9.2 Positionnement multidimensionnel (MDS)
Revenons à présent sur les techniques statistiques d’analyse de données multivariées. Le positionnement multidimensionnel, ou multidimensional scaling en anglais, d’où son acronyme fréquemment utilisé en français également : le MDS, est une façon de représenter clairement l’information contenue dans une matrice de distances. Au départ, nous avons p colonnes et n lignes dans le tableau cas par variables, c’est-à-dire, p variables quantitatives mesurées sur n individus distincts. Nous voulons déterminer les similitudes ou différences de ces n individus en les visualisant sur une carte où la distance d’un individu à l’autre représente cette similitude. Plus deux individus sont proches, plus ils sont semblables. Ces distances entre paires d’individus, nous les avons déjà calculées dans la matrice de distance au module 6. Mais comment les représenter ? En effet, une représentation exacte ne peut se faire que dans un espace à p dimensions (même nombre de dimensions que de variables initiales). Donc, afin de réduire les dimensions à seulement deux ou trois, nous allons devoir “tordre” les données tout en acceptant de perdre un peu d’information lors de cette transformation.

Ce que nous allons faire avec la MDS correspond exactement à cela : nous allons littéralement “écraser” les données dans un plan (deux dimensions) ou dans un espace à trois dimensions. C’est donc ce qu’on appelle une technique de réduction de dimensions ou d’ordination. Il existe, en réalité, plusieurs techniques de MDS. Elles répondent toutes au schéma suivant :
- À partir d’un tableau multivarié de n lignes et p colonnes, nous calculons une matrice de distances (le choix de la transformation initiale éventuelle et de la métrique de distance utilisée sont totalement libres ici25).
- Nous souhaitons représenter une carte (nuage de points) à k dimensions (k = 2, éventuellement k = 3) où les n individus seront placés de telle façon que les proximités exprimées par des valeurs faibles dans la matrice de dissimilarité soient respectées autant que possible entre tous les points.
- Pour y arriver les points sont placés successivement sur la carte et réajustés afin de minimiser une fonction de coût, encore appelée fonction de stress qui quantifie de combien nous avons dû tordre le réseau à p dimensions initiales représentant les distances entre toutes les paires. C’est en adoptant différentes fonctions de stress que nous aboutissons aux différentes variantes de MDS. La fonction de stress est représentée graphiquement (voir ci-dessous) pour diagnostiquer le traitement réalisé et décider si la représentation est utilisable (pas trop tordue) ou non.
- Le positionnement des points faisant intervenir un facteur aléatoire (choix des points à placer en premier, réorganisation ensuite pour minimiser la fonction de stress), le résultat final peut varier d’une fois à l’autre sur les mêmes données, voir ne pas converger vers une solution stable. Il faut en être conscient.
Nous vous épargnons ici les développements mathématiques qui mènent à la définition de la fonction de stress. Nous nous concentrerons sur les principales techniques et sur leurs propriétés utiles en pratique en biologie.
À vous de jouer !
Dans R, il existe plus d’une dizaine de fonctions différentes pour réaliser le MDS. Afin de vous simplifier le travail et de pouvoir traiter votre MDS comme d’autres analyses similaires, nous vous proposons une interface simplifiée au travers de la fonction mds() qui est rendue disponible grâce à l’instruction suivante à utiliser systématiquement en tête de script ou de document Quarto ou R Markdown :
9.2.1 MDS métrique ou PCoA
La forme classique, aussi appelée MDS métrique ou analyse en coordonnées principales (Principal Coordinates Analysis en anglais ou PCoA), va projeter le nuage de points à p dimensions dans un espace réduit à k = deux dimensions (voire éventuellement à trois dimensions). Cette projection se fait de manière similaire à une ombre chinoise projetée d’un objet tridimensionnel sur une surface plane en deux dimensions.

Notez que l’Analyse en Composantes Principales (ACP) que nous avons étudiée au module 7 est en fait équivalente à une Analyse en Coordonnées Principales sur une matrice de distances euclidiennes (MDS métrique). Nous avons vu que l’ACP se résout par un calcul matriciel optimisé. Dans le cas de la MDS métrique, c’est une approche d’optimisation itérative qui est utilisée pour obtenir un résultat sensiblement proche… et cette approche itérative pourra être réutilisée plus tard sur d’autres métriques pour traiter des cas plus généraux.
À vous de jouer !
Considérons un relevé de couverture végétale en 24 stations concernant 44 plantes répertoriées sur le site de l’étude, par exemple, Callvulg est Calluna vulgaris, Empenigr est Empetrum nigrum, etc. Les valeurs sont les couvertures végétales observées pour chaque plante sur le site, exprimées en pour cent. La première colonne nommée rownames à l’importation contient les identifiants des stations (chaînes de caractères). Nous la renommons donc pour un intitulé plus explicite : station.
