \(n - 1\), … mais puisque \(n\) est très grand, cela ne change pas grand-chose au final.↩︎Notez que les lettres latines sont utilisées pour se référer aux variables et aux descripteurs statistiques telles que la moyenne pour l’échantillon, alors que les paramètres équivalents de la population, qui sont inconnus, sont représentés par des lettres grecques en statistiques.↩︎
Nous utilisons pour ce faire une boucle
fordans R qui réitère un calcul sur chaque élément d’un vecteur, ici, une séquence 1, 2, 3, …, 10000 obtenue à l’aide de l’instruction1:10000.↩︎Rappelez-vous que pour la distribution normale, le second paramètre est la variance et non l’écart type ce qui correspond à (2/3)^2 = 0,44.↩︎