1.2 Régression linéaire simple
Nous allons découvrir les bases de la régression linéaire de façon intuitive. Nous utilisons le jeu de données trees qui rassemble la mesure du diamètre, de la hauteur et du volume de bois de cerisiers noirs.
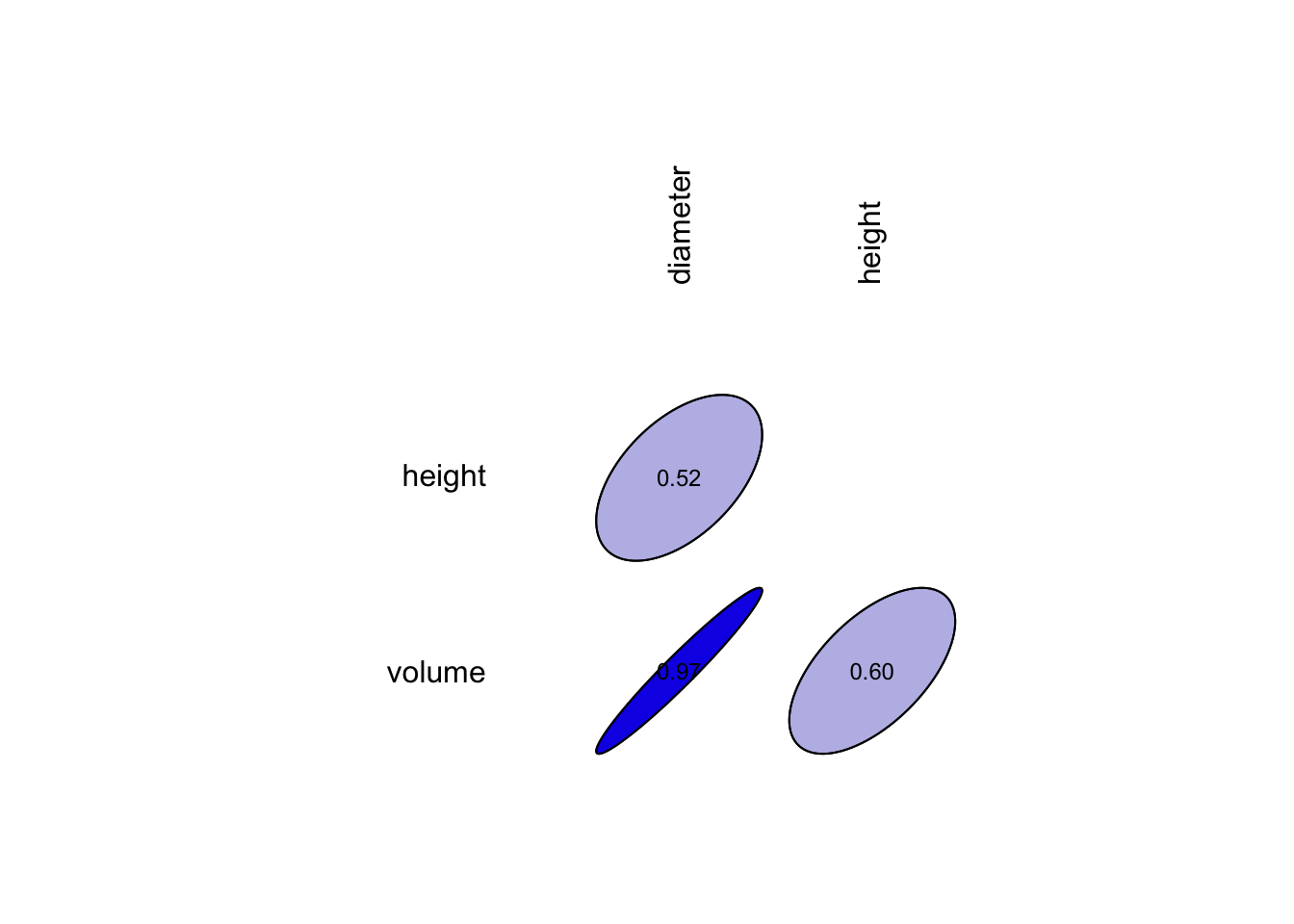
Rappelons-nous que dans le module 12 du cours science des données 1, nous avons étudié l’association de deux variables quantitatives (ou numériques). Nous utilisons donc une matrice de corrélation afin de mettre en évidence la corrélation entre nos trois variables qui composent le jeu de donnée trees.
La fonction correlation() nous renvoie un tableau de la matrice de corrélation avec l’indice de Pearson (corrélation linéaire) par défaut. C’est précisément ce coefficient qui nous intéresse dans le cadre d’une régression linéaire comme description préalable des données autant que pour nous guider dans le choix des variables les plus pertinentes.
# Matrix of Pearson's product-moment correlation:
# (calculation uses everything)
# diameter height volume
# diameter 1.000 0.519 0.967
# height 0.519 1.000 0.597
# volume 0.967 0.597 1.000Nous pouvons également observer cette matrice sous la forme d’un graphique plus convivial.
À vous de jouer !
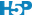
Cependant, n’oubliez pas qu’il est indispensable de visualiser les nuages de points pour ne pas tomber dans le piège mis en avant par le jeu de données artificiel appelé “quartet d’Anscombe” qui montre très bien comment des données très différentes peuvent avoir une même moyenne, une même variance et un même coefficient de corrélation. Un graphique de type matrice de nuages de points est tout indiqué ici.
