4.3 Boite de dispersion
Vous souhaitez représenter graphiquement cette fois un résumé d’une variable numérique mesurée sur un nombre (relativement) important d’individus, soit depuis une dizaine jusqu’à plusieurs millions. Vous souhaitez également conserver de l’information sur la distribution des données, et voulez éventuellement comparer plusieurs distributions entre elles : soit différentes variables, soit différents niveaux d’une variable facteur. Nous avons déjà vu au module 3 les diagrammes en violon et en lignes de crêtes pour cet usage. Nous allons étudier ici les boites de dispersion (encore appelée boite à moustaches) comme option alternative intéressante. La boite de dispersion représentera graphiquement cinq descripteurs communément appelés les cinq nombres.
Considérez l’échantillon suivant :
1, 71, 55, 68, 78, 60, 83, 120, 82 ,53, 26Ordonnons-le de la plus petite à la plus grande valeur :
# Créer du vecteur
x <- c(1, 71, 55, 68, 78, 60, 83, 120, 82, 53, 26)
# Ordonner le vecteur par ordre croissant
sort(x)# [1] 1 26 53 55 60 68 71 78 82 83 120Le premier descripteur des cinq nombres est la médiane qui est la valeur se situant à la moitié des observations, donc, avec autant d’observations plus petites et d’observations plus grande qu’elle. La médiane sépare l’échantillon en deux.
# [1] 68En effet, nous voyons sur le vecteur ordonné que cinq valeurs sont plus petites que 68 et cinq valeurs sont plus grandes. Les quartiles séparent l’échantillon en quatre. Le premier quartile (Q1) sera la valeur pour laquelle 25% des observations seront plus petites. Elle se situe donc entre la valeur minimale et la médiane. Cette médiane est égale au second quartile (50% des observations plus petites). Le troisième quartile (Q3) est la valeur pour laquelle 75% des observations de l’échantillon sont plus petites13. Enfin, la valeur minimale et la valeur maximale observées dans l’échantillon complètent ces cinq nombres qui décrivent de manière synthétique la position et l’étendue des observations.
Voici comment on les calcules facilement dans R :