# station Callvulg Empenigr Rhodtome Vaccmyrt Vaccviti Pinusylv Descflex
# <char> <num> <num> <num> <num> <num> <num> <num>
# 1: 18 0.55 11.13 0.00 0.00 17.80 0.07 0.00
# 2: 15 0.67 0.17 0.00 0.35 12.13 0.12 0.00
# 3: 24 0.10 1.55 0.00 0.00 13.47 0.25 0.00
# 4: 27 0.00 15.13 2.42 5.92 15.97 0.00 3.70
# 5: 23 0.00 12.68 0.00 0.00 23.73 0.03 0.00
# 6: 19 0.00 8.92 0.00 2.42 10.28 0.12 0.02
# 7: 22 4.73 5.12 1.55 6.05 12.40 0.10 0.78
# 8: 16 4.47 7.33 0.00 2.15 4.33 0.10 0.00
# 9: 28 0.00 1.63 0.35 18.27 7.13 0.05 0.40
# 10: 13 24.13 1.90 0.07 0.22 5.30 0.12 0.00
# 11: 14 3.75 5.65 0.00 0.08 5.30 0.10 0.00
# 12: 20 0.02 6.45 0.00 0.00 14.13 0.07 0.00
# 13: 25 0.00 6.93 0.00 0.00 10.60 0.02 0.10
# 14: 7 0.00 5.30 0.00 0.00 8.20 0.00 0.05
# 15: 5 0.00 0.13 0.00 0.00 2.75 0.03 0.00
# 16: 6 0.30 5.75 0.00 0.00 10.50 0.10 0.00
# 17: 3 0.03 3.65 0.00 0.00 4.43 0.00 0.00
# 18: 4 3.40 0.63 0.00 0.00 1.98 0.05 0.05
# 19: 2 0.05 9.30 0.00 0.00 8.50 0.03 0.00
# 20: 9 0.00 3.47 0.00 0.25 20.50 0.25 0.00
# 21: 12 0.25 11.50 0.00 0.00 15.80 1.20 0.00
# 22: 10 0.25 11.00 0.00 0.00 11.90 0.25 0.00
# 23: 11 2.37 0.67 0.00 0.00 12.90 0.80 0.00
# 24: 21 0.00 16.00 4.00 15.00 25.00 0.25 0.50
# station Callvulg Empenigr Rhodtome Vaccmyrt Vaccviti Pinusylv Descflex
# Betupube Vacculig Diphcomp Dicrsp Dicrfusc Dicrpoly Hylosple Pleuschr
# <num> <num> <num> <num> <num> <num> <num> <num>
# 1: 0.00 1.60 2.07 0.00 1.62 0.00 0.00 4.67
# 2: 0.00 0.00 0.00 0.33 10.92 0.02 0.00 37.75
# 3: 0.00 0.00 0.00 23.43 0.00 1.68 0.00 32.92
# 4: 0.00 1.12 0.00 0.00 3.63 0.00 6.70 58.07
# 5: 0.00 0.00 0.00 0.00 3.42 0.02 0.00 19.42
# 6: 0.00 0.00 0.00 0.00 0.32 0.02 0.00 21.03
# 7: 0.02 2.00 0.00 0.03 37.07 0.00 0.00 26.38
# 8: 0.00 0.00 0.00 1.02 25.80 0.23 0.00 18.98
# 9: 0.00 0.20 0.00 0.30 0.52 0.20 9.97 70.03
# 10: 0.00 0.00 0.07 0.02 2.50 0.00 0.00 5.52
# 11: 0.00 0.00 0.00 0.00 11.32 0.00 0.00 7.75
# 12: 0.00 0.47 0.00 0.85 1.87 0.08 1.35 13.73
# 13: 0.02 0.05 0.07 14.02 10.82 0.00 0.02 28.77
# 14: 0.00 8.10 0.28 0.00 0.45 0.03 0.00 0.10
# 15: 0.00 0.00 0.00 0.00 0.25 0.03 0.00 0.03
# 16: 0.00 0.00 0.00 0.00 0.85 0.00 0.00 0.05
# 17: 0.00 1.65 0.50 0.00 0.55 0.00 0.00 0.05
# 18: 0.00 0.03 0.00 0.00 0.20 0.00 0.00 1.53
# 19: 0.00 0.00 0.00 0.00 0.03 0.00 0.00 0.75
# 20: 0.00 0.00 0.25 0.00 0.38 0.25 0.00 4.07
# 21: 0.00 0.00 0.00 0.25 0.25 0.00 0.00 6.00
# 22: 0.00 0.00 0.00 0.00 0.25 0.25 0.00 0.67
# 23: 0.00 0.00 0.00 0.00 0.25 0.25 0.00 17.70
# 24: 0.25 0.00 0.00 0.25 0.25 3.00 0.00 2.00
# Betupube Vacculig Diphcomp Dicrsp Dicrfusc Dicrpoly Hylosple Pleuschr
# Polypili Polyjuni Polycomm Pohlnuta Ptilcili Barbhatc Cladarbu Cladrang
# <num> <num> <num> <num> <num> <num> <num> <num>
# 1: 0.02 0.13 0.00 0.13 0.12 0.00 21.73 21.47
# 2: 0.02 0.23 0.00 0.03 0.02 0.00 12.05 8.13
# 3: 0.00 0.23 0.00 0.32 0.03 0.00 3.58 5.52
# 4: 0.00 0.00 0.13 0.02 0.08 0.08 1.42 7.63
# 5: 0.02 2.12 0.00 0.17 1.80 0.02 9.08 9.22
# 6: 0.02 1.58 0.18 0.07 0.27 0.02 7.23 4.95
# 7: 0.00 0.00 0.00 0.10 0.03 0.00 6.10 3.60
# 8: 0.00 0.02 0.00 0.13 0.10 0.00 7.13 14.03
# 9: 0.00 0.08 0.00 0.07 0.03 0.00 0.17 0.87
# 10: 0.00 0.02 0.00 0.03 0.25 0.07 23.07 23.67
# 11: 0.00 0.30 0.02 0.07 0.00 0.00 17.45 1.32
# 12: 0.07 0.05 0.00 0.12 0.00 0.00 6.80 11.22
# 13: 0.00 6.98 0.13 0.00 0.22 0.00 6.00 2.25
# 14: 0.00 0.25 0.00 0.03 0.00 0.00 35.00 42.50
# 15: 0.18 0.65 0.00 0.00 0.00 0.00 18.50 59.00
# 16: 0.03 0.08 0.00 0.00 0.08 0.00 39.00 37.50
# 17: 0.00 0.00 0.00 0.03 0.03 0.00 8.80 29.50
# 18: 0.00 0.10 0.00 0.05 0.00 0.00 15.73 20.03
# 19: 0.00 0.03 0.00 0.00 0.03 0.00 0.48 24.50
# 20: 0.00 0.25 0.00 0.25 0.25 0.00 0.46 4.00
# 21: 0.00 0.00 0.00 0.25 0.00 0.00 3.60 14.60
# 22: 0.00 0.25 0.00 0.25 0.00 0.00 1.30 8.70
# 23: 0.25 0.25 0.00 0.25 0.67 0.00 9.67 29.80
# 24: 0.00 0.25 0.25 0.25 10.00 3.00 0.70 4.70
# Polypili Polyjuni Polycomm Pohlnuta Ptilcili Barbhatc Cladarbu Cladrang
# Cladstel