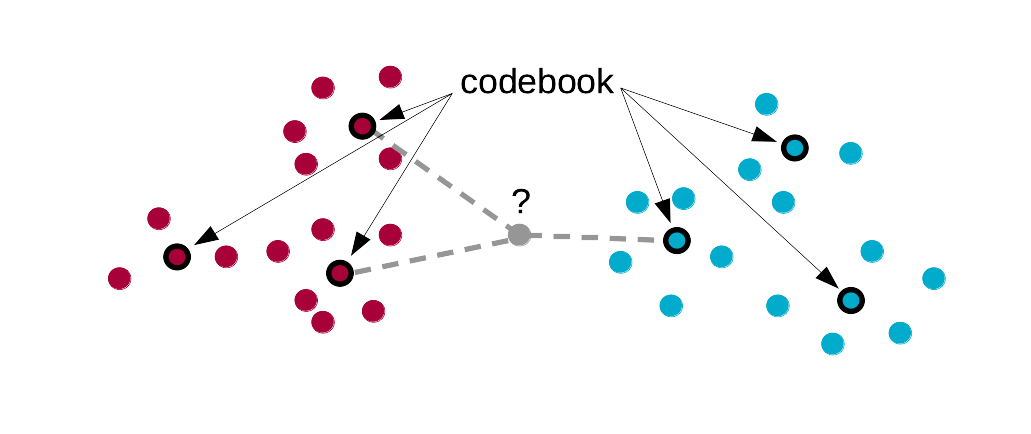
2.4 Quantification vectorielle
Un des désavantages de la méthode des k plus proches voisins est que l’on doit conserver toutes les données du set d’apprentissage et confronter systématiquement tout nouvel individu à l’ensemble des cas de ce set. L’idée sous-jacente à la quantification vectorielle (learning vector quantization en anglais, LVQ en abrégé) est que les données initiales peuvent sans doute être synthétisées : des individus proches dans l’espace de Malahanobis peuvent être remplacés par des “individus moyens ou centroïdes” tout en apportant à peu près le même effet. Du coup, nous réduisons la quantité d’information à conserver et nous accélérons les calculs dans les phases de test et déploiement.
Une étape supplémentaire dans le calcul du classifieur est introduite. Le set d’apprentissage initial est résumé en un dictionnaire ou codebook en anglais, dans lequel les groupes initiaux sont remplacés par un ou plusieurs centroïdes. Ces centroïdes sont, en quelque sorte, des “portraits robots” des différents classes et ils résument les caractéristiques des individus appartenant à ces classes. La classification supervisée se fait par une méthode similaire aux k plus proches voisins mais en utilisant les centroïdes du dictionnaire en lieu et place des individus du set d’apprentissage.
En plus du paramètre k, il faut donc également définir size, le nombre de centroïdes qui seront calculés dans le dictionnaire. Il est possible de calculer librement les différents centroïdes en fonction de la dispersion des données, ou bien d’imposer que le même nombre de centroïdes soit calculé pour chaque classe.