# [1] 1 54 68 80 120La boite de dispersion est une représentation graphique codifiée de ces cinq nombres. La représentation de x sous forme de nuage de points n’est ni très esthétique, ni très lisible, surtout si nous avons affaire à des milliers ou des millions d’observations qui se chevauchent sur le graphique14.
Figure 4.13: Nuage de points univarié.
La boite de dispersion va remplacer cette représentation peu lisible par un objet géométrique qui représente les cinq nombres.
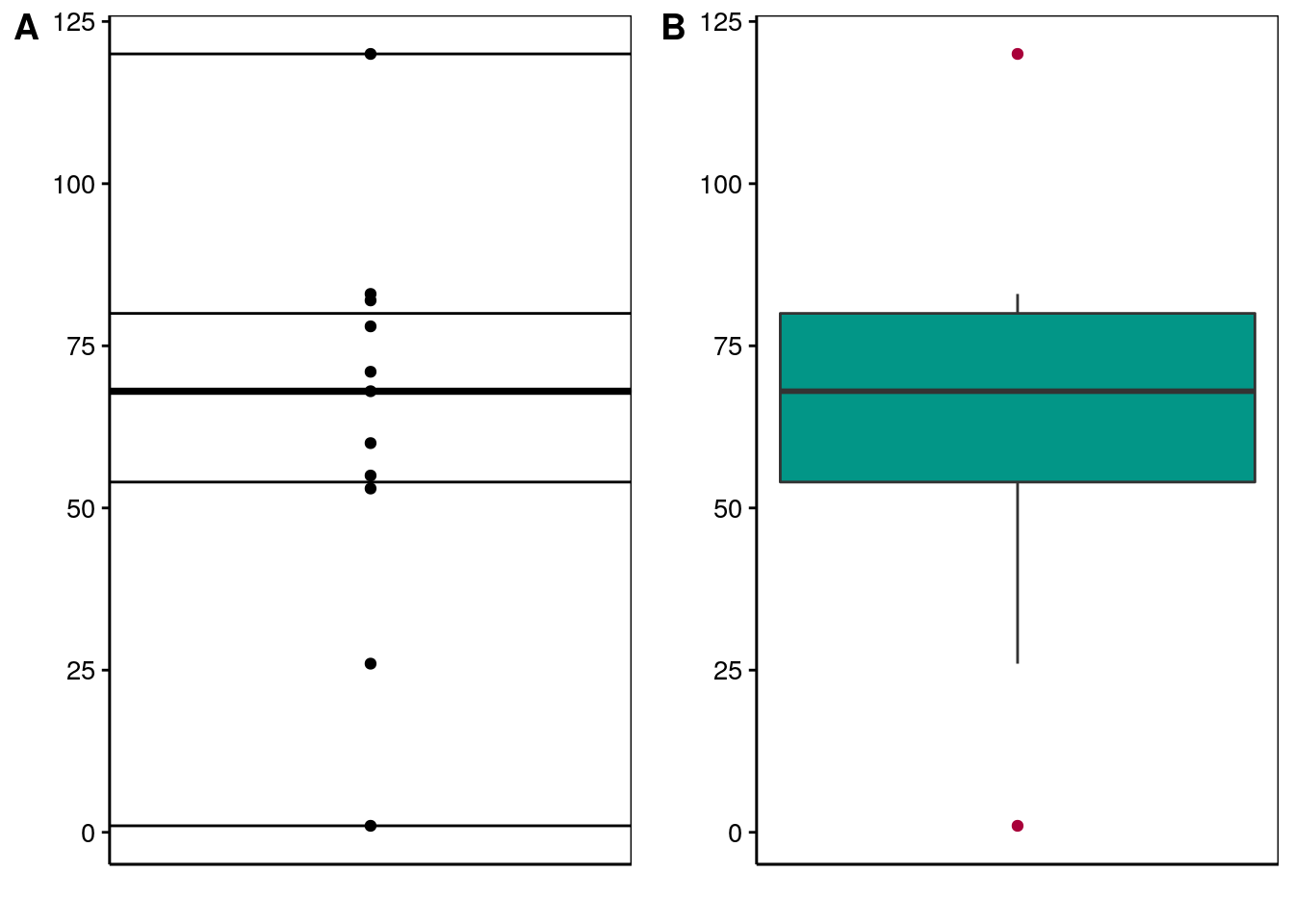
Figure 4.14: A) Nuage de points annoté avec les cinq nombres représentés par des traits horizontaux. B) Boite de dispersion obtenue pour les même données que A.
Vous observez à la Fig. 4.14 que certaines valeurs minimales et maximales ne sont pas reliées à la boite de dispersion, il s’agit de valeurs extrêmes.
La boite de dispersion finale ainsi que sa description sont représentées à la Fig. 4.15 ci-dessous.
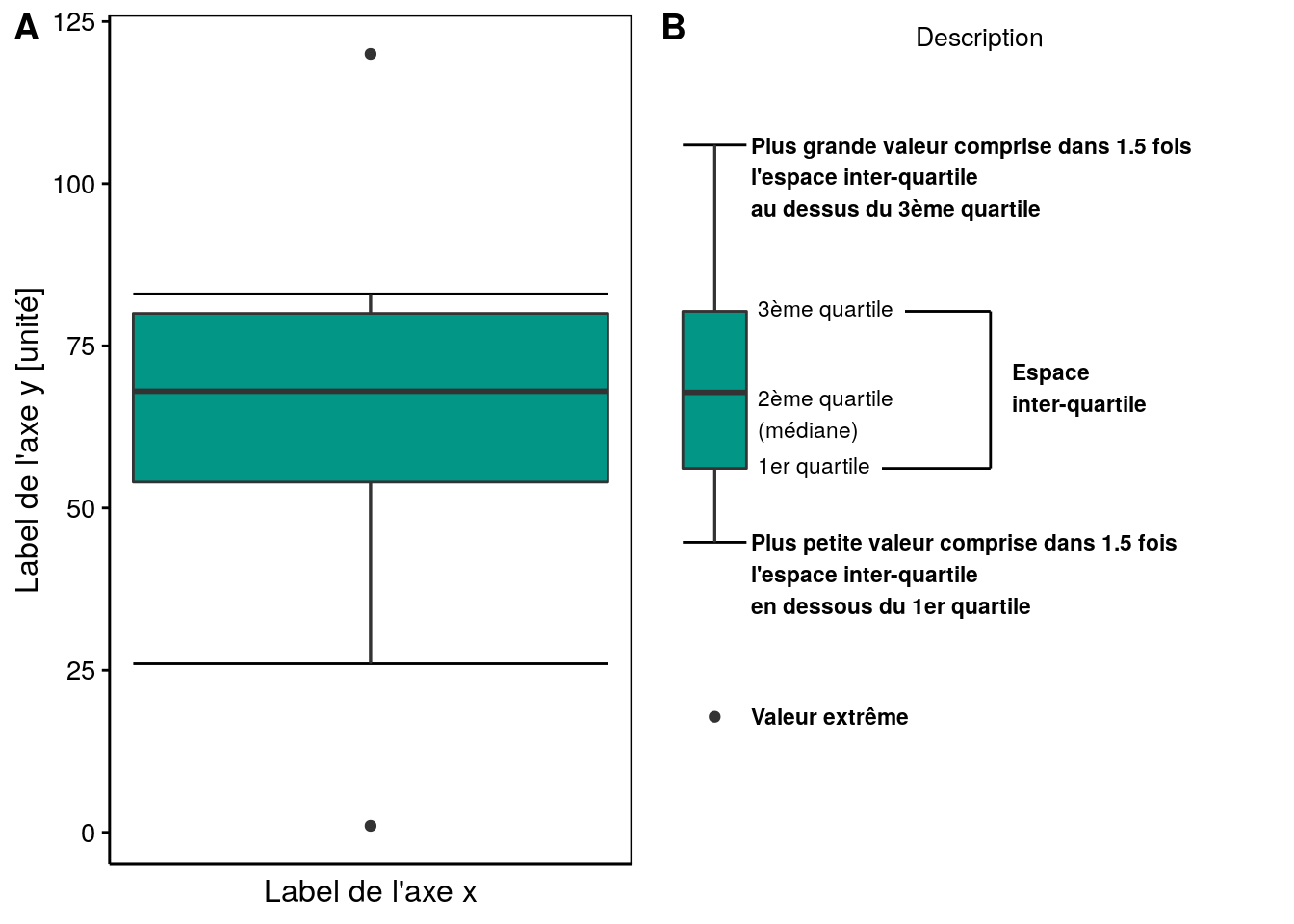
Figure 4.15: A) Boite de dispersion pour x et B) description des différents éléments constitutifs.
