2.3 Régression linéaire polynomiale
Pour rappel, un polynôme est une expression mathématique du type (notez la ressemblance avec l’équation de la régression multiple) :
\[ a_0 + a_1 . x + a_2 . x^2 + ... + a_n . x^n \]
Un polynôme d’ordre 2 (terme jusqu’au \(x^2\)) correspond à une parabole dans le plan xy. Que se passe-t-il si nous calculons une variable diameter2 qui est le carré du diamètre et que nous prétendons faire une régression multiple en utilisant à la fois diameter et diameter2 ?
trees <- smutate(trees,
diameter2 = labelise(diameter^2, "Diamètre^2", units = "m^2"))
summary(lm(data = trees, volume ~ diameter + diameter2)) |>
tabularise()Modèle linéaire | |||||
|---|---|---|---|---|---|
| |||||
Terme | Valeur estimée | Ecart type | Valeur de t | Valeur de p | |
| 0.311 | 0.318 | 0.978 | 0.336293 |
|
| -2.372 | 1.838 | -1.290 | 0.207489 |
|
| 11.236 | 2.556 | 4.396 | 0.000144 | *** |
0 <= '***' < 0.001 < '**' < 0.01 < '*' < 0.05 | |||||
Etendue des résidus : [-0.1579, 0.215] | |||||
Ecart type des résidus : 0.09441 pour 28 degrés de liberté | |||||
R2 multiple : 0.9616 - R2 ajusté : 0.9589 | |||||
Statistique F : 350.5 pour 2 et 28 ddl - valeur de p : < 2.22e-16 | |||||
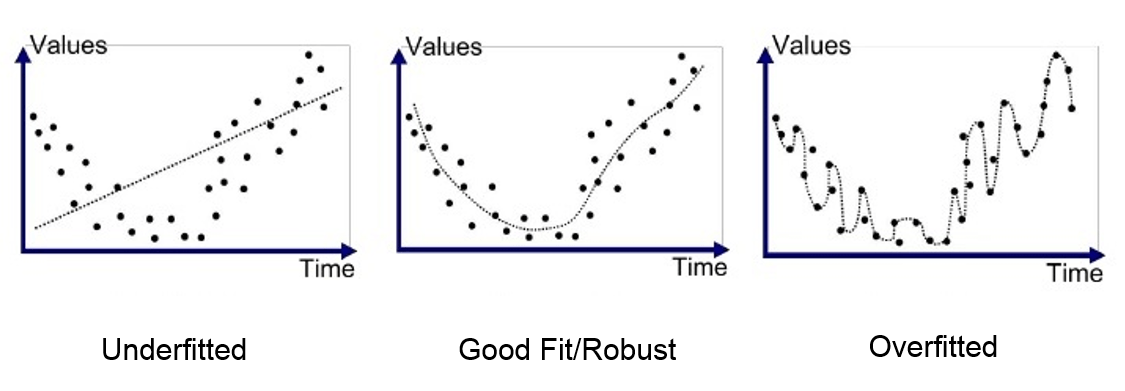
Il semble que R ait pu réaliser cette régression. Cette fois-ci, nous n’avons cependant pas une droite ou un plan ajusté, mais par ce subterfuge, nous avons pu ajuster une courbe dans les données ! Nous pourrions augmenter le degré du polynôme (ajouter un terme en diameter^3, voire encore des puissances supérieures). Dans ce cas, nous obtiendrons une courbe de plus en plus flexible, toujours dans le plan xy. Ceci illustre parfaitement d’ailleurs l’ambiguïté de la complexité du modèle qui s’ajuste de mieux en mieux dans les données, mais qui, ce faisant, perd également progressivement son pouvoir explicatif. En effet, on sait qu’il existe toujours une droite qui passe entre deux points dans le plan. De même, il existe toujours une parabole qui passe par trois points quelconques dans le plan. Et par extension, il existe une courbe correspondant à un polynôme d’ordre n - 1 qui passe par n’importe quel ensemble de n points dans le plan. Un modèle construit à l’aide d’un tel polynôme aura toujours un R2 égal à 1… mais en même temps ce modèle ne sera d’aucune utilité, car il ne contient plus aucune information pertinente. C’est ce qu’on appelle le surajustement (overfitting en anglais). La figure ci-dessous (issue d’un article écrit par Anup Bhande ici) illustre bien ce phénomène.