2.4.1 Pima avec LVQ
Voyons ce que cela donne sur nos données pima1 et pima2, en utilisant la fonction mlLvq() de {mlearning} qui utilise les arguments size = pour la taille du dictionnaire et k.nn = pour le nombre de proches voisins à considérer ensuite :
library(mlearning)
pima1_lvq <- mlLvq(data = pima1, diabetes ~ ., k.nn = 3, size = 30)
set.seed(846)
pima1_lvq_conf <- confusion(cvpredict(pima1_lvq, cv.k = 10), pima1$diabetes)
plot(pima1_lvq_conf)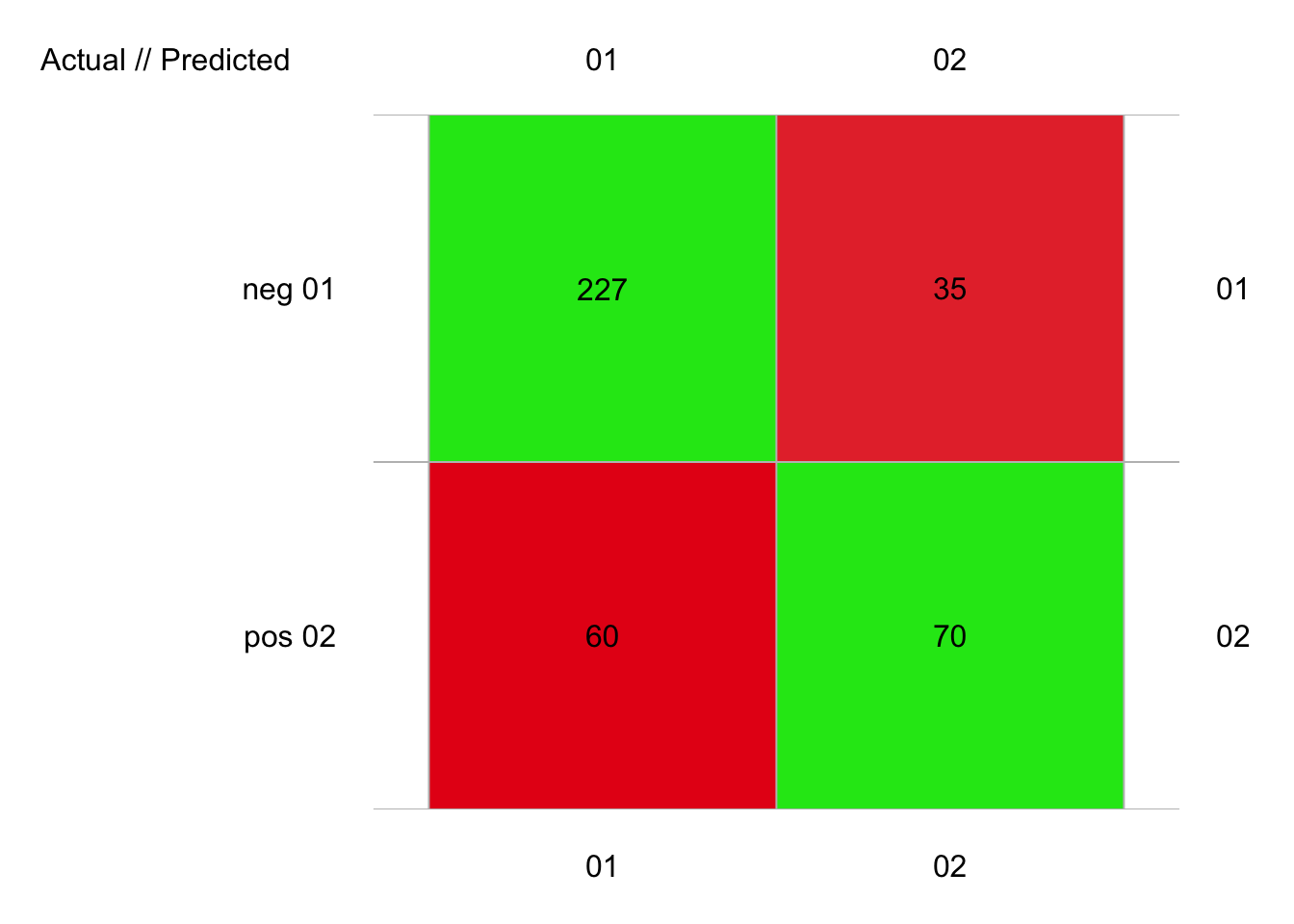
# 392 items classified with 297 true positives (error = 24.2%)
#
# Global statistics on reweighted data:
# Error rate: 24.2%, F(micro-average): 0.715, F(macro-average): 0.711
#
# Fscore Recall Precision Specificity NPV FPR FNR
# neg 0.8269581 0.8664122 0.7909408 0.5384615 0.6666667 0.4615385 0.1335878
# pos 0.5957447 0.5384615 0.6666667 0.8664122 0.7909408 0.1335878 0.4615385
# FDR FOR LRPT LRNT LRPS LRNS BalAcc
# neg 0.2090592 0.3333333 1.877226 0.2480916 2.372822 0.3135889 0.7024369
# pos 0.3333333 0.2090592 4.030769 0.5327008 3.188889 0.4214391 0.7024369
# MCC Chisq Bray Auto Manu A_M TP FP FN TN
# neg 0.4304338 72.62711 0.03188776 287 262 25 227 60 35 70
# pos 0.4304338 72.62711 0.03188776 105 130 -25 70 35 60 227Nous avons choisis arbitrairement de prendre un dictionnaire de taille 30 et 3 plus proches voisins. Avec ces valeurs, nous avons 24% d’erreur, ce qui nous situe entre k-NN et ADL en terme de performances. Essayez par vous-même d’autres valeurs de size = et k.nn = pour optimiser encore ce résultat.
