10.4 Test de Kruskal-Wallis
Les conditions d’application de l’ANOVA sont assez restrictives, en particuliers l’homoscédasticité et le Normalité des résidus. Dans notre exemple, nous avons pu stabiliser la variance par une transformation puissance cinq, mais la distribution des résidus n’est pas optimale. Nous pouvons tout aussi bien décider de nous orienter vers la version non paramétrique équivalente : le test de Kruskal-Wallis.
Le raisonnement entre ANOVA (test paramétrique) et Kruskal-Wallis (test non paramétrique) est le même qu’entre le test t de Student ou celui de Wilcoxon-Mann-Whitney. Lorsque les conditions sont remplies, l’ANOVA est un test plus puissant à utiliser en priorité. Nous le préférerons donc, sauf dans les cas impossibles où aucune transformation des données ne permet d’obtenir une distribution acceptable des résidus et une stabilisation des variances (homoscédasticité).
Le test de Kruskal-Wallis va comparer la localisation des points sur l’axe plutôt que les moyennes. Nous travaillons ici sur les rangs. La transformation en rangs consiste à ranger les observations de la plus petite à la plus grande et à remplacer les valeurs par leur position (leur rang) dans ce classement. Les ex-æquos reçoivent des rangs équivalents. Un petit exemple :
# [1] 0.5 2.1 2.1 2.4 3.5 4.5# [1] 1.0 2.5 2.5 4.0 5.0 6.0Donc 0,5 donne 1, 2,1 apparaît deux fois en position 2 et 3, donc on leurs attribue à tous les deux le rang 2,5. 2,4 est remplacé par 4, 3,5 par 5 et enfin 4,5 est remplacé par 6.
Dans le test de Kruskal-Wallis, sous \(H_0\) nous avons le même rang moyen (noté \(mr\)) pour chaque groupe parmi \(k\). Sous \(H_1\), au moins deux groupes ont des rangs moyens différents.
\(H_0:mr_1 = mr_2 = ... = mr_k\)
\(H_1: \exists(i, j) \mathrm{\ tel\ que\ } mr_i \neq mr_j\)
Nous ne détaillons pas les calculs (mais voyez ici). Le calcul aboutit en fait à une valeur de \(\chi^2_{obs}\) à \(k - 1\) degrés de liberté lorsque k populations sont comparées. Ainsi, nous avons déjà un loi de distribution théorique pour le calcul de la valeur P. La zone de rejet est située à la droite de la distribution comme dans le cas de l’ANOVA et du test de \(\chi^2\).
Le test est réalisé dans R avec la fonction kruskal.test(). Notez que les arguments sont les mêmes que pour l’ANOVA à un facteur.
#
# Kruskal-Wallis rank sum test
#
# data: aspect by group
# Kruskal-Wallis chi-squared = 139.68, df = 3, p-value < 2.2e-16Ici, nous rejetons \(H_0\) au seuil \(\alpha\) de 5%. Nous pouvons dire qu’il y a au moins une différence significative entre les ratios au seuil \(\alpha\) de 5% (test Kruskal-Wallis, \(\chi^2\) = 140, ddl = 3, valeur P << 10-3).
Conditions d’application
Le test de Kruskal-Wallis est naturellement moins contraignant que l’ANOVA.
- échantillon représentatif (par exemple, aléatoire),
- observations indépendantes,
- variable dite réponse quantitative,
- une variable dite explicative qualitative à trois niveaux ou plus,
- les distributions au sein des différentes sous-population sont, si possible, similaires mais de forme quelconque.
10.4.1 Test “post hoc” non paramétrique
Nous devrions également réaliser des tests “post hoc” lorsque nous rejetons \(H_0\) du Kruskal-Wallis. Les version non paramétriques des tests de comparaisons multiples sont moins connues. Nous pourrions effectuer des comparaisons deux à deux avec des tests de Wilcoxon en appliquant une correction de Bonferroni.
Une autre option consiste à utiliser une version non paramétrique du test de Tukey basée sur les rangs, dit test pot hoc non paramétrique asymptotique. Les explications assez techniques sont disponibles ici. Ce test est disponible dans le package R {nparcomp}.