Cladunci Cladcocc Cladcorn Cladgrac Cladfimb Cladcris Cladchlo
# <num> <num> <num> <num> <num> <num> <num> <num>
# 1: 3.50 0.30 0.18 0.23 0.25 0.25 0.23 0.00
# 2: 0.18 2.65 0.13 0.18 0.23 0.25 1.23 0.00
# 3: 0.07 8.93 0.00 0.20 0.48 0.00 0.07 0.10
# 4: 2.55 0.15 0.00 0.38 0.12 0.10 0.03 0.00
# 5: 0.05 0.73 0.08 1.42 0.50 0.17 1.78 0.05
# 6: 22.08 0.25 0.10 0.25 0.18 0.10 0.12 0.05
# 7: 0.23 2.38 0.17 0.13 0.18 0.20 0.20 0.02
# 8: 0.02 0.82 0.15 0.05 0.22 0.22 0.17 0.00
# 9: 0.00 0.05 0.02 0.03 0.07 0.10 0.02 0.00
# 10: 11.90 0.95 0.17 0.05 0.23 0.18 0.57 0.02
# 11: 0.12 23.68 0.22 0.50 0.15 0.23 0.97 0.00
# 12: 0.05 4.75 0.03 0.12 0.22 0.18 0.07 0.00
# 13: 0.00 0.80 0.12 0.57 0.17 0.15 0.07 0.00
# 14: 0.28 0.35 0.08 0.20 0.25 0.18 0.13 0.08
# 15: 0.98 0.28 0.23 0.23 0.23 0.10 0.05 0.00
# 16: 11.30 3.45 0.18 0.20 0.25 0.25 0.23 0.03
# 17: 55.60 0.25 0.08 0.25 0.25 0.15 0.10 0.03
# 18: 28.20 0.73 0.10 0.15 0.13 0.10 0.15 0.00
# 19: 75.00 0.20 0.00 0.03 0.03 0.05 0.03 0.03
# 20: 84.30 0.25 0.25 0.25 0.25 0.25 0.25 0.25
# 21: 63.30 1.30 0.00 0.25 0.25 0.25 0.25 0.00
# 22: 84.30 0.25 0.25 0.25 0.00 0.25 0.25 0.25
# 23: 31.80 2.53 0.25 0.25 0.25 0.00 0.25 0.00
# 24: 10.90 0.25 0.00 0.05 0.25 0.25 0.25 0.25
# Cladstel Cladunci Cladcocc Cladcorn Cladgrac Cladfimb Cladcris Cladchlo
# Cladbotr Cladamau Cladsp Cetreric Cetrisla Flavniva Nepharct Stersp
# <num> <num> <num> <num> <num> <num> <num> <num>
# 1: 0.00 0.08 0.02 0.02 0.00 0.12 0.02 0.62
# 2: 0.00 0.00 0.00 0.15 0.03 0.00 0.00 0.85
# 3: 0.02 0.00 0.00 0.78 0.12 0.00 0.00 0.03
# 4: 0.02 0.00 0.02 0.00 0.00 0.00 0.00 0.00
# 5: 0.05 0.00 0.00 0.00 0.00 0.02 0.00 1.58
# 6: 0.02 0.00 0.00 0.00 0.00 0.02 0.00 0.28
# 7: 0.00 0.00 0.02 0.02 0.00 0.00 0.00 0.00
# 8: 0.00 0.00 0.02 0.18 0.08 0.00 0.00 0.03
# 9: 0.02 0.00 0.00 0.00 0.02 0.00 0.00 0.02
# 10: 0.07 0.00 0.07 0.18 0.02 0.00 0.00 0.03
# 11: 0.00 0.00 0.00 0.68 0.02 0.00 0.00 0.33
# 12: 0.02 0.00 0.02 0.15 0.00 0.00 0.02 0.00
# 13: 0.00 0.00 0.02 0.03 0.02 0.00 4.87 0.10
# 14: 0.00 0.00 0.00 0.05 0.00 0.23 0.20 0.93
# 15: 0.00 0.03 0.00 0.18 0.00 0.28 0.00 10.28
# 16: 0.00 0.00 0.03 0.35 0.00 0.08 0.00 0.03
# 17: 0.00 0.03 0.00 0.05 0.00 0.15 0.15 0.28
# 18: 0.00 0.00 0.05 0.28 0.05 10.03 0.00 0.95
# 19: 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
# 20: 0.00 0.00 0.25 0.25 0.25 0.67 0.00 0.00
# 21: 0.00 0.00 0.00 0.00 0.25 0.00 0.00 0.00
# 22: 0.00 0.00 0.00 0.25 0.25 0.25 0.00 0.25
# 23: 0.00 0.00 0.00 0.00 0.25 0.00 0.00 0.93
# 24: 0.25 0.00 0.00 0.00 0.67 0.00 0.00 0.00
# Cladbotr Cladamau Cladsp Cetreric Cetrisla Flavniva Nepharct Stersp
# Peltapht Icmaeric Cladcerv Claddefo Cladphyl
# <num> <num> <num> <num> <num>
# 1: 0.02 0.00 0.00 0.25 0.00
# 2: 0.00 0.00 0.00 1.00 0.00
# 3: 0.00 0.00 0.00 0.33 0.00
# 4: 0.07 0.00 0.00 0.15 0.00
# 5: 0.33 0.00 0.00 1.97 0.00
# 6: 0.00 0.00 0.00 0.37 0.00
# 7: 0.00 0.00 0.00 0.15 0.00
# 8: 0.00 0.07 0.00 0.67 0.00
# 9: 0.00 0.00 0.00 0.08 0.00
# 10: 0.02 0.00 0.00 0.47 0.00
# 11: 0.00 0.02 0.00 1.57 0.05
# 12: 0.00 0.00 0.00 1.20 0.00
# 13: 0.07 0.00 0.02 0.05 0.00
# 14: 0.00 0.03 0.00 0.10 0.00
# 15: 0.00 0.10 0.00 0.25 0.00
# 16: 0.00 0.00 0.00 0.28 0.00
# 17: 0.00 0.00 0.00 0.08 0.00
# 18: 0.00 0.00 0.05 0.08 0.00
# 19: 0.00 0.00 0.03 0.03 0.00
# 20: 0.00 0.00 0.00 0.25 0.25
# 21: 0.00 0.00 0.00 0.25 0.00
# 22: 0.00 0.00 0.00 0.25 0.25
# 23: 0.25 0.00 0.00 0.00 0.25
# 24: 0.00 0.00 0.00 0.40 0.00
# Peltapht Icmaeric Cladcerv Claddefo CladphylTypiquement, ce genre de données ne contient pas d’information constructive lorsqu’une plante est simultanément absente de deux stations (doubles zéros). Donc, les métriques euclidienne et Manhattan ne conviennent pas ici. Nous devons choisir entre distance de Bray-Curtis ou Canberra en fonction de l’importance que nous souhaitons donner aux plantes les plus rares (avec couverture végétale faible et/ou absentes de la majorité des stations).