Un des gros avantages de la boite de dispersion est de mettre en évidence de manière synthétique la distribution des données sur l’axe. La boite de dispersion parallèle places plusieurs boites de dispersion côte à côte en face d’un même axe. C’est un excellent moyen de comparer la dispersion de données numériques en fonction des niveau d’une variable factor. Les instructions dans R pour produire un graphique en boites de dispersion parallèles sont :
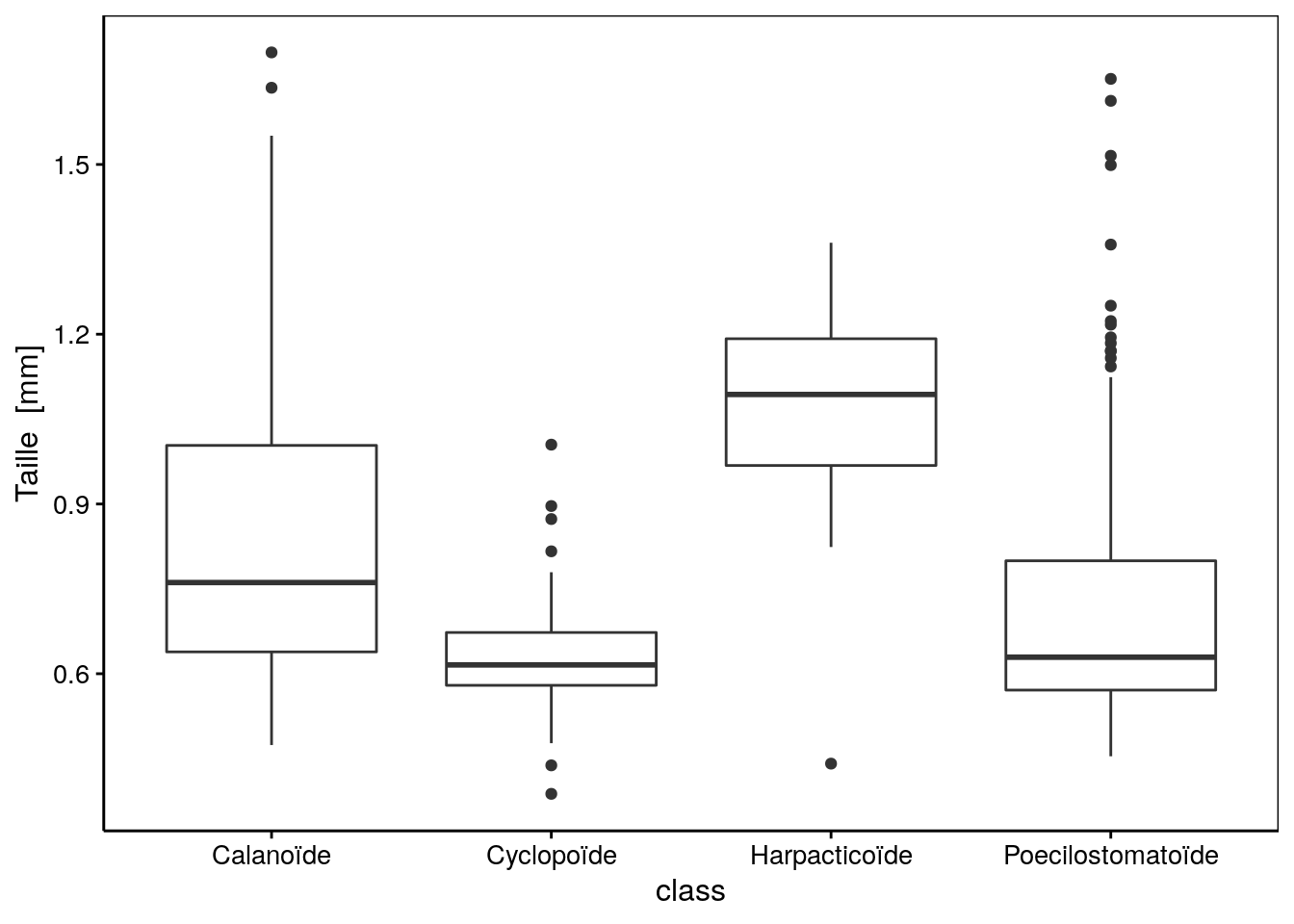
Figure 4.16: Distribution des tailles par groupes taxonomiques pour le zooplancton.
La formule à employer est YNUM (size) ~ XFACTOR (class). Ensuite, pour réaliser une boite de dispersion vous devez ajouter la fonction geom_boxplot().
4.3.1 Taille de l’échantillon
Lors de la réalisation de boites de dispersion, vous devez être vigilant au nombre d’observations qui se cachent sous chacune d’elles. En effet, réaliser une boite de dispersion à partir d’échantillons ne comportant que cinq valeurs ou moins n’a aucun sens !