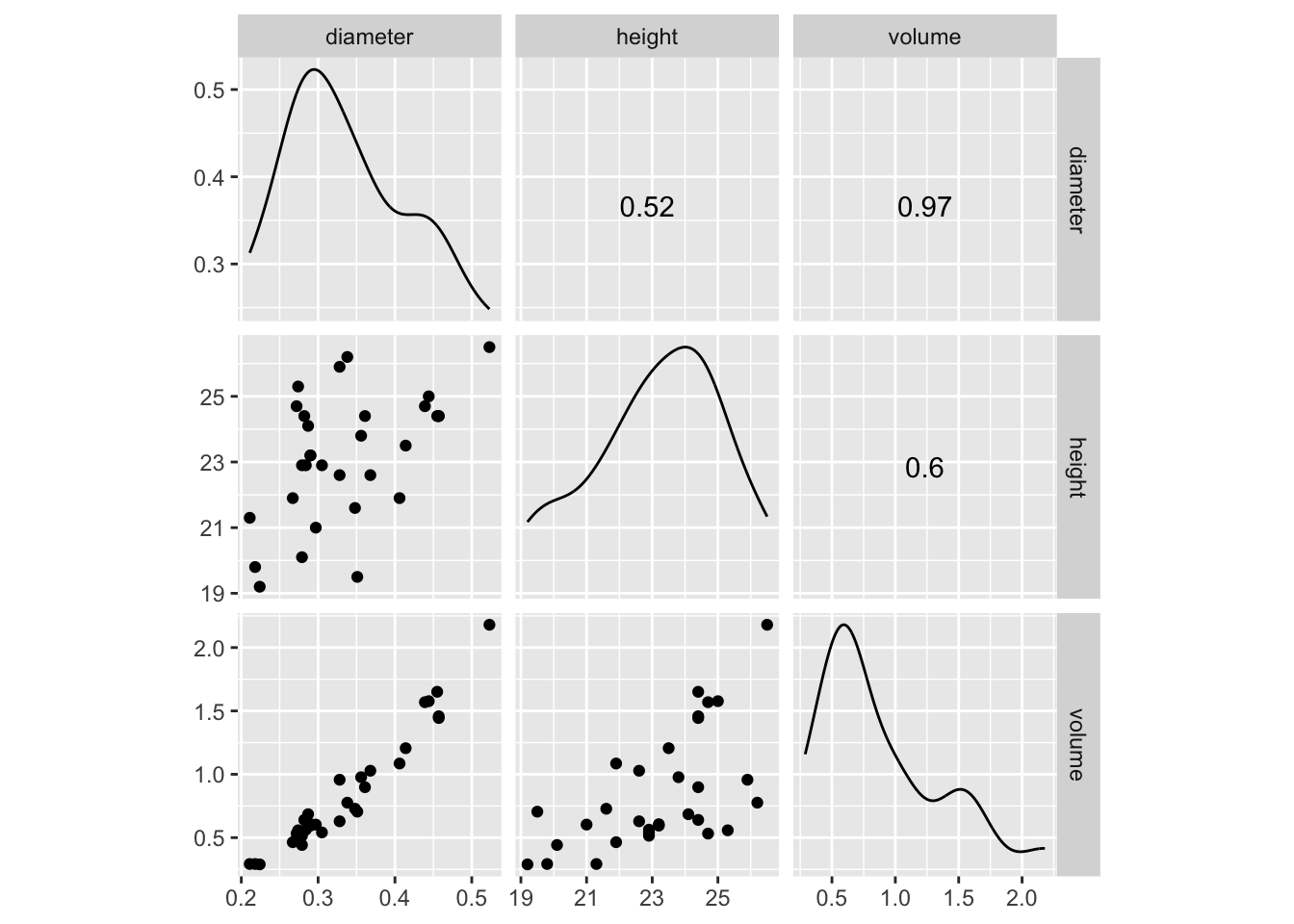
Nous observons une plus forte corrélation linéaire entre le volume et le diamètre. Intéressons nous à cette dernière association.
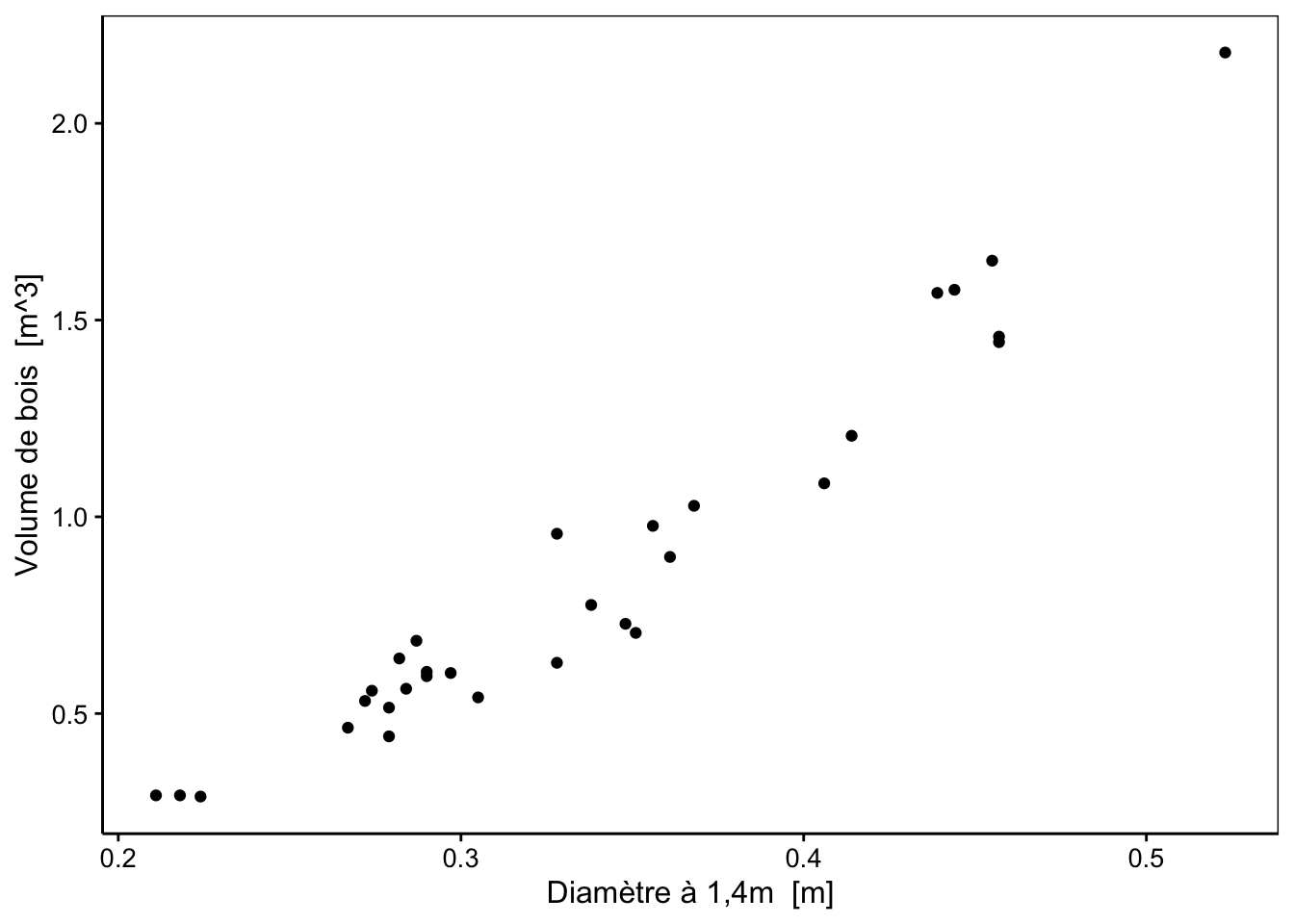
Si vous deviez ajouter une droite permettant de représenter au mieux les données, où est ce que vous la placeriez ?
Pour rappel, une droite respecte l’équation mathématique suivante :
\[y = a \cdot x + b\]
dont a est la pente (slope en anglais) et b est l’ordonnée à l’origine (intercept en anglais).