Afin de décider quelle métrique utiliser, visualisons à présent l’abondance ou la rareté des différentes plantes :
veg %>.%
sselect(., -station) %>.% # Colonne 'station' pas utile ici
spivot_longer(., everything(), names_to = "espèce", values_to = "couverture") %>.%
chart(., espèce ~ couverture) +
geom_boxplot() + # Boites de dispersion
labs(x = "Espèce", y = "Couverture [%]")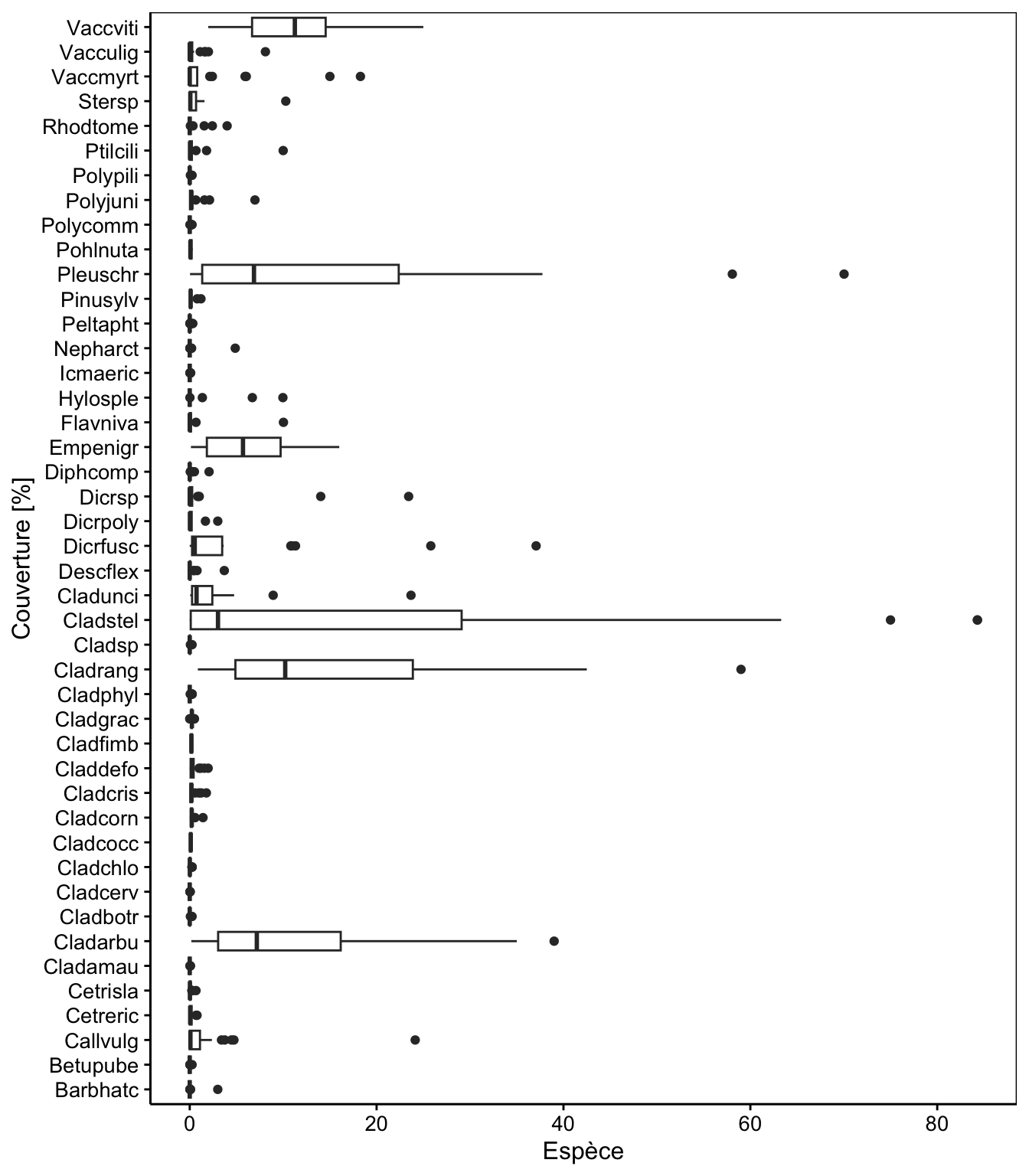
Comme nous pouvions nous y attendre, sept ou huit espèces dominent la couverture végétale et les autres données sont complètement écrasées à zéro sur l’axe pour la majorité des stations. Si nous utilisons la distance de Bray-Curtis, l’analyse sera pratiquement réalisée sur seulement ces quelques espèces dominantes. Avec Canberra, nous risquons par contre de donner beaucoup trop d’importance aux espèces extrêmement rares (toutes les espèces ont une importance égale avec cette métrique). Une solution intermédiaire est de transformer les données pour réduire l’écart d’importance entre les espèces abondantes et les rares, soit avec \(log(x + 1)\), soit avec \(\sqrt{\sqrt{x}}\). Voyons ce que donne la transformation logarithmique ici en utilisant la fonction log1p() dans R.