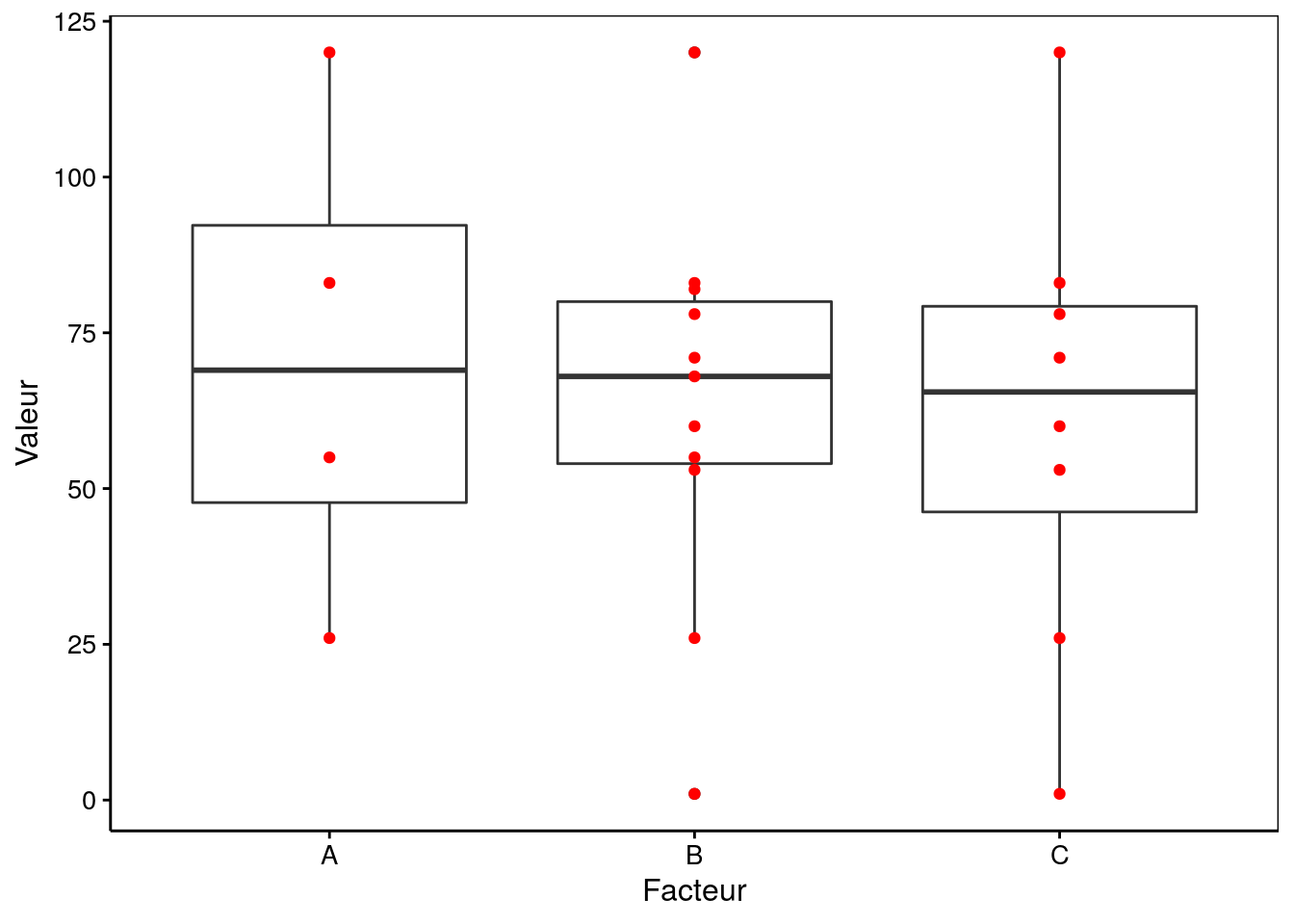
Figure 4.17: Piège des boites de dispersion : trop peu d’observations disponibles pour a.
La boite de dispersion pour le niveau A est calculée à partir de seulement quatre observations. C’est trop peu. Comme les points représentant les observations ne sont habituellement pas superposés à la boite, cela peut passer inaperçu et tromper le lecteur ! Une bonne pratique consiste à ajouter n, le nombre d’observations au-dessus de chaque boite. Cela peut se faire facilement avec les fonctions give_n() et stat_summary() ci-dessous15.