Devoir calculer les différentes puissances des variables au préalable devient rapidement fastidieux. Heureusement, R autorise de glisser ce calcul directement dans la formule, mais à condition de lui indiquer qu’il ne s’agit pas du nom d’une variable diameter^2, mais d’un calcul effectué sur diameter en utilisant la fonction d’identité I(). Ainsi, sans rien calculer au préalable, nous pouvons utiliser la formule volume ~ diameter + I(diameter^2). Le code ci-dessous qui construit le modèle trees_lm4 l’utilise (seul petit bémol : le code n’est pas encore capable de recalculer les labels et les unités correctement et il présente alors juste le nom de la variable élevée au carré, ce qui n’est déjà pas si mal ; préférez un pré-calcul de diameter2 comme plus haut pour résoudre le problème en spécifiant vous-même le label et l’unité).
Modèle linéaire | |||||
|---|---|---|---|---|---|
| |||||
Terme | Valeur estimée | Ecart type | Valeur de t | Valeur de p | |
| 0.311 | 0.318 | 0.978 | 0.336293 |
|
| -2.372 | 1.838 | -1.290 | 0.207489 |
|
| 11.236 | 2.556 | 4.396 | 0.000144 | *** |
0 <= '***' < 0.001 < '**' < 0.01 < '*' < 0.05 | |||||
Etendue des résidus : [-0.1579, 0.215] | |||||
Ecart type des résidus : 0.09441 pour 28 degrés de liberté | |||||
R2 multiple : 0.9616 - R2 ajusté : 0.9589 | |||||