veg %>.%
sselect(., -station) %>.%
spivot_longer(., everything(), names_to = "espèce", values_to = "couverture") %>.%
chart(., espèce ~ log1p(couverture)) + # Transformation log(couverture + 1)
geom_boxplot() +
labs(x = "Espèce", y = "Couverture [%]")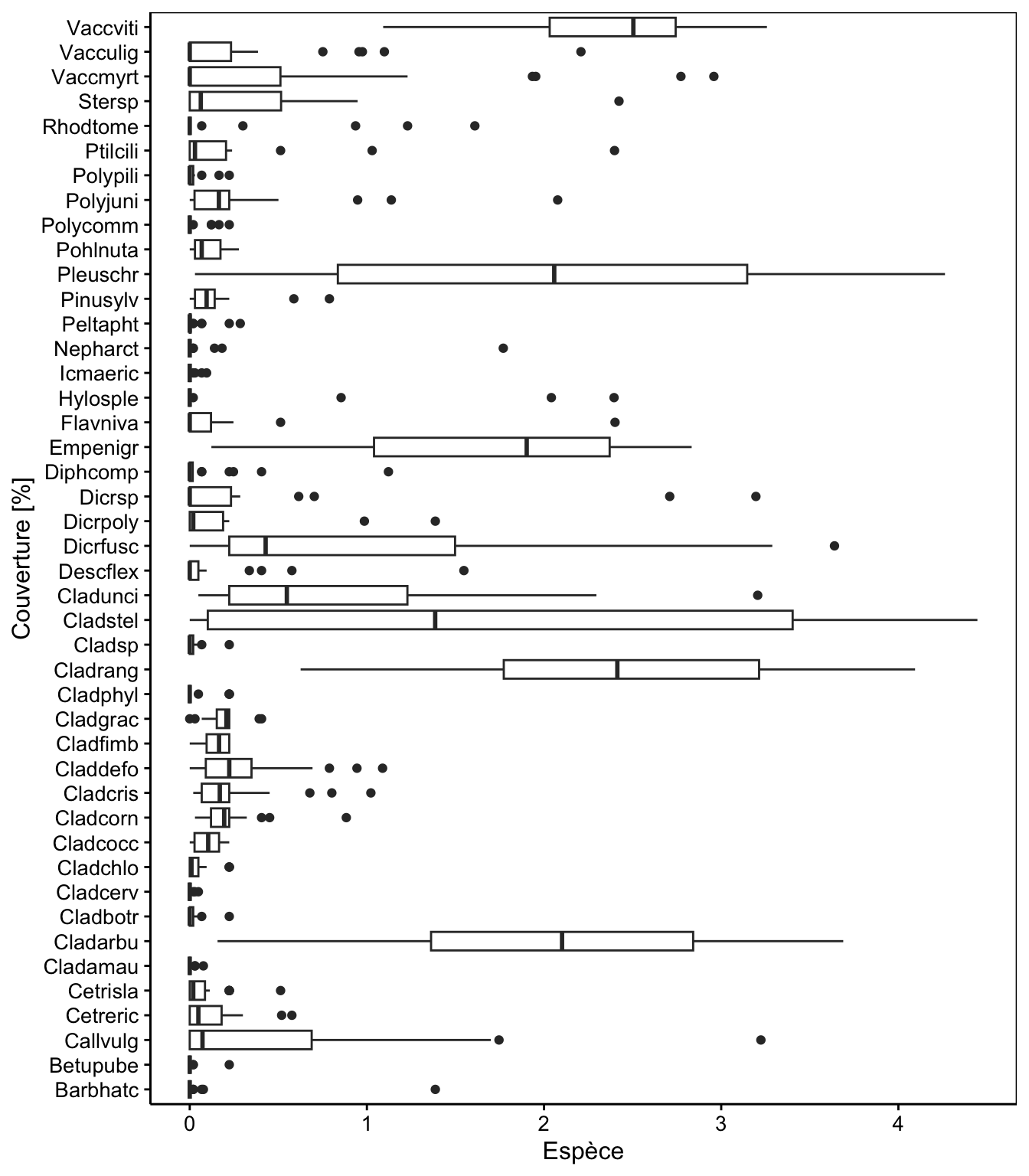
C’est nettement mieux, car les données concernant les espèces rares ne sont plus totalement écrasées vers zéro sur l’axe horizontal ! La matrice de distances de Bray-Curtis sur nos données transformées log est la première étape de l’analyse :
La PCoA va visualiser le contenu -autrement indigeste- de veg_dist de manière bien plus utile. La seconde étape consiste à calculer notre MDS métrique en utilisant mds$metric(), précédée d’une instruction qui fixe le générateur de nombre pseudo-aléatoires set.seed() si la reproductibilité des résultats est nécessaire (pour rappel, l’argument de set.seed() est un nombre entier positif choisi au hasard et à chaque fois différent).