give_n <- function(x)
c(y = max(x) * 1.1, label = length(x))
chart(data = copepoda, size ~ class) +
geom_boxplot() +
stat_summary(fun.data = give_n, geom = "text", hjust = 0.5)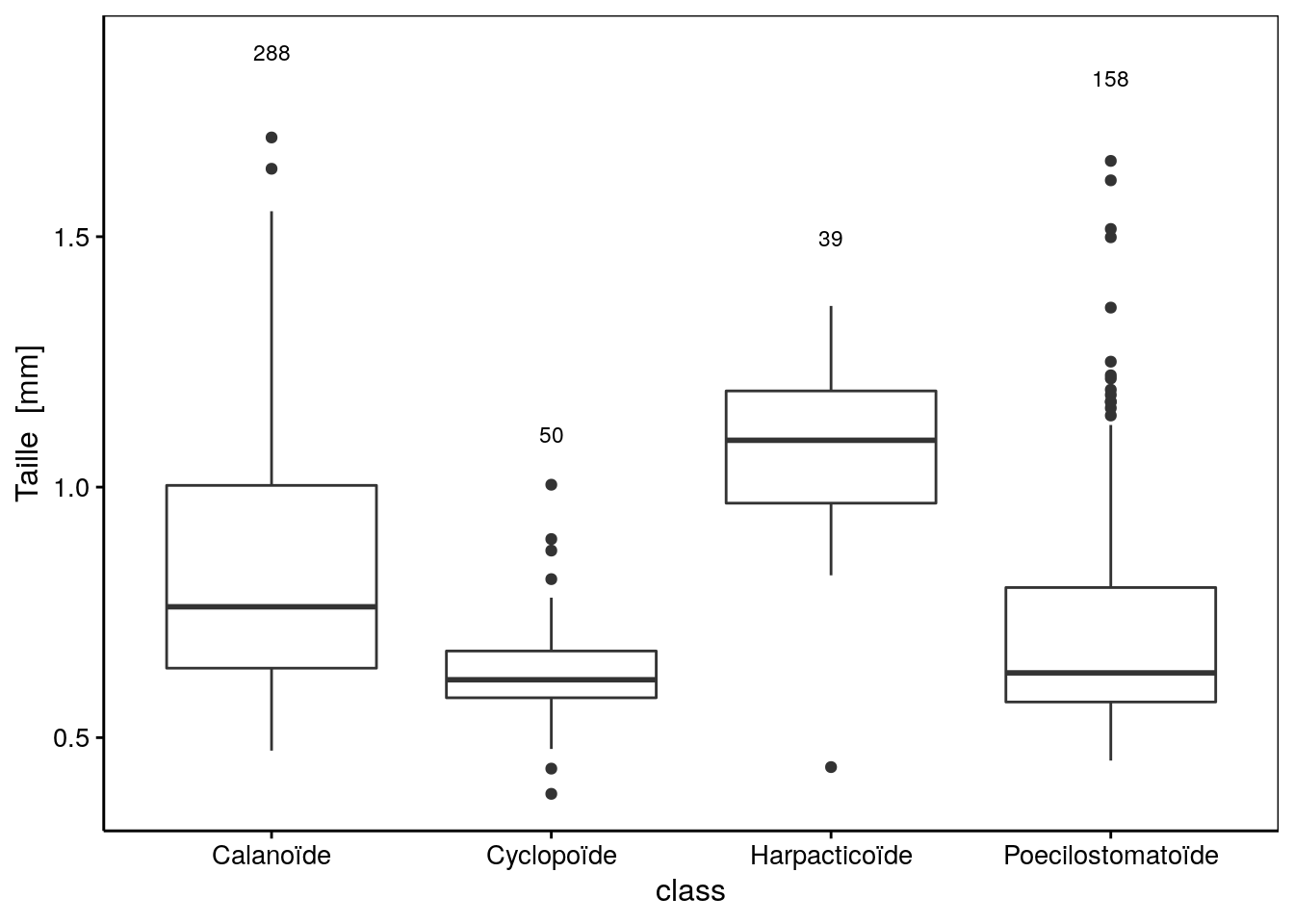
Figure 4.18: Taille de copépodes pour différents groupes taxonomiques (le nombre d’observations est indiqué au dessus de chaque boite).
La fonction stat_summary() ajoute des éléments à un graphique sur base d’un calcul. Ici, nous rajoutons du texte geom = "text", sur base du calcul effectué avec notre fonction give_n() définie plus haut. L’argument hjust = 0.5 indique simplement que le texte doit être justifié horizontalement à 0.5 (= centré, car 0 = justification à gauche, et 1 = justification à droite).
4.3.2 En fonction de deux facteurs
La Fig. 4.19 présente un graphique en boites de dispersion parallèles qui combine l’usage de deux variables facteurs différentes.