# Sélection de pentes et d'ordonnées à l'origine
models <- tibble(
model = paste("modèle", 1:4, sep = "-"),
slope = c(5, 5.5, 6, 0),
intercept = c(-0.5, -0.95, -1.5, 0.85)
)
chart(data = trees, volume ~ diameter) +
geom_point() +
geom_abline(data = models,
aes(slope = slope, intercept = intercept, color = model)) +
labs( color = "Modèle")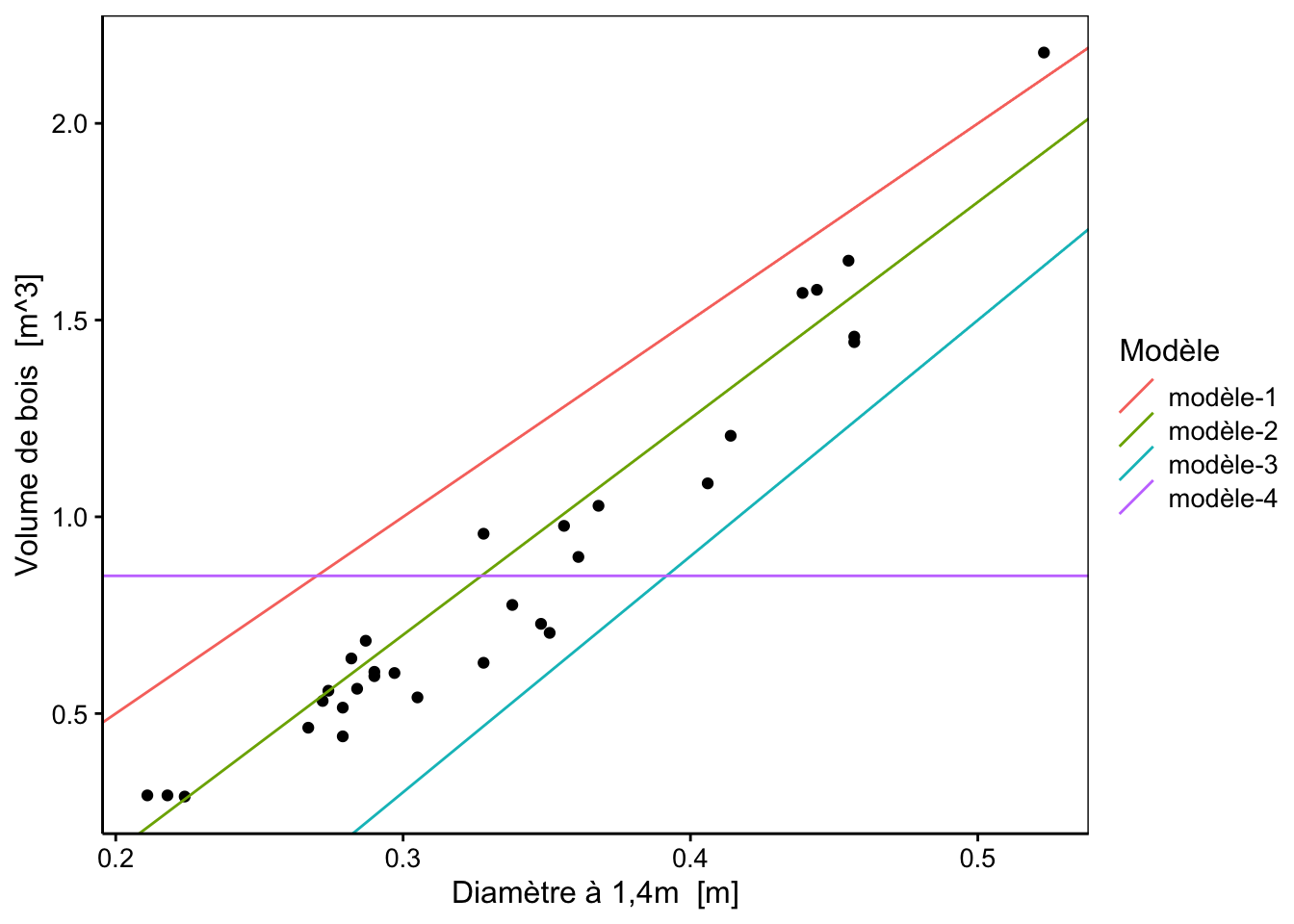
Nous avons quatre droites candidates pour représenter au mieux les observations. Quel est la meilleure d’entre elles selon vous ? Comment pourrions-nous le déterminer de manière automatique, sans devoir faire intervenir le jugement humain ?
1.2.1 Quantifier l’ajustement d’un modèle
Nous voulons identifier la meilleure droite de régression, c’est-à-dire la droite le plus proche de nos données. Nous avons besoin d’une règle qui va nous permettre de quantifier la distance de nos observations à notre modèle afin d’obtenir la droite avec la plus faible distance possible de l’ensemble de nos observations.
Décomposons le problème étape par étape et intéressons nous au modèle-1 (droite en rouge sur le graphique précédent).
- Nous allons calculer les valeurs de \(y_i\) prédites par le modèle que nous noterons par convention \(\hat y_i\) (prononcez “y chapeau” ou “y hat” en anglais) pour chaque observation \(i\).
# Calculer la valeur de y pour chaque valeur de x suivant le modèle souhaité
# Création de notre fonction
model_predict <- function(slope, intercept, x)
as.numeric(intercept + slope * x)
# Application de notre fonction
yhat <- model_predict(slope = 5, intercept = -0.5, x = trees$diameter)
yhat# [1] 0.555 0.590 0.620 0.835 0.860 0.870 0.895 0.895 0.910 0.920 0.935 0.950