Ensuite, troisième étape, le but étant de visualiser les distances, nous effectuons immédiatement un graphique comme suit :
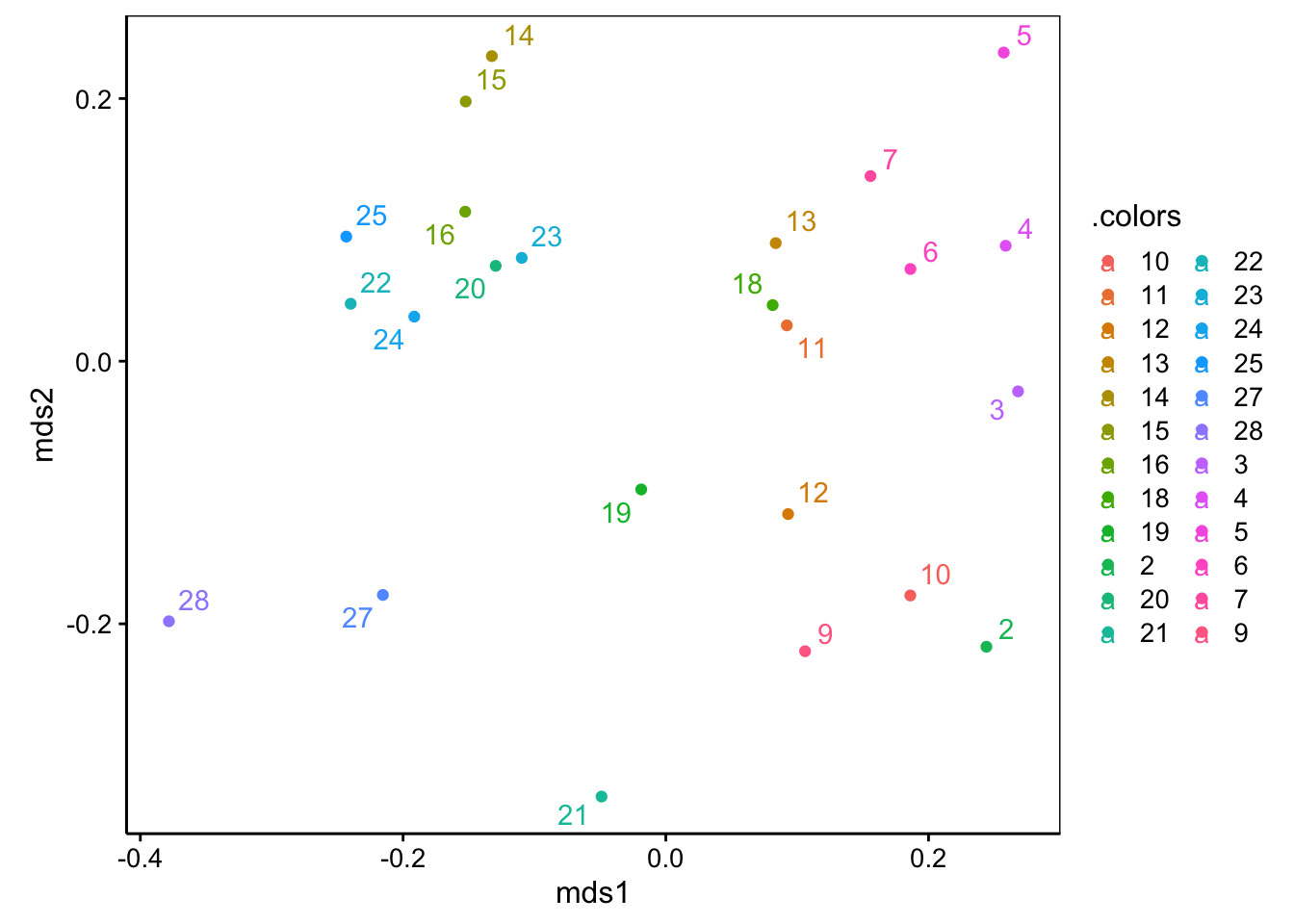
Ce graphique s’interprète comme suit :
- Des stations proches l’une de l’autre sur la carte ont des indices de dissimilarité faibles. Ces stations sont semblables du point de vue de la couverture végétale.
- Plus les stations sont éloignées les unes des autres, plus elles sont dissemblables.
- Si des regroupements apparaissent sur la carte, il se peut que ce soit des biotopes semblables, et qui diffèrent des autres regroupements. Par exemple ici, les stations 14–16, 20 et 22–25 forment un groupe relativement homogène en haut à gauche du graphique qui s’individualise du reste. Au contraire, les stations 5, 21, ou encore 27 ou 28 sont relativement isolées et constituent donc des assemblages végétaux uniques.
- Les stations aux extrémités sont des configurations extrêmes ; celles au centre sont des configurations plus courantes.
- Par contre, ni l’orientation des axes ni les valeurs absolues sur ces axes n’ont de significations particulières ici. N’en tenez pas compte.
Attention : rien ne garantit que notre MDS métrique projettée en deux dimensions soit suffisamment représentative des données dans leur ensemble. Si la méthode n’a pas réussi à représenter fidèlement les données, c’est que ces dernières sont trop complexes et ne s’y prêtent pas. Contrôlez donc toujours les indicateurs que sont les valeurs de “Goodness-of-fit” (GOF, qualité d’ajustement).
Les indicateurs “GOF” sont obtenus en utilisant la fonction glance() :
# # A tibble: 1 × 2
# GOF1 GOF2
# <dbl> <dbl>
# 1 0.527 0.554Ici GOF1 est la somme des valeurs propres obtenues lors du calcul. Retenez simplement que c’est une mesure de la part de variance du jeu de données initial qui a pu être représentée sur la carte. Plus la valeur se rapproche de 1, mieux c’est, avec des valeurs > 0.7 ou 0.8 qui restent acceptables. Le second indicateur, GOF2 est la somme uniquement des valeurs propres positives. Certains préfèrent ce dernier indicateur. En principe, les deux sont proches ou égaux. Donc, le choix de l’un ou de l’autre ne devrait pas fondamentalement modifier vos conclusions.
Ici, avec des valeurs de goodness-of-fit à peine supérieures à 50% nous pouvons considérer que la carte n’est pas suffisamment représentative. Soit nous tentons de la représenter en trois dimensions (mais c’est rarement plus lisible, car il faut quand même se résigner à présenter ce graphique 3D dans un plan à deux dimensions -l’écran de l’ordinateur, ou une feuille de papier- au final). Une autre solution lorsque la MDS métrique ne donne pas satisfaction est de se tourner vers la MDS non métrique. Ce que nous allons faire ci-dessous.
À vous de jouer !
Rappelons que la PCoA sur matrice euclidienne après standardisation ou non des données est équivalente à une Analyse en Composantes Principales (ACP) … mais avec un calcul nettement moins efficace. Dans ce contexte, la PCoA n’a donc pas grand intérêt. Elle est surtout utile lorsque vous voulez représenter des métriques de distances différentes de la distance euclidienne comme c’est le cas ici avec un choix de distances de Bray-Curtis.
9.2.2 MDS non métrique
La version non métrique de la MDS vise à réaliser une carte sur base de la matrice de distances, mais en autorisant des écarts plus flexibles entre les individus… pour autant que des individus similaires restent plus proches les uns des autres que des individus plus différents, et ce, partout sur la carte. Donc, une dissimilarité donnée pourra être “compressée” ou “dilatée”, pour autant que la distorsion garde l’ordre des points intacts. Cela signifie que la distorsion se fera via une fonction monotone croissante (une dissimilarité plus grande ne pouvant pas être représentée par une distance plus petite sur la carte).