Statistique F : 350.5 pour 2 et 28 ddl - valeur de p : < 2.22e-16 | |||||
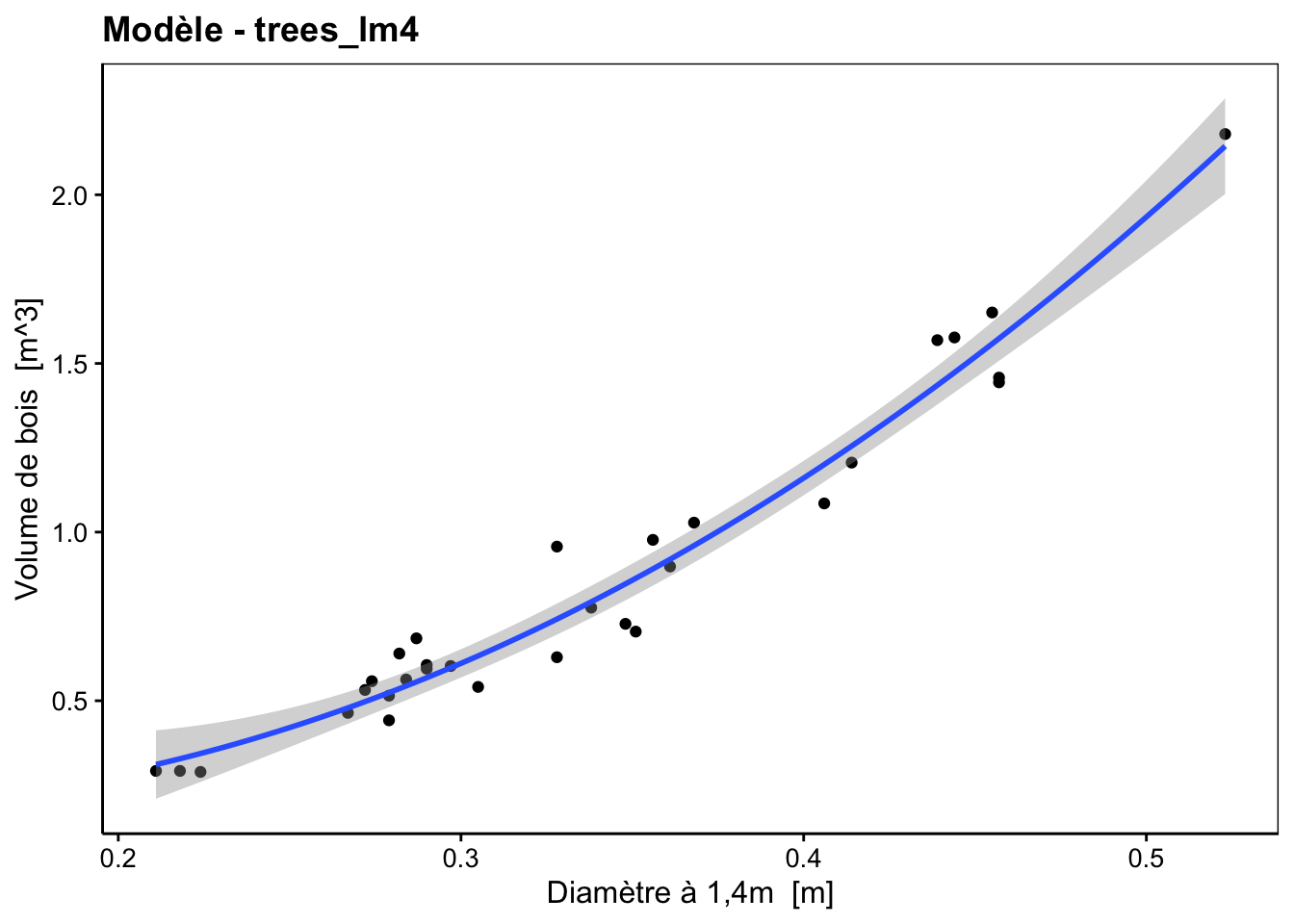
Remarquez sur le graphique comment, à présent, la courbe s’ajuste bien mieux dans le nuage de point et comme l’arbre le plus grand avec un diamètre supérieur à 0,5m est presque parfaitement ajusté par le modèle. Faites donc très attention que des points influents ou extrêmes peuvent apparaître également comme tels à cause d’un mauvais choix de modèle !
L’analyse des résidus nous montre aussi un comportement plus sain.
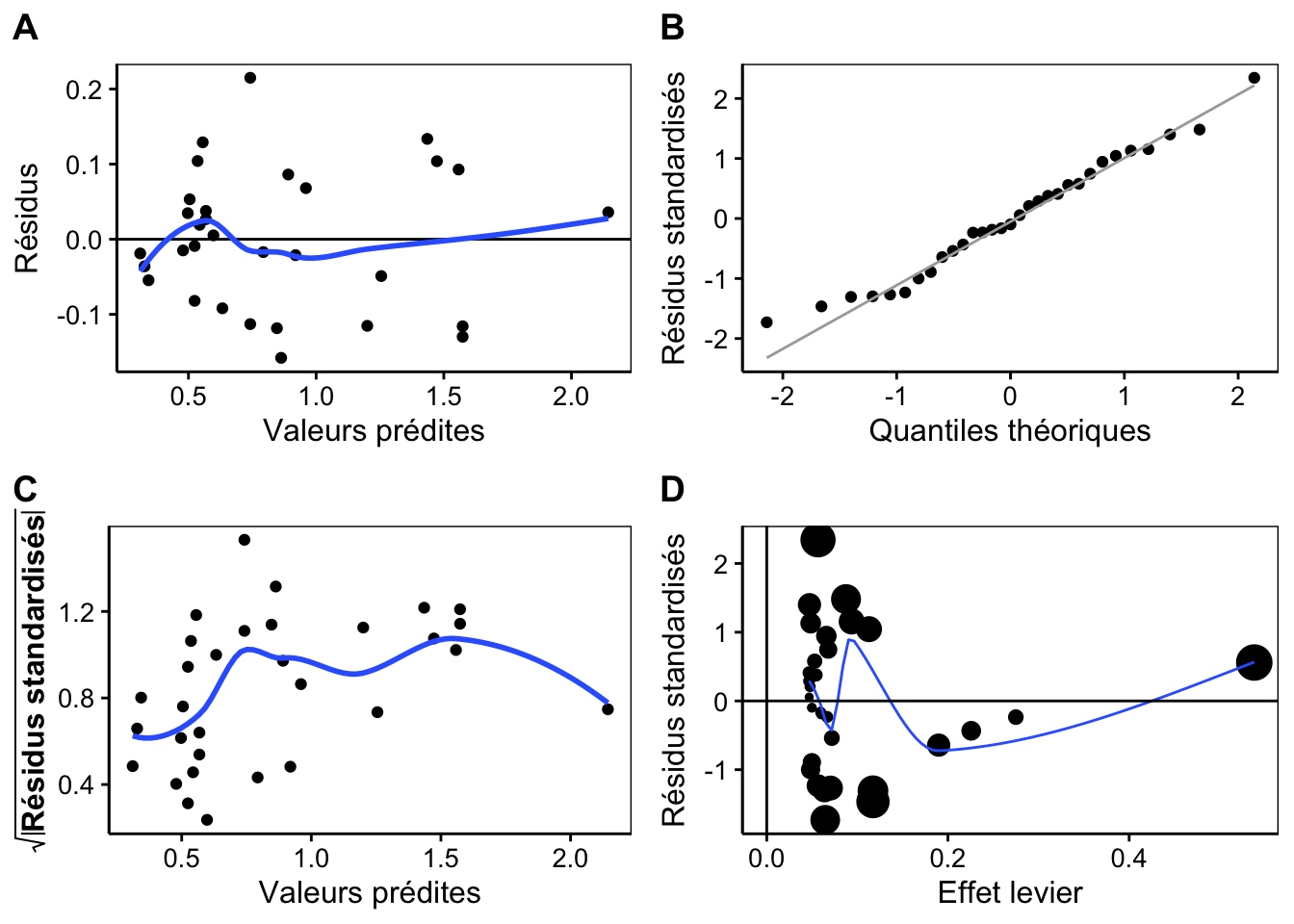
Revenons un instant sur le résumé de ce modèle.
Modèle linéaire | |||||
|---|---|---|---|---|---|
| |||||
Terme | Valeur estimée | Ecart type | Valeur de t | Valeur de p | |
| 0.311 | 0.318 | 0.978 | 0.336293 |
|
| -2.372 | 1.838 | -1.290 | 0.207489 |
|
| 11.236 | 2.556 | 4.396 | 0.000144 | *** |
0 <= '***' < 0.001 < '**' < 0.01 < '*' < 0.05 | |||||
Etendue des résidus : [-0.1579, 0.215] | |||||
Ecart type des résidus : 0.09441 pour 28 degrés de liberté | |||||
R2 multiple : 0.9616 - R2 ajusté : 0.9589 | |||||
Statistique F : 350.5 pour 2 et 28 ddl - valeur de p : < 2.22e-16 | |||||
La pente relative au diamètre \(\beta_1\) nécessite quelques éléments d’explication. En effet, que signifie une pente pour une courbe dont la dérivée première (“pente locale”) change constamment ? En fait, il faut comprendre ce paramètre comme étant la pente de la courbe au point x = 0.
Si le modèle est très nettement significatif (ANOVA, valeur p < 0,001), et si le R2 ajusté grimpe maintenant à 0,96, seul le paramètre relatif au diamètre2 (\(\beta_2\)) est significatif cette fois-ci. Ce résultat suggère que ce modèle pourrait être simplifié en considérant que l’ordonnée à l’origine \(\alpha\) et la pente \(\beta_1\) pour le diamètre valent zéro. Cela peut être tenté, mais à condition de refaire l’analyse. On ne peut jamais laisser tomber un paramètre dans une analyse et considérer que les autres sont utilisables tels quels. Tous les paramètres calculés sont interconnectés.
De plus, considérez ici la simplification d’un modèle polynomial d’ordre deux comme une exception. Dans le cas d’une régression polynomiale d’ordre supérieur, les différents termes étant corrélés par définition, puisqu’il s’agit en fait de puissances croissantes de la même variable, une instabilité dans l’estimation des différents paramètres apparaît, sauf pour le terme de plus haute puissance. Par conséquent, vous ne pouvez plus vous fier aux tests de Student pour les autres paramètres et vous êtes obligé de considérer le polynôme comme un tout indissociable.
À vous de jouer !