# [13] 0.950 0.985 1.025 1.140 1.140 1.190 1.240 1.255 1.280 1.305 1.340 1.530
# [25] 1.570 1.695 1.720 1.775 1.785 1.785 2.115- Ensuite, nous calculons la distance entre les observations \(y_i\) et les prédictions par notre modèle \(\hat y_i\), soit \((y_i - \hat y_i)\)
Les distances que nous souhaitons calculer, sont appelées les résidus du modèle et sont notées \(\epsilon_i\) (epsilon). Nous pouvons, premièrement, visualiser ces résidus graphiquement (ici en rouge par rapport à modèle-1) :
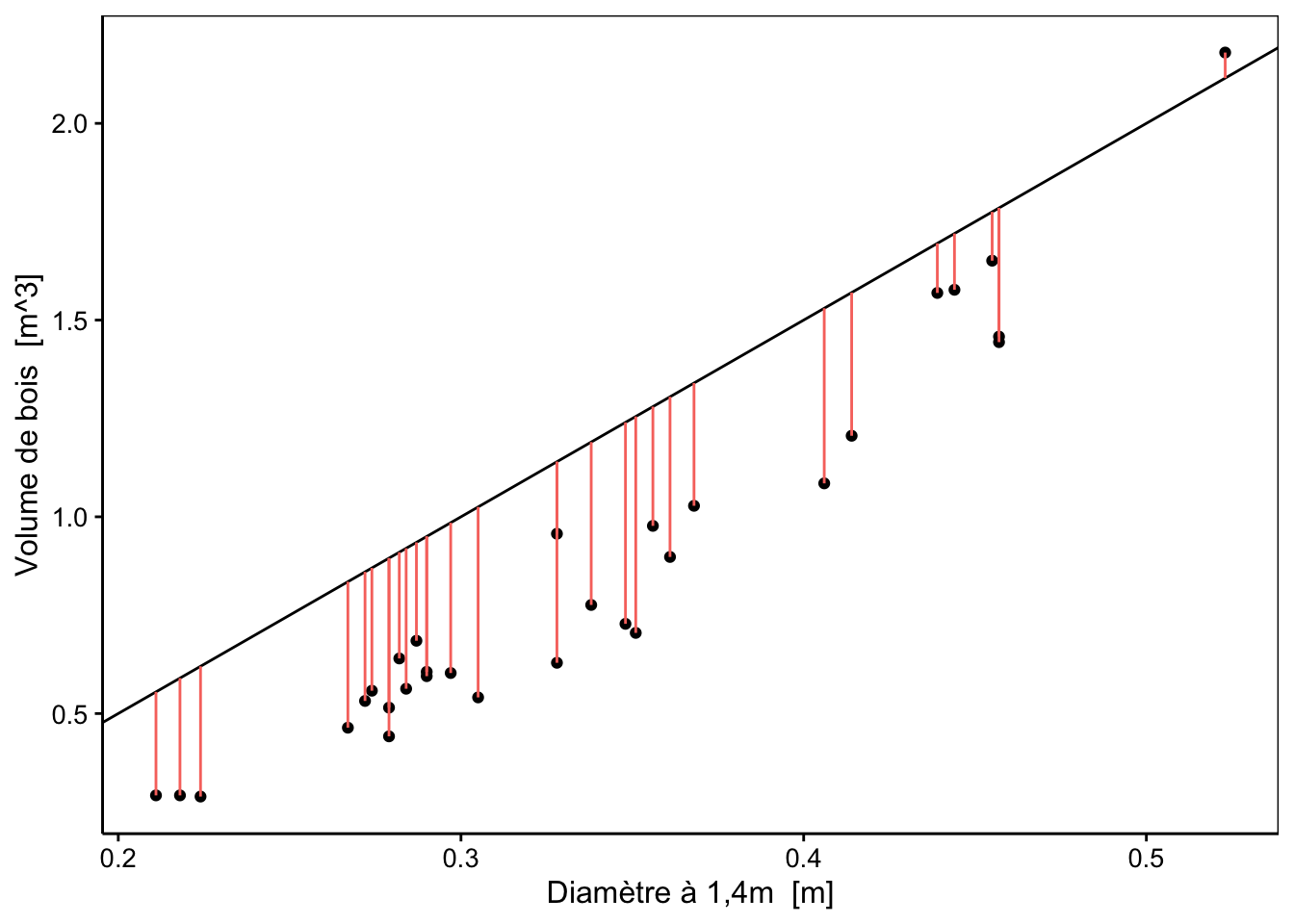
Nous pouvons ensuite facilement calculer leurs valeurs :
# [1] -0.263 -0.298 -0.331 -0.371 -0.328 -0.312 -0.453 -0.380 -0.270 -0.357
# [11] -0.250 -0.355 -0.344 -0.382 -0.484 -0.511 -0.183 -0.414 -0.512 -0.550
# [21] -0.303 -0.407 -0.312 -0.445 -0.364 -0.126 -0.143 -0.124 -0.327 -0.341
# [31] 0.065
# attr(,"label")
# [1] "Volume de bois"
# attr(,"units")
# [1] "m^3"- Définir une règle pour obtenir une valeur unique qui résume l’ensemble des distances de nos observations par rapport aux prédictions du modèle. Une première idée serait de sommer l’ensemble de nos résidus :
# [1] -10.175Appliquons ces calculs sur nos quatre modèles afin de les comparer… Le modèle pour lequel notre critère serait le plus proche de zéro serait alors considéré comme le meilleur.
| modèle-1 | modèle-2 | modèle-3 | modèle-4 |
|---|---|---|---|
| -10.18 | -1.44 | 10.39 | 0.14 |
Selon notre méthode, il en ressort que le modèle 4 est le plus approprié pour représenter au mieux nos données. Qu’en pensez vous ?
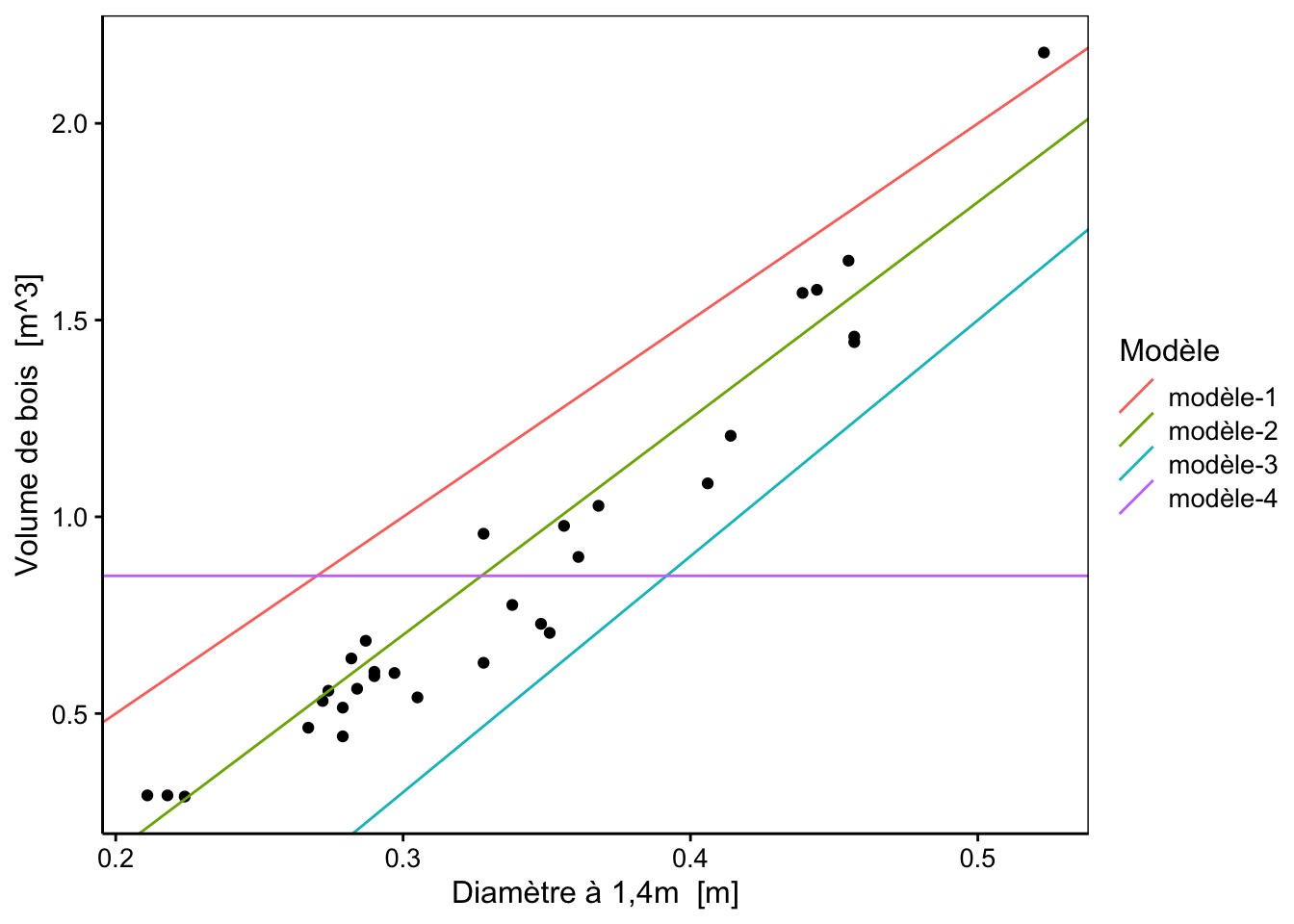
À vous de jouer !