La distorsion ainsi introduite est appelée un stress. C’est un peu comme si vous écrasiez par la force un objet 3D sur une surface plane, au lieu de juste en projeter l’ombre. Comme il existe différentes fonctions de stress, il existe donc différentes versions de MDS non métriques. Ici, nous nous attacherons à maîtriser une version implémentée dans mds$nonmetric(). Il s’agit de l’une des premières formes de MDS non métrique qui a été proposée par le statisticien Joseph Kruskal (on parle aussi du positionnement multidimensionnel de Kruskal).
La logique est la même que pour la MDS métrique :
- étape 1 : construction d’une matrice de distances,
- étape 2 : calcul du positionnement des points,
- étape 3 : réalisation de la carte et vérification de sa validité.
Repartons de la même matrice de distances déjà réalisée pour la MDS métrique qui se nomme veg_dist. Le calcul est itératif. Comme il n’est pas garanti de converger ni de donner la meilleure réponse, nous utilisons ici une fonction “intelligente” qui va effectuer une recherche plus poussée de la solution optimale, notamment en partant de différentes configurations au départ. Pour les détails et les paramètres de cet algorithme, voyez l’aide en ligne de la fonction ?vegan::metaMDS. Dans le cadre de ce cours, nous ferons confiance au travail réalisé et vérifierons juste qu’une solution est trouvée (indication *** Solution reached à la fin). Notez toutefois que le stress est quantifié. Il tourne ici autour de 0,126. Plus la valeur de stress est basse, mieux c’est naturellement.
# Run 0 stress 0.1256617
# Run 1 stress 0.1262346
# Run 2 stress 0.1262346
# Run 3 stress 0.1262346
# Run 4 stress 0.1256617
# ... New best solution
# ... Procrustes: rmse 2.394457e-06 max resid 9.288965e-06
# ... Similar to previous best
# Run 5 stress 0.1256617
# ... New best solution
# ... Procrustes: rmse 4.541188e-07 max resid 1.210067e-06
# ... Similar to previous best
# Run 6 stress 0.1256617
# ... New best solution
# ... Procrustes: rmse 5.986824e-06 max resid 2.004336e-05
# ... Similar to previous best
# Run 7 stress 0.1262346
# Run 8 stress 0.1262346
# Run 9 stress 0.1256617
# ... Procrustes: rmse 2.28195e-06 max resid 8.031862e-06
# ... Similar to previous best
# Run 10 stress 0.1262346
# Run 11 stress 0.1912665
# Run 12 stress 0.1262346
# Run 13 stress 0.1256617
# ... Procrustes: rmse 2.43849e-06 max resid 8.559077e-06
# ... Similar to previous best
# Run 14 stress 0.1256617
# ... Procrustes: rmse 5.831956e-06 max resid 2.038821e-05
# ... Similar to previous best
# Run 15 stress 0.200448
# Run 16 stress 0.1256617
# ... Procrustes: rmse 3.740821e-06 max resid 1.04062e-05
# ... Similar to previous best
# Run 17 stress 0.1262346
# Run 18 stress 0.1262346
# Run 19 stress 0.2250299
# Run 20 stress 0.2105864
# *** Best solution repeated 5 timesÀ présent, nous pouvons représenter la carte.
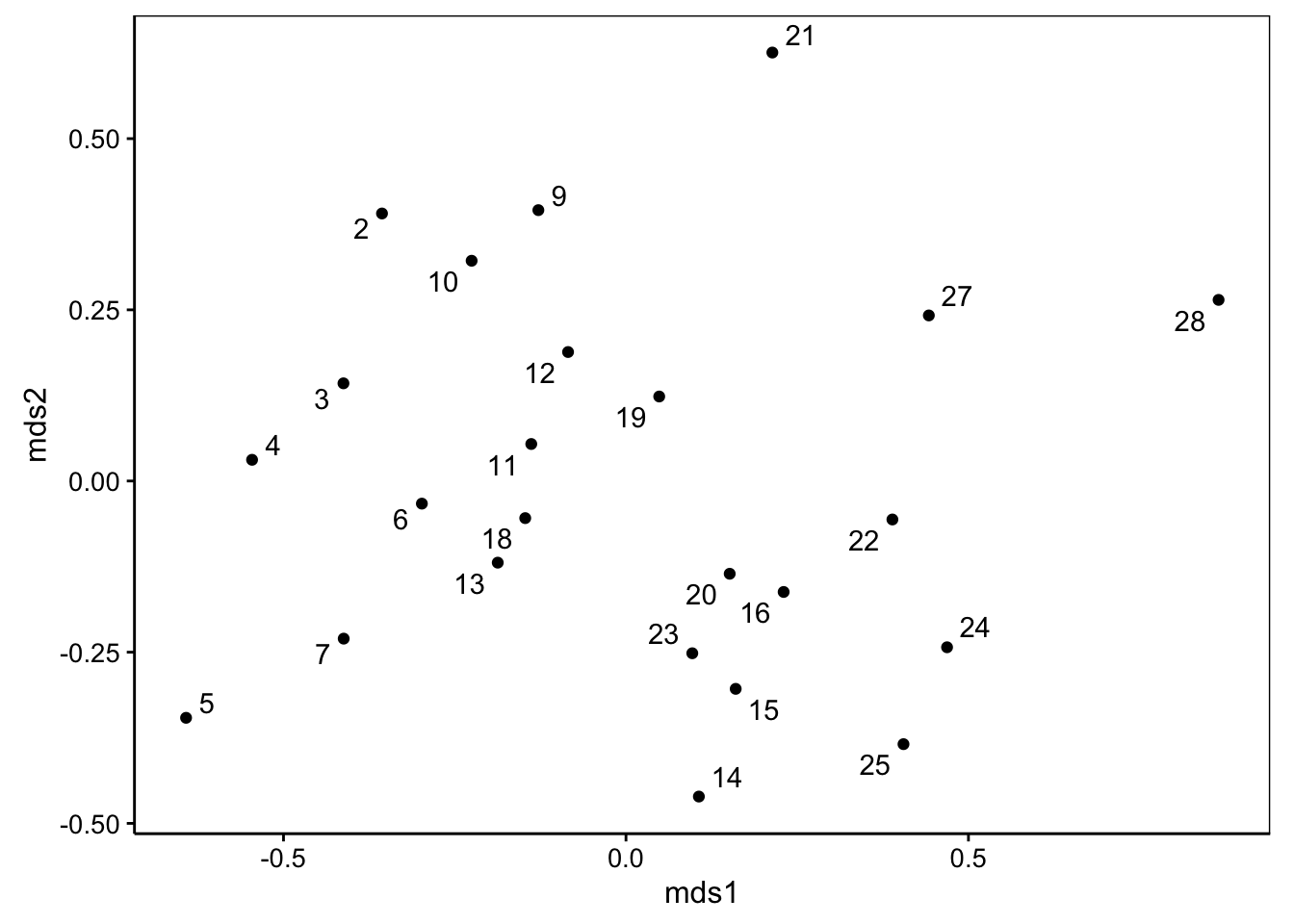
Nous avons une représentation assez différente de celle de la MDS métrique. Les stations 5, 21, 27 et 28 sont toujours isolées, mais le reste est regroupé de manière un peu plus homogène. Comment savoir si cette représentation est meilleure que la version métrique qui avait une “goodness-of-fit” relativement décevante ? En visualisant les indicateurs de qualité d’ajustement, ainsi que la fonction de stress sur un graphique dit graphique de Shepard. Comme d’habitude, glance() nous donnent les statistiques voulues.
