6.1 Tableaux de données
Les tableaux de données sont principalement représentés sous deux formes : les tableaux cas par variables et les tableaux de contingence.
6.1.1 Tableaux cas par variables
Chaque individu est représenté en ligne et chaque variable en colonne par convention. En anglais, on parlera de tidy data.
Nous nous efforcerons de toujours créer un tableau de ce type pour nos données. La question à se poser est la suivante : est-ce que j’ai un seul et même individu statistique25 représenté sur chaque ligne du tableau ? Si la réponse est non, le tableau de données n’est pas correctement encodé.
À vous de jouer !
Considérez les données suivantes concernant la taille adulte mesurée en cm pour deux espèces de petits rongeurs :
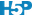
Considérez ce second tableau de données concernant également la taille adulte mesurée en cm de deux espèces de petits rongeurs :
Considérez maintenant ce troisième exemple fictif avec le résultat d’un test enregistré avant et après un traitement censé améliorer le résultat du test :
Avant toute analyse, vérifier le type de tableau de données que vous avez à disposition. Le point de départ le plus courant et le plus sûr est le tableau cas par variables. Rappellez-vous bien que la question à se poser pour vérifier si le tableau est bien présenté est : “a-t-on une et une seule ligne dans le tableau pour chaque individu statistique ?” Si ce n’est pas le cas, il faut remanier le tableau avant de commencer son analyse.
Les tableaux de données que vous avez traités jusqu’à présent étaient tous des tableaux cas par variables. Chaque ligne représentait un individu statistique sur qui une ou plusieurs variables (en colonnes) étaient mesurées.
# gender day_birth weight height wrist year_measure age
# 1: M 1995-03-11 69 182 15.0 2013 18
# 2: M 1998-04-03 74 190 16.0 2013 15
# 3: M 1967-04-04 83 185 17.5 2013 46
# 4: M 1994-02-10 60 175 15.0 2013 19
# 5: W 1990-12-02 48 167 14.0 2013 23
# 6: W 1994-07-15 52 179 14.0 2013 19L’encodage d’un petit tableau cas par variables directement dans R est facile. Cela peut se faire de plusieurs façons différentes. En voici deux utilisant les fonctions dtx() (spécification colonne par colonne) et dtx_rows() (spécification ligne par ligne) :
# x y
# 1: 1 3
# 2: 2 4# x y
# 1: 1 3
# 2: 2 4La seconde approche est plus naturelle, mais la première permet d’utiliser diverses fonctions de R pour faciliter l’encodage, par exemple :
- Séquence d’entiers successifs :
# [1] 1 2 3 4 5 6 7 8 9 10- Répétition d’un vecteur cinq fois (le “L” après 5 indique que c’est un entier, mais il est ici facultatif) :
# [1] "a" "b" "c" "a" "b" "c" "a" "b" "c" "a" "b" "c" "a" "b" "c"- Répétition de chaque item d’un vecteur cinq fois :
# [1] "a" "a" "a" "a" "a" "b" "b" "b" "b" "b" "c" "c" "c" "c" "c"Pour de plus gros tableaux, il vaut mieux utiliser un tableur tel qu’Excel ou LibreOffice Calc pour l’encodage. Les tableurs en ligne comme Google Sheets ou Excel Online conviennent très bien également et facilitent un travail collaboratif ainsi que la mise à disposition sur Internet, comme nous avons vu au module 5. Évitez les formules dans vos tableaux, encodez à partir de la cellule A1 en haut à gauche avec la première ligne qui contient le nom des colonnes. Soyez aussi attentif à ce qu’Excel ne modifie pas de manière inadéquate vos entrées. Par exemple, Excel a tendance à essayer d’interpréter certaines entrées comme des dates et les modifie automatiquement sans demander votre avis !
6.1.2 Tableau de contingence
Le tableau cas par variables n’est toutefois pas la seule représentation (correcte) possible des données. Un tableau de contingence représente de manière bien plus compacte le dénombrement de l’occurrence de chaque niveau d’une (tableau à une entrée) ou de deux variables qualitatives (tableau à double entrée).
À vous de jouer !
La fonction table() crée ces deux types de tableaux de contingence à partir de données encodées en tableau cas par variables :
# Variable age_rec qualitative
biometry$age_rec <- cut(biometry$age, include.lowest = FALSE, right = TRUE,
breaks = c(14, 27, 90))
# Tableau de contingence genre versus age_rec
(bio_tab <- table(biometry$gender, biometry$age_rec))#
# (14,27] (27,90]
# M 106 92
# W 97 100À vous de jouer !
Le tableau de contingence peut toujours être calculé à partir d’un tableau cas par variable, mais il peut également être encodé directement si nécessaire. Voici un petit tableau de contingence à simple entrée encodé directement comme tel (vecteur nommé transformé en objet table à l’aide de la fonction as.table()) :
# Tableau de contingence encodé directement
anthirrhinum <- as.table(c(
"fleur rouge" = 54,
"fleur rose" = 122,
"fleur blanche" = 58)
)
anthirrhinum# fleur rouge fleur rose fleur blanche
# 54 122 58Une troisième possibilité est d’utiliser un tableau indiquant les fréquences d’occurrences dans une colonne (freq ci-dessous). Ce n’est pas un tableau cas par variables, mais une forme bien plus concise et pratique pour préencoder les données qui devront être ensuite transformées en tableau de contingence en utilisant cette fois-ci la fonction xtabs(). Voici un exemple pour un tableau de contingence à double entrée. Notez que le tableau cas par variables correspondant devrait contenir 44 + 116 + 19 + 128 = 307 lignes et serait plus fastidieux à construire et à manipuler (même en utilisant la fonction rep()).