# Importation du jeu de données ToothGrowth
(tooth_growth <- read("ToothGrowth", package = "datasets"))# # A tibble: 60 x 3
# len supp dose
# <dbl> <fct> <dbl>
# 1 4.2 VC 0.5
# 2 11.5 VC 0.5
# 3 7.3 VC 0.5
# 4 5.8 VC 0.5
# 5 6.4 VC 0.5
# 6 10 VC 0.5
# 7 11.2 VC 0.5
# 8 11.2 VC 0.5
# 9 5.2 VC 0.5
# 10 7 VC 0.5
# # … with 50 more rows# Remaniement et labelisation du jeu de données
tooth_growth$dose <- as.ordered(tooth_growth$dose)
tooth_growth <- labelise(tooth_growth, self = FALSE,
label = list(
len = "Longueur des dents",
supp = "Supplémentation",
dose = "Dose"
),
units = list(
len = "mm",
supp = NA,
dose = "mg/J"
)
)Petits commentaires sur ce code :
La fonction
labelise()appliquée au tableau tout entier et avec l’argumentself= FALSEs’applique aux colonnes du tableau, c’est-à-dire aux variables. Ensuite, les argumentslabel=etunits=reçoivent unelist()nommée pour en modifier les attributs (nom = "valeur"). C’est une manière pratique et efficace de changer tous les labels et unités des variables en une seule étape (il n’est pas indispensable de reprendre toutes lesvariables, on peut indiquer seulement celles que l’on veut modifier).Nous avons utilisé
as.ordered()à la place deas.factor(). Les objets “facteurs ordonnés” dans R (ou ordered) sont identiques aux facteurs à ceci près que l’ordre de niveaux a aussi un sens du plus petit au plus grand. Ainsi, des niveaux desupp: soit “VC” pour vitamine C ou “OJ” pour vitamine C dans du jus d’orange n’ont pas d’ordre précis. Nous utilisons un objet factor. Par contre, les doses de vitamines C0.5 < 1 < 2exprimées en mg/J ont un ordre. Dans ce cas, nous préférons les objets ordered, qui s’utilisent en pratique comme les objets factor dans R (mais notez bien l’indication de l’ordre des niveaux de la variable à l’aide de<dansLevels:, c’est ce qui distingue un objet ordered d’un objet factor).
# [1] 0.5 0.5 0.5 0.5 0.5 0.5
# attr(,"label")
# [1] Dose
# attr(,"units")
# [1] mg/J
# Levels: 0.5 < 1 < 2# Réalisation du graphique (nous réutilisons give_n() ici!)
chart(data = tooth_growth, len ~ supp %fill=% dose) +