#
# #------Nonparametric Multiple Comparisons for relative contrast effects-----#
#
# - Alternative Hypothesis: True relative contrast effect p is not equal to 1/2
# - Type of Contrast : Tukey
# - Confidence level: 95 %
# - Method = Logit - Transformation
# - Estimation Method: Pairwise rankings
#
# #---------------------------Interpretation----------------------------------#
# p(a,b) > 1/2 : b tends to be larger than a
# #---------------------------------------------------------------------------#
#
#
# #------------Nonparametric Multiple Comparisons for relative contrast effects----------#
#
# - Alternative Hypothesis: True relative contrast effect p is not equal to 1/2
# - Estimation Method: Global Pseudo ranks
# - Type of Contrast : Tukey
# - Confidence Level: 95 %
# - Method = Logit - Transformation
#
# - Estimation Method: Pairwise rankings
#
# #---------------------------Interpretation--------------------------------------------#
# p(a,b) > 1/2 : b tends to be larger than a
# #-------------------------------------------------------------------------------------#
#
# #----Data Info-------------------------------------------------------------------------#
# # A data.frame: 4 x 2
# Sample Size
# <chr> <int>
# 1 B-F 50
# 2 B-M 50
# 3 O-F 50
# 4 O-M 50
#
# #----Contrast--------------------------------------------------------------------------#
# B-F B-M O-F O-M
# B-M - B-F -1 1 0 0
# O-F - B-F -1 0 1 0
# O-M - B-F -1 0 0 1
# O-F - B-M 0 -1 1 0
# O-M - B-M 0 -1 0 1
# O-M - O-F 0 0 -1 1
#
# #----Analysis--------------------------------------------------------------------------#
# # A data.frame: 6 x 6
# Comparison Estimator Lower Upper Statistic p.Value
# <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
# 1 p( B-F , B-M ) 0.017 0.004 0.069 -7.23 1.62e-12
# 2 p( B-F , O-F ) 0.695 0.542 0.815 3.26 6.64e- 3
# 3 p( B-F , O-M ) 0.051 0.018 0.137 -7.01 7.11e-12
# 4 p( B-M , O-F ) 0.99 0.949 0.998 7.21 1.69e-12
# 5 p( B-M , O-M ) 0.654 0.501 0.781 2.61 4.85e- 2
# 6 p( O-F , O-M ) 0.027 0.008 0.088 -7.39 4.38e-13
#
# #----Overall---------------------------------------------------------------------------#
# # A data.frame: 1 x 2
# Quantile p.Value
# <dbl> <dbl>