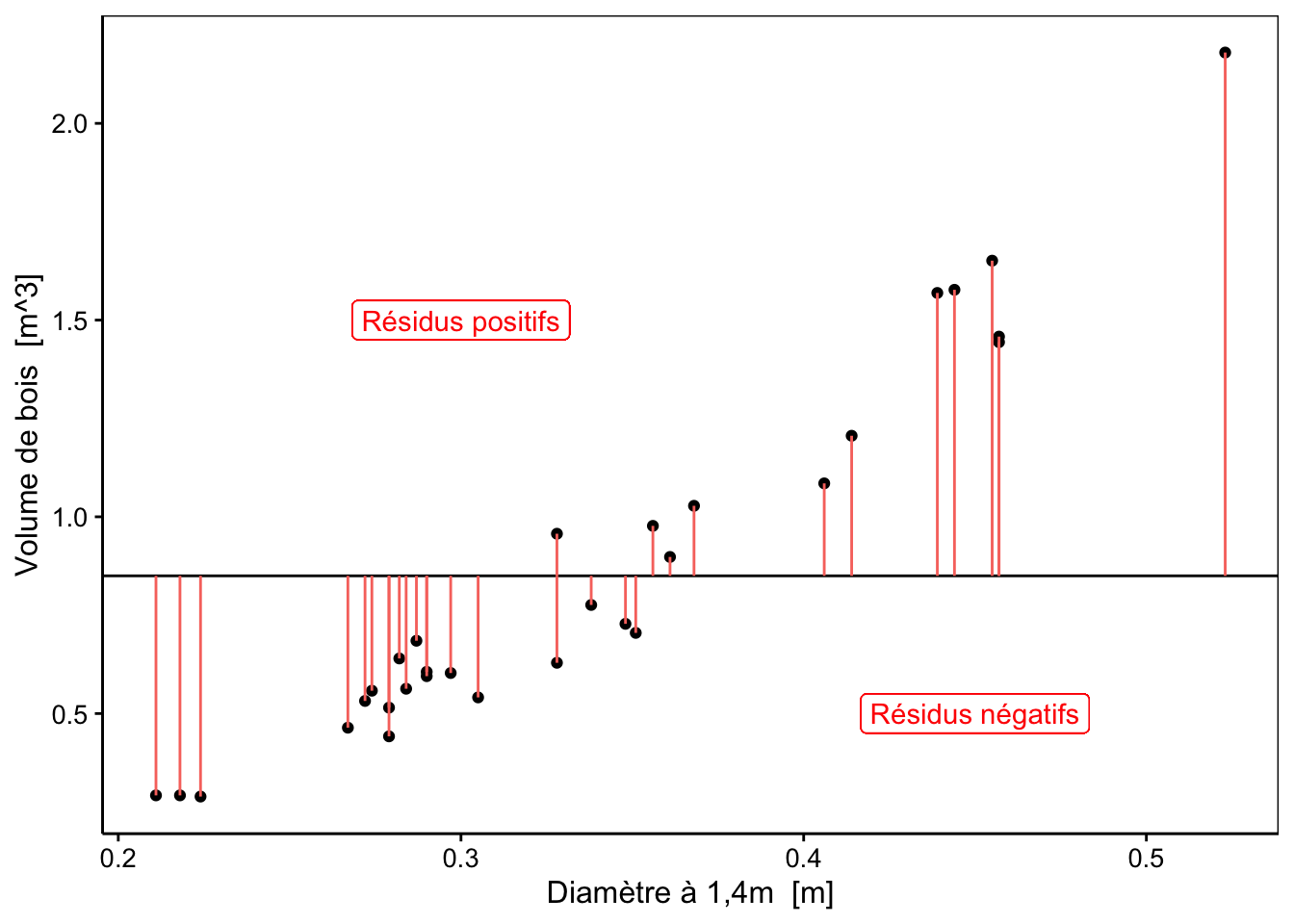
Ainsi avec notre première méthode naïve de somme des résidus, il suffit d’avoir autant de résidus positifs que négatifs pour avoir un résultat proche de zéro. Mais cela n’implique pas que les observations soient proches de la droite pour autant. Avez-vous une autre idée que de sommer les résidus ?
- Sommer le carré des résidus aurait des propriétés intéressantes car d’une part les carrés de nombres positifs et négatifs sont tous positifs, et d’autre part, plus une observation est éloignée plus sa distance au carré pèse fortement dans la somme2.
Nous obtenons les résultats suivants :
| modèle-1 | modèle-2 | modèle-3 | modèle-4 |
|---|---|---|---|
| 3.84 | 0.49 | 3.93 | 6.5 |
- Sommer les valeurs absolues des résidus mène également à des contributions toutes positives, mais sans pénaliser outre mesure les observations les plus éloignées.
Voici ce que cela donne :
| modèle-1 | modèle-2 | modèle-3 | modèle-4 |
|---|---|---|---|
| 10.3 | 3.19 | 10.39 | 11.53 |
Nous avons trouvé deux solutions intéressantes pour quantifier la distance de notre droite par rapport à nos observations. En effet, dans les deux cas, la valeur minimale est obtenue pour le modèle-2 (en vert sur le graphique) qui est aussi visuellement le meilleur des quatre.
La méthode utilisant les carrés des résidus s’appelle une régression par les moindres carrés. Notre objectif est donc de trouver les meilleures valeurs des paramètres \(a\) et \(b\) de la droite pour minimiser ce critère. Il en résulte une fonction dite objective qui dépend de \(x\) et de nos paramètres \(a\) et \(b\) à minimiser. Cette approche est la plus utilisée.
L’approche utilisant la somme de la valeur absolue des résidus est également intéressante (et elle est d’ailleurs préférable en présence de valeurs extrêmes potentiellement suspectes). Elle s’apppelle régression par la médiane ou régression par les moindres valeurs absolues des résdus, un cas particulier de la régression quantile, une technique intéressante dans le cas de non normalité des résidus et/ou de présence de valeurs extrêmes suspectes.À vous de jouer !
 Cliquez pour lancer ou exécutez dans RStudio
Cliquez pour lancer ou exécutez dans RStudio BioDataScience2::run_app("B01Sa_reglin").
Nous pouvons nous demander si notre modèle 2 qui est la meilleure droite de nos quatre modèles est le meilleur modèle possible dans l’absolu. Pour ce faire, nous allons devoir définir une technique d’optimisation qui nous permet de déterminer quelle est la droite qui minimise notre fonction objective. Dans la suite, nous garderons le critère des moindres carrés (des résidus) comme fonction objective.
Imaginons que nous n’avons pas quatre mais 5000 modèles linéaires avec des pentes et des ordonnées à l’origine différentes. Quelle est la meilleure droite ?
set.seed(34643)
models1 <- tibble(
intercept = runif(5000, -5, 4),
slope = runif(5000, -5, 15))
chart(data = trees, volume ~ diameter) +
geom_point() +
geom_abline(aes(intercept = intercept, slope = slope),
data = models1, alpha = 1/6) 
Nous voyons sur le graphique qu’un grand nombre de droites différentes sont testées, mais nous ne distinguons pas grand chose de plus. Cependant, sur ces 5000 modèles, nous pouvons maintenant calculer la somme des carrés des résidus et ensuite déterminer quel est le meilleur d’entre eux.