# Tableau avec fréquences
timolol <- dtx(
traitement = c("timolol", "timolol", "placebo", "placebo"),
patient = c("sain", "malade", "sain", "malade"),
freq = c(44, 116, 19, 128)
)
# Tableau de contingence patient versus tratement
(timolol_table <- xtabs(data = timolol, freq ~ patient + traitement))# traitement
# patient placebo timolol
# malade 128 116
# sain 19 44La sortie par défaut d’un tableau de contingence n’est pas très esthétique, mais plusieurs options existent pour le formater d’une façon agréable. En voici trois exemples :
| placebo | timolol | |
|---|---|---|
| malade | 128 | 116 |
| sain | 19 | 44 |
| placebo | timolol | |
|---|---|---|
| malade | 128 | 116 |
| sain | 19 | 44 |
patient | traitement | |||
|---|---|---|---|---|
placebo | timolol | Total | ||
malade | Count | 128 (41.7%) | 116 (37.8%) | 244 (79.5%) |
Mar. pct (1) | 87.1% ; 52.5% | 72.5% ; 47.5% | ||
sain | Count | 19 (6.2%) | 44 (14.3%) | 63 (20.5%) |
Mar. pct | 12.9% ; 30.2% | 27.5% ; 69.8% | ||
Total | Count | 147 (47.9%) | 160 (52.1%) | 307 (100.0%) |
(1) Columns and rows percentages | ||||
La dernière version avec tabularise() ajoute des informations utiles comme les totaux par ligne, par colonne et général, ainsi que divers pourcentages. C’est ce type de sortie que nous privilégierons dans SciViews::R.
Il est aussi possible de représenter graphiquement un tableau de contingence pour l’inclure dans une figure composée, éventuellement en le mélangeant à des graphiques26.
tab1 <- ggpubr::ggtexttable(head(biometry), rows = NULL)
tab2 <- ggpubr::ggtexttable(table(biometry$gender, biometry$age_rec))
combine_charts(list(tab1, tab2), nrow = 2)
Différentes fonctions dans R existent également pour convertir un tableau de contingence en tableau cas par variables (ou en tous cas, en un tableau similaire). Par exemple, as_dtx() renvoie un tableau indiquant les fréquences d’occurrences dans une colonne nommée N :
# patient traitement N
# 1: malade placebo 128
# 2: sain placebo 19
# 3: malade timolol 116
# 4: sain timolol 44Si vous insistez, vous pouvez aussi obtenir un tableau cas par variables (mais celui-ci est très long et peu pratique à manipuler) à l’aide de la fonction “speedy” suncount() (ou la fonction “tidy” uncount())27 :
# patient traitement
# 1: malade placebo
# 2: malade placebo
# 3: malade placebo
# 4: malade placebo
# 5: malade placebo
# ---
# 303: sain timolol
# 304: sain timolol
# 305: sain timolol
# 306: sain timolol
# 307: sain timolol6.1.3 Métadonnées
Les données dans un tableau doivent impérativement être associées à un ensemble de métadonnées. Les métadonnées (metadata en anglais) apportent des informations complémentaires nécessaires pour une interprétation correcte des données. Elles permettent donc de replacer les données dans leur contexte et de spécifier des caractéristiques liées aux mesures réalisées comme les unités de mesure entre autres.
Données de qualité = tableau de données + métadonnées
Les données correctement qualifiées et documentées sont les seules qui peuvent être utilisées par un collaborateur externe. C’est-à-dire qu’une personne externe ne peut interpréter le tableau de données que si les métadonnées sont complètes et suffisamment explicites.