# 1 2.59 4.38e-13
#
# #--------------------------------------------------------------------------------------#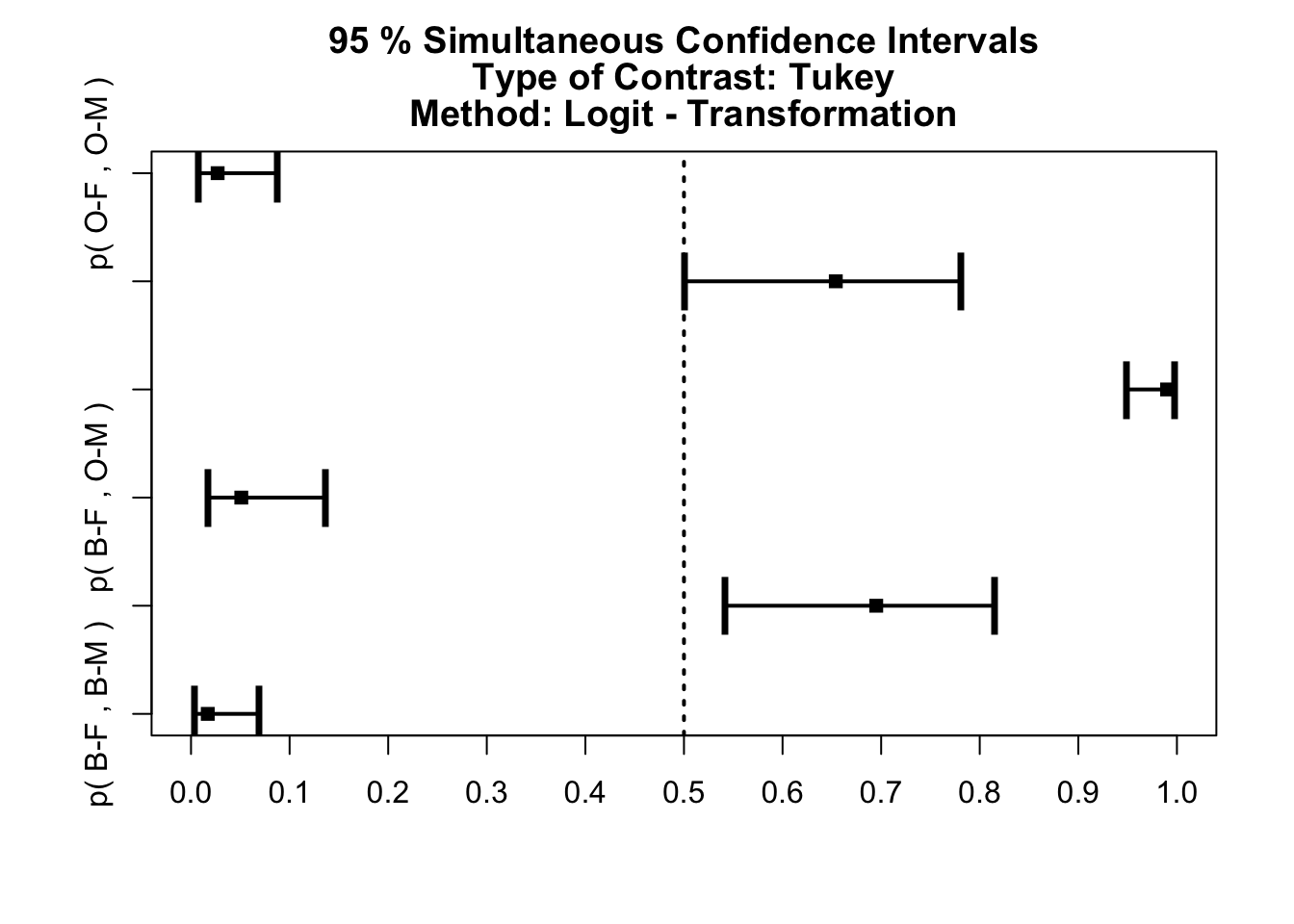
La présentation des résultats est plus détaillée que pour le HSD de Tukey. Pour la version textuelle, c’est la dernière colonne nommée p.Value qui nous intéresse et qui est à comparer au seuil \(\alpha\) choisi. Le graphique est très similaire à la version paramétrique avec des barres d’erreurts autour de la différence des moyennes de chaque paire qui représente un intervalle de confiance à \(1 - \alpha\). Ici, toutes les différences sont considérées comme significatives, même si la comparaison des mâles B-M - O-M avec une valeur P tout juste significative de 0,049 est à prendre avec des pincettes étant donné sa proximité du seuil. Notez que les intervalles de confiance ne sont plus symétriques dans le cas présent.
Au final que conclure ? Lorsque l’ANOVA peut être utilisée, elle est à préférer. Ici avec une transformation puissance cinq, nous stabilisons la variance qui est le critère le plus sensible. De plus tant avec l’ANOVA qu’avec le Kruskal-Wallis, nous détectons des différences significatives. Les tests “post hoc” nous indiquent des différences significatives au seuil \(\alpha\) de 5% sauf peut-être pour les mâles (il faudrait prévoir des mesures supplémentaires pour confirmer ou infirmer à ce niveau). Dans notre exemple, puisque les deux tests donnent sensiblement le même résultat, nous pouvons jouer la sécurité et présenter le Kruskal_wallis dans notre publication. Ainsi, la question de la distribution des résidus ne se pose plus.
À vous de jouer !
Effectuez maintenant les exercices du tutoriel A10Lb_kruskal (Test de Kruskal-Wallis).
BioDataScience1::run("A10Lb_kruskal")Appliquez vos nouvelles connaissances dans le projet de groupe que vous avez débuté aux deux modules précédents.
Réalisez en groupe le travail A10Ga_human_health, partie III.
Travail en groupe de 4 pour les étudiants inscrits au cours de Science des Données Biologiques I : inférence à l’UMONS à terminer avant le 2023-05-22 23:59:59.
Initiez votre projet GitHub Classroom
Voyez les explications dans le fichier README.md, partie III.