# Fonction de calcul de la somme des carrés des résidus (fonction objective)
f_obj <- function(slope, intercept, x, y) {
ybar <- x * slope + intercept
resid <- y - ybar
sum(resid^2)
}
# Test de la fonction
#f_obj(slope = 0, intercept = 0.85, x = trees$diameter, y = trees$volume)
# Fonction adaptée pour être employé avec purrr:map() pour distribuer le calcul
# qui distribue le calcul sur tous nos modèles
f_obj_trees <- function(intercept, slope) {
f_obj(slope = slope, intercept = intercept,
x = trees$diameter, y = trees$volume)
}
models1 <- models1 %>%
mutate(fobj = purrr::map2_dbl(intercept, slope, f_obj_trees))Si nous réalisons un graphique de valeurs de pentes, d’ordonnées à l’origine et de la valeur de la fonction objective en couleur, nous obtenons le graphique suivant :
plot <- chart(data = models1, slope ~ intercept %col=% fobj) +
geom_point() +
geom_point(data = filter(models1, rank(fobj) <= 10),
shape = 1, color = 'red', size = 3) +
labs( y = "Pente", x = "Ordonnée à l'origine", color = "F(obj)") +
scale_color_viridis_c(direction = -1)
plotly::ggplotly(plot)Les dix valeurs les plus faibles sont mises en évidence sur le graphique par des cercles rouges. Le modèle optimal que nous recherchons se trouve dans cette région.
Nous pouvons afficher les 10 meilleurs modèles sur notre graphique :
chart(data = trees, volume ~ diameter) +
geom_abline(data = best_models,
aes(slope = slope, intercept = intercept, color = fobj), alpha = 3/4) +
geom_point() +
labs(color = "F(obj)") +
scale_color_viridis_c(direction = -1)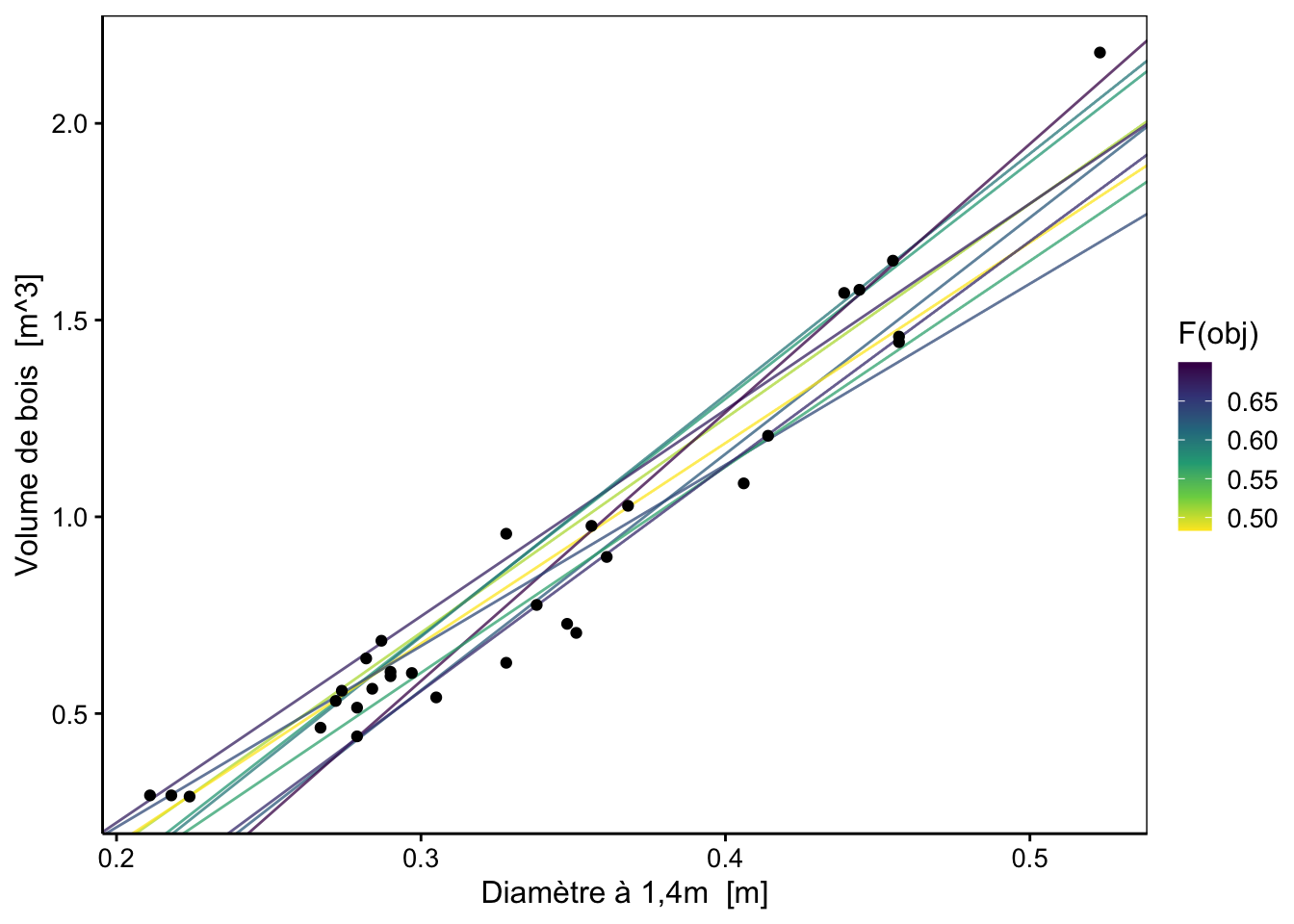
En résumé, nous avons maintenant une fonction objective qui quantifie la “distance globale” de la droite à tous nos points. La meilleure droite est celle qui minimise cette fonction objective. Il nous manque encore une technique pour trouver rapidement et efficacement la droite qui répond à ce critère.
Dans le cas particulier de la régression linéaire par les moindres carrés, les mathématiciens nous expliquent que la solution à notre problème s’obtient très facilement par un simple calcul. En effet, les paramètres \(a\) et \(b\) de la droite que nous recherchons sont directement calculables comme suit :
\[a = \frac{cov_{x, y}}{var_x} \ \ \ \textrm{et} \ \ \ b = \bar y - a \ \bar x\]
où \(\bar x\) et \(\bar y\) sont les moyennes pour les deux variables \(x\) et \(y\), \(cov\) est la covariance et \(var\) est la variance.
Dans R, vous vous doutez bien que nous n’allons pas refaire tous ces calculs à chaque fois que nous voulons ajuster une droite dans un nuage de points. La fonction lm() réalise, en effet, ce calcul pour nous.
..., ensuite choisissez models, ensuite models : linear et sélectionnez le snippet qui vous convient dans la liste.