Ceci étant précisé, voyons ce que donne la simplification de notre modèle (la formule devient volume ~ I(diameter^2) - 1 ou volume ~ I(diameter^2) + 0, ce qui a une signification identique dans R) :
Modèle linéaire | |||||
|---|---|---|---|---|---|
| |||||
Terme | Valeur estimée | Ecart type | Valeur de t | Valeur de p | |
| 7.3 | 0.14 | 52.3 | < 2·10-16 | *** |
0 <= '***' < 0.001 < '**' < 0.01 < '*' < 0.05 | |||||
Etendue des résidus : [-0.1947, 0.1824] | |||||
Ecart type des résidus : 0.1027 pour 30 degrés de liberté | |||||
R2 multiple : 0.9891 - R2 ajusté : 0.9888 | |||||
Statistique F : 2731 pour 1 et 30 ddl - valeur de p : < 2.22e-16 | |||||
Notez bien que, quand on réajuste un modèle simplifié, les paramètres restants doivent être recalculés. En effet, le paramètre \(\beta_2\) relatif au diamètre2 valait 11,2 dans le modèle trees_lm4 plus haut. Une fois les autres termes éliminés, ce paramètre devient \(\beta\) qui vaut 7,30 dans ce modèle trees_lm5 simplifié.
Le modèle trees_lm5 revient aussi (autre point de vue) à transformer d’abord le diamètre en diamètre2 et à effectuer ensuite une régression linéaire simple entre deux variables, volume et diametre2. Nous ne sommes donc plus, ici, dans une régression polynomiale et c’est la raison pour laquelle une simplification de la régression polynomiale d’ordre deux est envisageable exceptionnellement alors qu’elle n’est pas conseillée pour un ordre supérieur :
Modèle linéaire | |||||
|---|---|---|---|---|---|
| |||||
Terme | Valeur estimée | Ecart type | Valeur de t | Valeur de p | |
| 7.3 | 0.14 | 52.3 | < 2·10-16 | *** |
0 <= '***' < 0.001 < '**' < 0.01 < '*' < 0.05 | |||||
Etendue des résidus : [-0.1947, 0.1824] | |||||
Ecart type des résidus : 0.1027 pour 30 degrés de liberté | |||||
R2 multiple : 0.9891 - R2 ajusté : 0.9888 | |||||
Statistique F : 2731 pour 1 et 30 ddl - valeur de p : < 2.22e-16 | |||||
Notez que nous obtenons bien évidemment exactement les mêmes résultats si nous transformons d’abord les données ou si nous intégrons le calcul à l’intérieur de la formule qui décrit le modèle.
Faites bien attention de ne pas comparer le R2 avec ordonnée à l’origine fixée à zéro ici dans notre modèle trees_lm5 avec les R2 des modèles trees_lm ou trees_lm4 qui ont ce paramètre estimé. Rappelez-vous que le R2 est calculé différemment dans les deux cas ! Donc, nous voilà une fois de plus face à un nouveau modèle pour lequel il nous est difficile de décider s’il est meilleur que les précédents. Avant de comparer, élaborons un tout dernier modèle, le plus complexe, qui reprend à la fois notre régression polynomiale d’ordre deux sur le diamètre et la hauteur. Autrement dit, une régression à la fois multiple et polynomiale.
trees_lm6 <- lm(data = trees, volume ~ diameter + I(diameter^2) + height)
summary(trees_lm6) |>
tabularise()Modèle linéaire | |||||
|---|---|---|---|---|---|
| |||||
Terme | Valeur estimée | Ecart type | Valeur de t | Valeur de p | |
| -0.2671 | 0.28489 | -0.938 | 3.57·10-01 |
|
| -3.2814 | 1.46340 | -2.242 | 3.34·10-02 | * |
| 11.8917 | 2.01925 | 5.889 | 2.83·10-06 | *** |
| 0.0348 | 0.00817 | 4.259 | 2.23·10-04 | *** |
0 <= '***' < 0.001 < '**' < 0.01 < '*' < 0.05 | |||||
Etendue des résidus : [-0.1217, 0.1256] | |||||
Ecart type des résidus : 0.07436 pour 27 degrés de liberté | |||||
R2 multiple : 0.977 - R2 ajusté : 0.9745 | |||||
Statistique F : 382.8 pour 3 et 27 ddl - valeur de p : < 2.22e-16 | |||||
Ah ha, ceci est bizarre ! Le R2 ajusté nous indique que le modèle serait très bon puisqu’il grimpe presque à 0,98. Le terme \(\beta_2\) en diamètre2 reste très significatif, … mais la pente relative à la hauteur \(\beta_3\) est maintenant elle aussi très significative alors que dans le modèle multiple trees_lm3 ce n’était pas le cas. De plus, l’ordonnée à l’origine n’est plus significativement différente de zéro. Bienvenue dans les instabilités liées aux intercorrélations entre paramètres dans les modèles linéaires complexes !