Exemple de métadonnées :
- Unités de mesure (exemple : 3,5 mL, 21,2 °C)
- Précision de la mesure (21,2 ± 0,2 dans le cas d’un thermomètre gradué tous les 0,2 °C)
- Méthode de mesure utilisée (thermomètre à mercure, ou électronique, ou …)
- Type d’instrument employé (marque et modèle du thermomètre)
- Date et lieu de la mesure (si pas encodée directement dans le tableau)
- Nom du projet lié à la prise de mesure
- Nom de l’opérateur en charge de la mesure
- …
Vous avez pu vous apercevoir que la fonction read() permet d’ajouter certaines métadonnées comme les unités aux variables d’un jeu de données. Cependant, il n’est pas toujours possible de rajouter les métadonnées dans un tableau sous forme électronique, mais il faut toujours les consigner dans un cahier de laboratoire, et ensuite les retranscrire dans le rapport. La fonction labelise() vous permet de rajouter le label et les unités de mesure pour vos différentes variables directement dans le tableau. Par exemple, voici l’encodage direct d’un petit jeu de données qui mesure la distance du saut (jump) en cm de grenouilles-taureaux Lithobates catesbeianus (Shaw 1802) en fonction de leur masse (weight) en g pour cinq individus différents (ind). Vous pouvez annoter ce data frame de la façon suivante :
frog <- dtx_rows(
~ind, ~jump, ~weight,
"1", 71, 204,
"2", 70, 240,
"3", 100, 296,
"4", 120, 303,
"5", 103, 422
)
# Ajout des labels et des unités
frog <- labelise(frog,
label = list(
ind = "Individu",
jump = "Distance du saut",
weight = "Masse"),
units = list(
jump = "cm",
weight = "g")
)
# Affichage synthétique des données et métadonnées associées
str(frog)# Classes 'data.table' and 'data.frame': 5 obs. of 3 variables:
# $ ind : chr "1" "2" "3" "4" ...
# ..- attr(*, "label")= chr "Individu"
# $ jump : num 71 70 100 120 103
# ..- attr(*, "label")= chr "Distance du saut"
# ..- attr(*, "units")= chr "cm"
# $ weight: num 204 240 296 303 422
# ..- attr(*, "label")= chr "Masse"
# ..- attr(*, "units")= chr "g"
# - attr(*, ".internal.selfref")=<externalptr># ind jump weight
# "Individu" "Distance du saut" "Masse"Les métadonnées sont enregistrées dans des attributs en R (attr). De même, comment() permet d’associer ou de récupérer un attribut commentaire (notez comment assigner une chaîne de caractères à comment() ajoute ou modifie le commentaire de l’objet, tableau entier ou variable du tableau :
# Ajout d'un commentaire concernant le jeu de données lui-même
comment(frog) <- "Saut de grenouilles taureaux"
# Ajout d'un commentaire sur une variable
comment(frog$jump) <- "Premier saut mesuré après stimulation de l'animal"
# Affichage synthétique
str(frog)# Classes 'data.table' and 'data.frame': 5 obs. of 3 variables:
# $ ind : chr "1" "2" "3" "4" ...
# ..- attr(*, "label")= chr "Individu"
# $ jump : num 71 70 100 120 103
# ..- attr(*, "label")= chr "Distance du saut"
# ..- attr(*, "units")= chr "cm"
# ..- attr(*, "comment")= chr "Premier saut mesuré après stimulation de l'animal"
# $ weight: num 204 240 296 303 422
# ..- attr(*, "label")= chr "Masse"
# ..- attr(*, "units")= chr "g"
# - attr(*, ".internal.selfref")=<externalptr>
# - attr(*, "comment")= chr "Saut de grenouilles taureaux"# [1] "Saut de grenouilles taureaux"# [1] "Premier saut mesuré après stimulation de l'animal"# NULL6.1.4 Dictionnaire des données
Le dictionnaire des données est un élément important de la constitution d’une base de données. Il s’agit d’un tableau annexe qui reprend au minimum le nom de chaque variable, son label (nom plus long et explicite), ses unités éventuelles, son type (numérique, facteur, facteur ordonné, date …), les niveaux de variables qualitatives, la façon dont les valeurs manquantes sont encodées, et un commentaire éventuel. Cela donne donc un tableau du genre :
| Variable | Label | Unités | Type | Niveaux | Val. manquantes | Commentaire |
|---|---|---|---|---|---|---|
| date | Date | - | Date | NA | Date de mesure | |
| age | Âge | années | numeric | -1 | ||
| diameter | Diamètre du test | mm | numeric | NA | Moyenne de deux diamètres perpendiculaires | |
| origin | Origine | - | factor | Fishery, Farm | unknown | “Fishery” = oursins sauvages, “Farm” = oursins d’élevage |
Ce tableau peut-être encodé sous forme textuelle et placé dans le même dossier que le jeu de données lui-même. Il peut aussi être encodé comme feuille supplémentaire dans un fichier Excel.
Le dictionnaire des données est un outil important pour comprendre ce que contient le tableau de données, et donc, son interprétation. Ne le négligez pas !
Un individu statistique n’est pas forcément la même chose qu’un individu biologique. En statistique, le cas ou l’individu est l’entité sur laquelle nous travaillons. Il peut s’agir d’un organe (partie d’un individu biologique) comme d’un ensemble d’organismes (une culture bactérienne ou la portée d’une souris par exemple, donc, plusieurs individus biologiques).↩︎
Utilisez cette option avec parcimonie. Il vaut toujours mieux représenter un tableau comme … un tableau plutôt que comme une figure !↩︎
Notez également que passer d’un tableau cas par variables à un tableau des fréquences d’occurrences se fait à l’aide de
scount()oucount().↩︎