En utilisant les snippets, et en remplaçant les valeurs par rapport au contexte, nous obtenons le code suivant que nous exécutons :
#
# Call:
# lm(formula = volume ~ diameter, data = trees)
#
# Coefficients:
# (Intercept) diameter
# -1.047 5.652Nous pouvons reporter ces valeurs sur notre graphique afin d’observer ce résultat par rapport à nos modèles choisis au hasard. Nous avons en rouge la droite calculée par la fonction lm().
chart(data = trees, volume ~ diameter) +
geom_abline(data = best_models,
aes(slope = slope, intercept = intercept, color = fobj), alpha = 3/4) +
geom_point() +
geom_abline(
aes(intercept = lm.$coefficients[1], slope = lm.$coefficients[2]),
color = "red", size = 1.5) +
labs( color = "F(obj)") +
scale_color_viridis_c(direction = -1)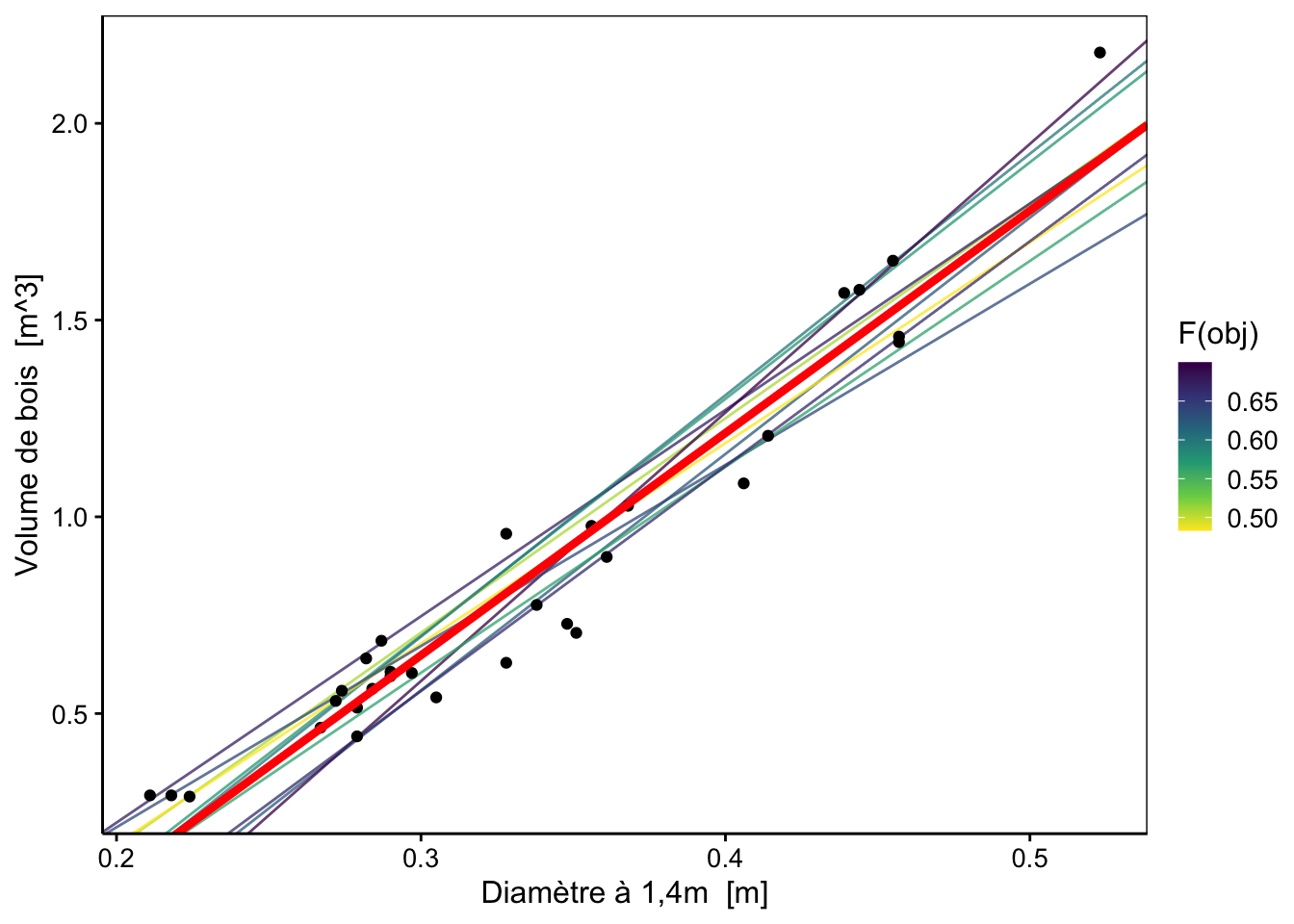
1.2.2 La fonction lm()
Suite à notre découverte de manière intuitive de la régression linéaire simple, nous pouvons récapituler quelques points clés :
- Une droite suit l’équation mathématique suivante :
\[y = a \ x + b\] dont \(a\) est la pente (slope en anglais) et \(b\) est l’ordonnée à l’origine (intercept en anglais), tous deux les paramètres du modèle, alors que \(x\) et \(y\) en sont les variables.
- La distance entre une valeur observée \(y_i\) et une valeur prédite \(\hat y_i\) se nomme le résidu (\(\epsilon_i\)) et se mesure toujours parallèlement à l’axe \(y\). Cela revient à considérer que toute l’erreur du modèle se situe sur \(y\) et non sur \(x\). Cela donne l’équation complète de notre modèle statistique :
\[y_i = a \ x_i + b + \epsilon_i\]
avec \(y_i\) est la valeur mesurée pour le point i sur l’axe y, \(a\) est la pente, \(x_i\) est la valeur mesurée pour le point i sur l’axe x, \(b\) est l’ordonnée à l’origine et \(\epsilon_i\) est le résidu (partie non expliquée par le modèle). On peut montrer –nous ne le ferons pas ici pour limiter les développements mathématiques– que le choix des moindres carrés des résidus comme fonction objective revient à considérer que nos résidus suivent une distribution normale centrée autour de zéro et avec un écart type \(\sigma\) constant/ :
\[\epsilon_i \approx N(0, \sigma)\]
Dans le cas de la régression linéaire simple, la meilleure droite s’obtient très facilement. En effet, la pente \(a = \frac{cov_{x, y}}{var_x}\) et l’ordonnée à l’origine \(b = \bar y - a \ \bar x\).
La fonction
lm()permet de faire ce calcul rapidement dans R.