# # A tibble: 1 × 2
# linear_R2 nonmetric_R2
# <dbl> <dbl>
# 1 0.919 0.984Le premier indicateur (R2 linéaire) est le coefficient de corrélation linéaire de Pearson entre les distances ajustées et les distances sur la carte au carré. Plus cette valeur est proche de 1, moins les distances sont tordues. Le second indicateur, le R2 non métrique est calculé comme 1 - S2 où S est le stress (tel que quantifié plus haut lors de l’appel à la fonction mds$nonmetric()). Cette dernière statistique indique si l’ordre des points respecte l’ordre des distances partout sur le graphique. Avec 0,98, la valeur est excellente ici. Ensuite le R2 linéaire nous indique de combien les différentes distances sont éventuellement distordues. Avec une valeur de 0,92, la distorsion n’est pas trop forte ici.
Le diagramme de Shepard permet de visualiser dans le détail la distorsion introduite pour parvenir à réaliser la carte en deux dimensions.
veg_sh <- shepard(veg_dist, veg_nmds)
chart(veg_sh) +
labs(x = "Dissimilarité observée", y = "Distance sur l'ordination")
Sur l’axe des abscisses, nous avons les valeurs de dissimilarité présentes dans la matrice de distances. Sur l’axe des ordonnées, le graphique représente les distances de l’ordination, c’est-à-dire, les distances entre les paires de points sur la carte. Chaque point correspond à la dissimilarité d’une paire d’individus sur X, et à la distance entre cette paire sur la carte en Y. Enfin, le trait en escalier rouge matérialise la fonction monotone croissante choisie pour distordre les distances. C’est la fonction de stress.
Ce diagramme se lit comme suit :
- Plus les points sont proches de la fonction de stress, mieux c’est. Le R2 non métrique sera également d’autant plus élevé que les points sont proches de la fonction.
- Plus la fonction de stress est linéaire, plus les distances respectent les valeurs de dissimilarités. Le R2 linéaire est lié à la plus ou moins bonne linéarité de la fonction de stress.
Vous pouvez très bien décider que seul l’ordre des individus sur la carte compte. Dans ce cas, la forme de la fonction de stress et la valeur du R2 linéaire importent peu. Seul compte la proximité la plus forte possible des points par rapport à la fonction de stress sur le diagramme de Shepard, ainsi donc que la valeur du R2 non métrique.
Si par contre, vous voulez être plus contraignant, alors, les distances seront considérées également comme importantes. Vous rechercherez une fonction de stress pas trop éloignée d’une droite, ainsi qu’un R2 linéaire élevé. Dans ce cas, nous nous rapprochons des exigences de la MDS métrique.
Ici, nous pouvons constater que les deux critères sont bons. Nous pouvons donc nous fier à la carte obtenue à l’aide de la MDS non métrique de Kruskal.
Restez toujours attentif à la taille du jeu de données que vous utilisez pour réaliser une MDS, en particuliers une MDS non métrique. Quelques centaines de lignes, cela dois passer, plusieurs dizaines de milliers ou plus, cela ne passera pas ! La limite dépend bien sûr de la puissance de votre ordinateur et de la quantité de mémoire vive disponible. Retenez toutefois que la quantité de calculs augmente drastiquement avec la taille du jeu de données à traiter.
Pour en savoir plus
La fonction
mds()donne accès à d’autres versions de MDS non métriques également. Ainsi,mds$isoMDS()oumds$monoMDS()correspondent toutes deux à la version de Kruskal, mais en utilisant une seule configuration de départ (donc, moins robuste, mais plus rapide à calculer). Lamds$sammon()est une autre forme de MDS non métrique décrite dans l’aide en ligne de?MASS::sammon.Des techniques existent pour déterminer la dimension k idéale de la carte. Le graphique des éboulis (screeplot en anglais) que nous avons utilisé en ACP, par exemple, existe ici aussi sous une autre version. Voyez ici (en anglais).
À vous de jouer !
Effectuez maintenant les exercices du tutoriel B09Lb_mds (Positionnement multidimensionnel (MDS)).
BioDataScience2::run("B09Lb_mds")Réalisez le travail B09Ia_portalr.
Travail individuel pour les étudiants inscrits au cours de Science des Données Biologiques II à l’UMONS (Q2 : analyse) à terminer avant le 2025-04-07 23:59:59.
Initiez votre projet GitHub Classroom
Voyez les explications dans le fichier README.md.
Créez un projet de groupe par quatre étudiants, que vous continuerez au module 10.
Réalisez en groupe le travail B09Ga_open_data, partie I.
Travail en groupe de 4 pour les étudiants inscrits au cours de Science des Données Biologiques II à l’UMONS (Q2 : analyse) à terminer avant le 2025-05-06 23:59:59.
Initiez votre projet GitHub Classroom
Voyez les explications dans le fichier README.md, partie I.
Chaque métrique de distance offre un éclairage différent sur les données. Elles agissent comme autant de filtres différents à votre disposition pour explorer vos données multivariées.↩︎