Avec pima2, une taille de dictionnaire de 30 toujours et trois plus proches voisins, nous obtenons également 24% d’erreur :
library(mlearning)
pima2_lvq <- mlLvq(data = pima2, diabetes ~ ., k.nn = 3, size = 30)
set.seed(25)
pima2_lvq_conf <- confusion(cvpredict(pima2_lvq, cv.k = 10), pima2$diabetes)
plot(pima2_lvq_conf)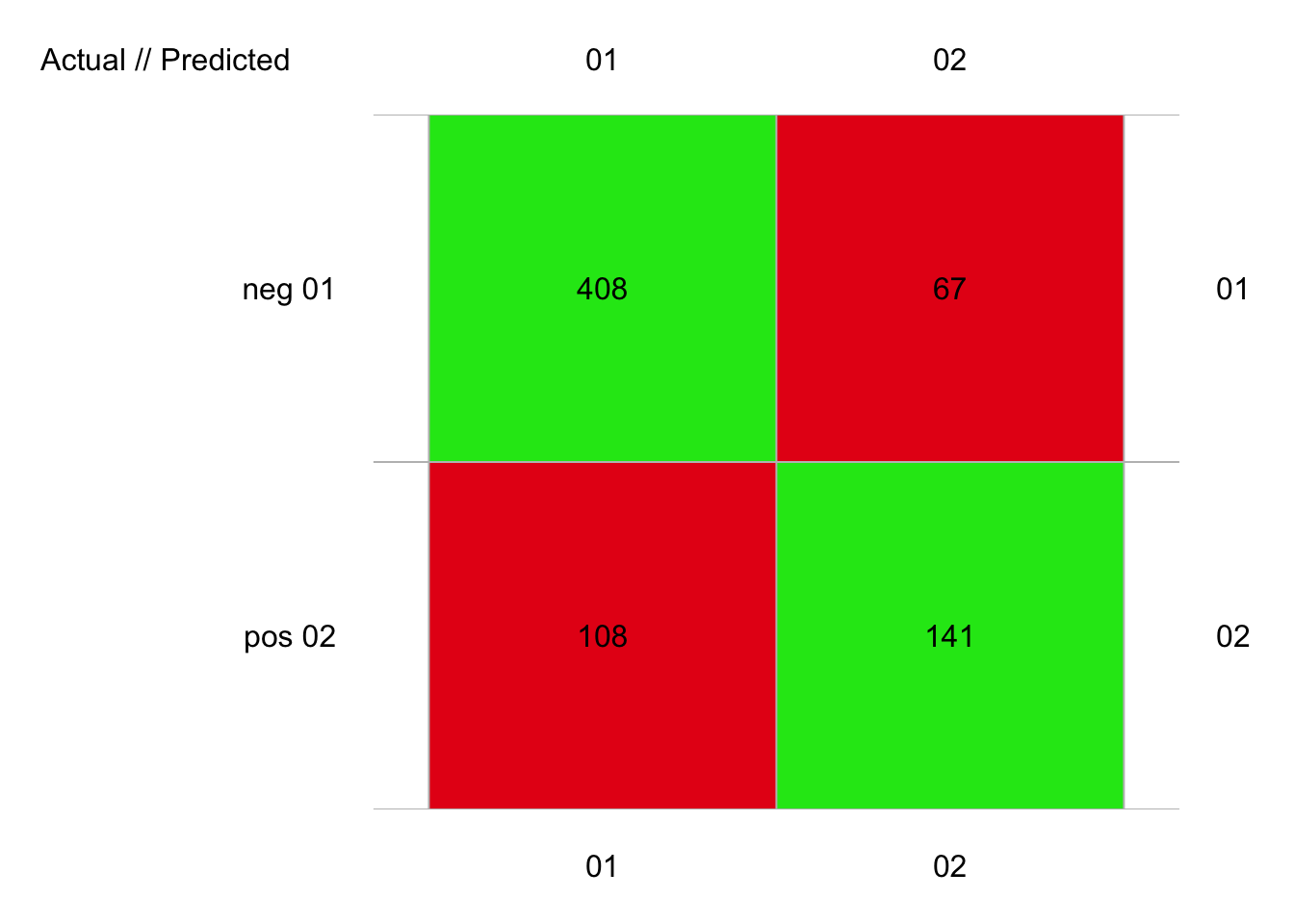
# 724 items classified with 549 true positives (error = 24.2%)
#
# Global statistics on reweighted data:
# Error rate: 24.2%, F(micro-average): 0.723, F(macro-average): 0.72
#
# Fscore Recall Precision Specificity NPV FPR FNR
# neg 0.8234107 0.8589474 0.7906977 0.5662651 0.6778846 0.4337349 0.1410526
# pos 0.6170678 0.5662651 0.6778846 0.8589474 0.7906977 0.1410526 0.4337349
# FDR FOR LRPT LRNT LRPS LRNS BalAcc
# neg 0.2093023 0.3221154 1.980351 0.2490929 2.454703 0.3087580 0.7126062
# pos 0.3221154 0.2093023 4.014566 0.5049610 3.238782 0.4073812 0.7126062
# MCC Chisq Bray Auto Manu A_M TP FP FN TN
# neg 0.4463709 144.2548 0.02831492 516 475 41 408 108 67 141
# pos 0.4463709 144.2548 0.02831492 208 249 -41 141 67 108 408À vous de jouer !
Réalisez le travail C02Ia_ml2, partie II.
Travail individuel pour les étudiants inscrits au cours de Science des Données Biologiques III à l’UMONS à terminer avant le 2021-12-24 23:59:59.
Initiez votre projet GitHub Classroom
Voyez les explications dans le fichier README.md, partie II.