# Régression linéaire
lm. <- lm(data = trees, volume ~ diameter)
# Graphique de nos observations et de la droite obtenue avec la fonction lm()
chart(data = trees, volume ~ diameter) +
geom_point() +
geom_abline(
aes(intercept = lm.$coefficients[1], slope = lm.$coefficients[2]),
color = "red", size = 1) +
labs( color = "Modèle") +
scale_color_viridis_c(direction = -1)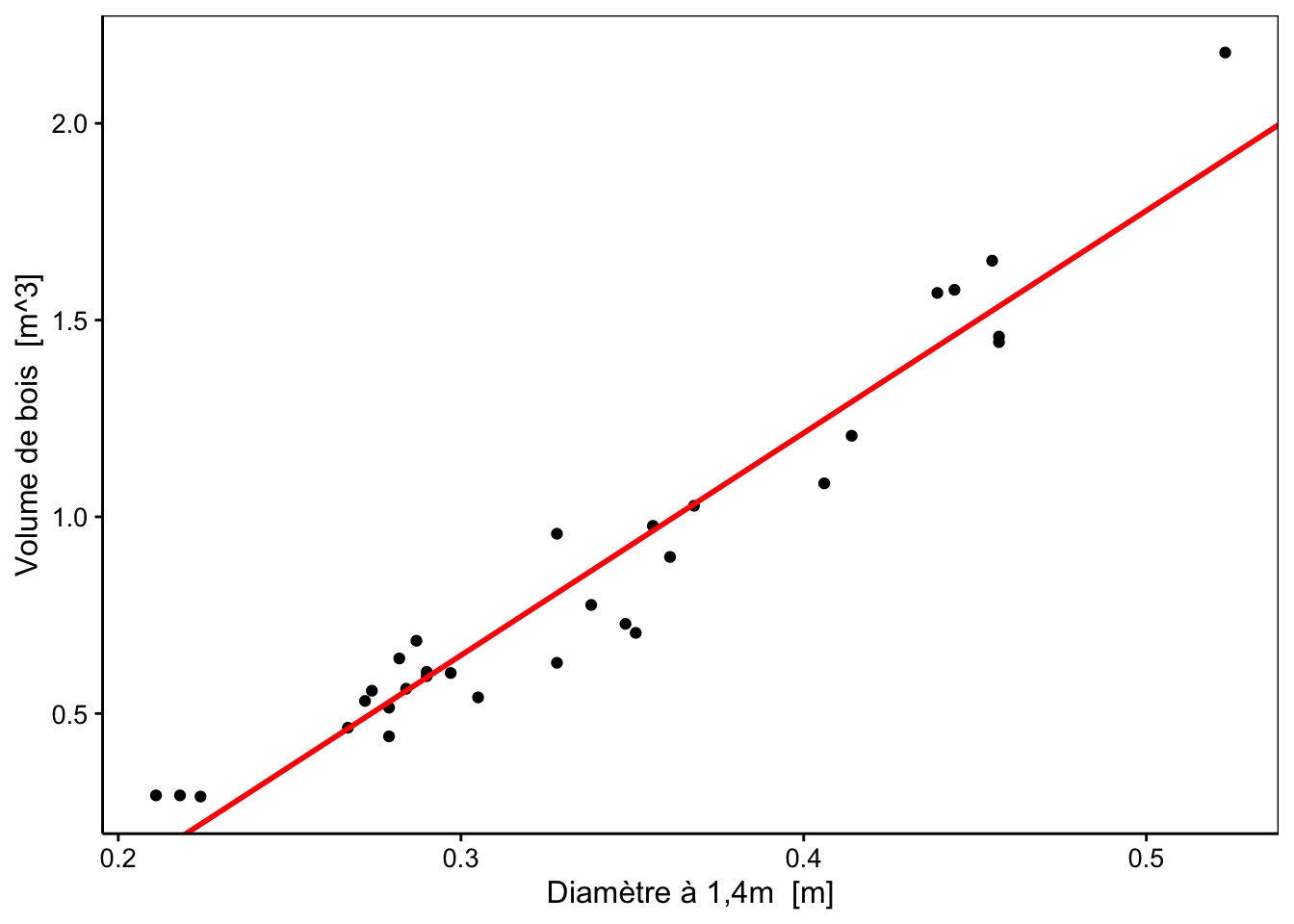
La fonction lm() crée un objet spécifique qui contient de nombreuses informations pour pouvoir ensuite analyser notre modèle linéaire. Afin de déterminer de quel objet il s’agit, vous pouvez utiliser class(). Ainsi, nous voyons que lm. est un objet de classe lm :
# [1] "lm"Pour la régression par les moindres carrés (des résidus), le fait de considérer que toute l’erreur porte sur la variable dépendante Y est une décision importante qui a de nombreuses conséquences. Outre un calcul simplifié de la meilleure droite et des contraintes sur la distribution des résidus (qui doit être Normale), nous avons également une asymétrie qui apparait entre les deux variables X et Y.
Ainsi, la régression \(y = a \cdot x + b\) ne correspond pas à la même droite que \(x = a' \cdot y + b'\). En effet, dans le premier cas, l’erreur est entièrement reportée sur Y tandis que dans le second cas, elle est entièrement reportée sur X. C’est pour cela qu’on distingue la variable réponse ou dépendante à la gauche de l’équation de la variable explicative ou indépendante à sa droite.
Décider quel variable est réponse dans l’équation n’est donc pas anodin. Utilisez les critères suivants :
- Si une des deux variables contient beaucoup plus d’erreur et/ou de variabilité inter-individuelle, placez-là à la gauche de l’équation comme variable réponse. En effet, votre modèle sera plus en adéquation avec la réalité, puisque dans le modèle toute l’erreur porte sur cette variable.
- Si une des deux variables est fixée dans une expérience. Par exemple, vous faites grandir différents lots de plantes à des intensités lumineuses différentes, alors la variable intensité lumineuse sera plutôt variable explicative à la droite de l’équation et la mesure de la croissance de vos plantes sera variable réponse dans le terme de gauche.
- Si une variable devra être prédite ultérieurement (quelle sera la croissance de mes plantes pour telle ou telle illumination, dans notre exemple précédent), cette variable à prédire sera plus facile à traiter si elle est variable réponse à la gauche de l’équation.
1.2.3 Résumé avec summary()
Avec summary() nous obtenons un résumé condensé des informations les plus utiles pour chaque objet dans R. Dans le cas de l’objet lm, l’information renvoyée est très utile pour interpréter notre régression linéaire.
#
# Call:
# lm(formula = volume ~ diameter, data = trees)
#
# Residuals:
# Min 1Q Median 3Q Max
# -0.231211 -0.087021 0.003533 0.100594 0.271725
#
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) -1.04748 0.09553 -10.96 7.85e-12 ***
# diameter 5.65154 0.27649 20.44 < 2e-16 ***
# ---
# Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#
# Residual standard error: 0.1206 on 29 degrees of freedom
# Multiple R-squared: 0.9351, Adjusted R-squared: 0.9329
# F-statistic: 417.8 on 1 and 29 DF, p-value: < 2.2e-16- Call :
Il s’agit de la formule employée dans la fonction lm(). C’est à dire le volume en fonction du diamètre du jeu de données trees.
- Residuals :
La tableau nous fournit un résumé via les cinq nombres de l’ensemble des résidus (que vous pouvez récupérer à partir de residuals(lm.)).
# 20 7 12 9 31
# -0.231210947 -0.087020695 0.003532709 0.100594122 0.271724973- Coefficients :
Il s’agit des résultats associés à la pente et à l’ordonnée à l’origine dont les valeurs estimées des paramètres (Estimate). Les mêmes valeurs peuvent être obtenues à partir de coef(lm.) :
# (Intercept) diameter
# -1.047478 5.651535Nous retrouvons également les écart-types calculés sur ces valeurs (Std.Error) qui donnent une indication de la précision de leur estimation, les valeurs des distributions de Student sur ces estimations (t value) et enfin les valeurs p (PR(>|t|)) liées à un test de Student pour déterminer si le paramètre p correspondant est significativement différent de zéro (avec \(H_0: p = 0\) et \(H_a: p \neq 0\)).
Pour l’instant, nous nous contenterons d’interpréter et d’utiliser les informations issues de summary() dans sa partie supérieure. Le contenu des trois dernières lignes sera détaillé dans le module suivant.
À vous de jouer !
A partir des données de ce résumé, nous pouvons maintenant paramétrer l’équation de notre modèle :
\[y = a \cdot x + b\]
devient3 :
\[volume \ de \ bois = 5.65 \cdot diamètre \ à \ 1.4 \ m - 1.05\]