geom_boxplot() +
stat_summary(fun.data = give_n, geom = "text", hjust = 0.5,
position = position_dodge(0.75))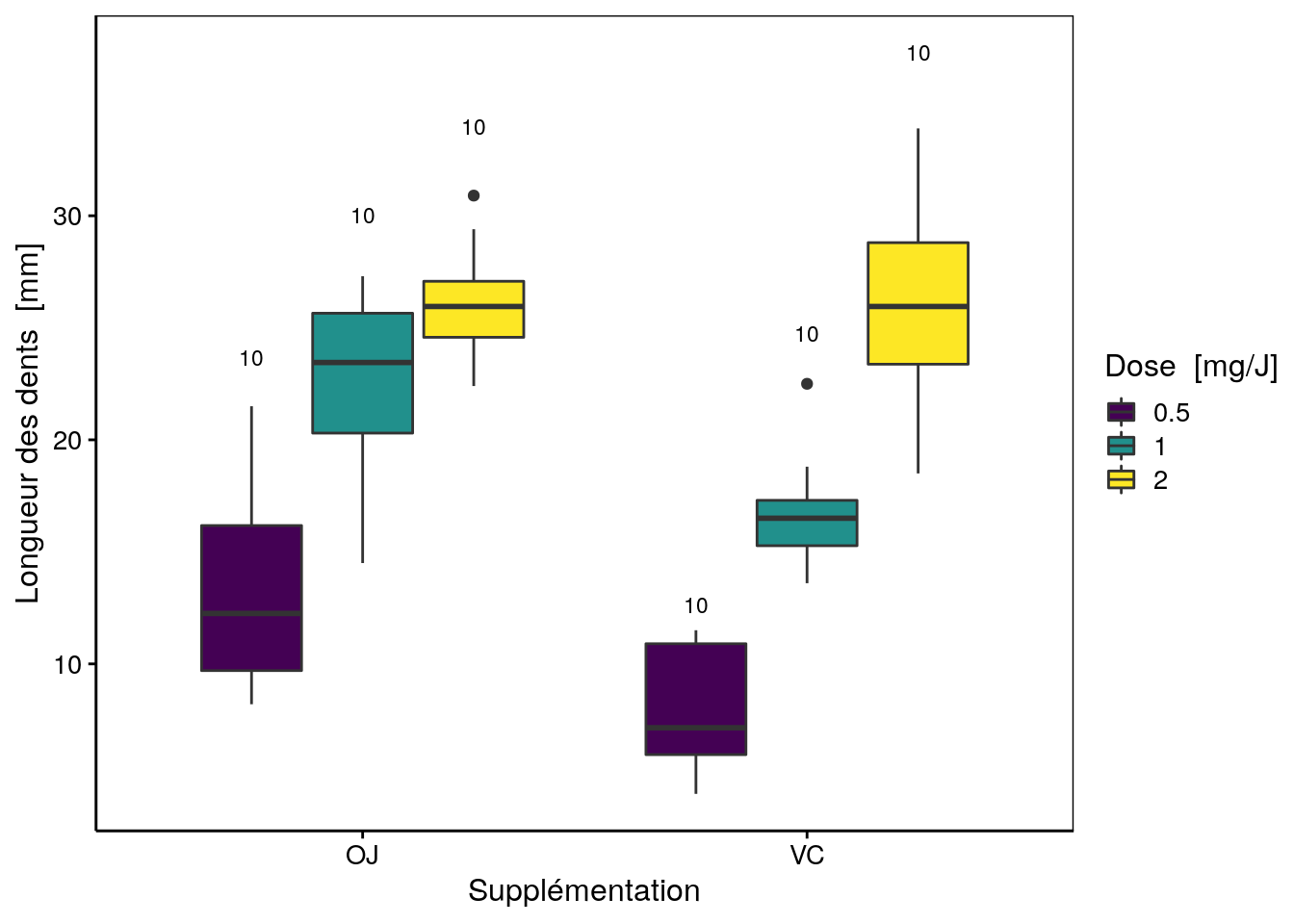
Figure 4.19: Croissance de dents de cochons d’Inde en fonction de la supplémentation (OJ = jus d’orange, VC = vitamine C) et de la dose administrée (nombre d’observations n indiqué au dessus de chaque boite).
À vous de jouer !
Effectuez maintenant les exercices du tutoriel A04Lc_boxplot (Boite de dispersion).
BioDataScience1::run("A04Lc_boxplot")Pour en savoir plus
Un tutoriel boites de dispersion à l’aide de
ggplot()présentant encore bien d’autres variantes possibles.Box plots in
ggplot2. Autre explication en anglais avec sortie utilisant {plotly}.Explication plus détaillée sur les cinq nombres, en anglais.
Notez que, lorsque la coupure tombe entre deux observations, une valeur intermédiaire est utilisée. Ici par exemple, le premier quartile est entre 53 et 55, donc, il vaut 54. Le troisième quartile se situe entre 78 et 82. Il vaut donc 80.↩︎
Il est possible de modifier la transparence des points et/ou de les déplacer légèrement vers la gauche ou vers la droite de manière aléatoire pour résoudre le problème de chevauchement des points sur un graphique en nuage de points univarié.↩︎
La fonction
give_n()est une fonction personnalisée que nous avons écrite nous-même. Elle positionne du textey=10% plus haut que lemax(x), et ce texte estlength(x), la longueur du vecteur qui correspond au nombre d’observations pourx(xétant utilisé en interne par le moteur graphique). Il est possible, et même assez facile, dans R d’écrire ses propres fonctions. Néanmoins cela dépasse du cadre du cours pour l’instant. Pour utilisergive_n()dans vos documents R Markdown, copiez simplement sa définition dans un chunk avant de l’utiliser comme c’est fait ici. Elle est aussi réutilisable plus loin dans le même R Markdown, une fois qu’elle est définie.↩︎